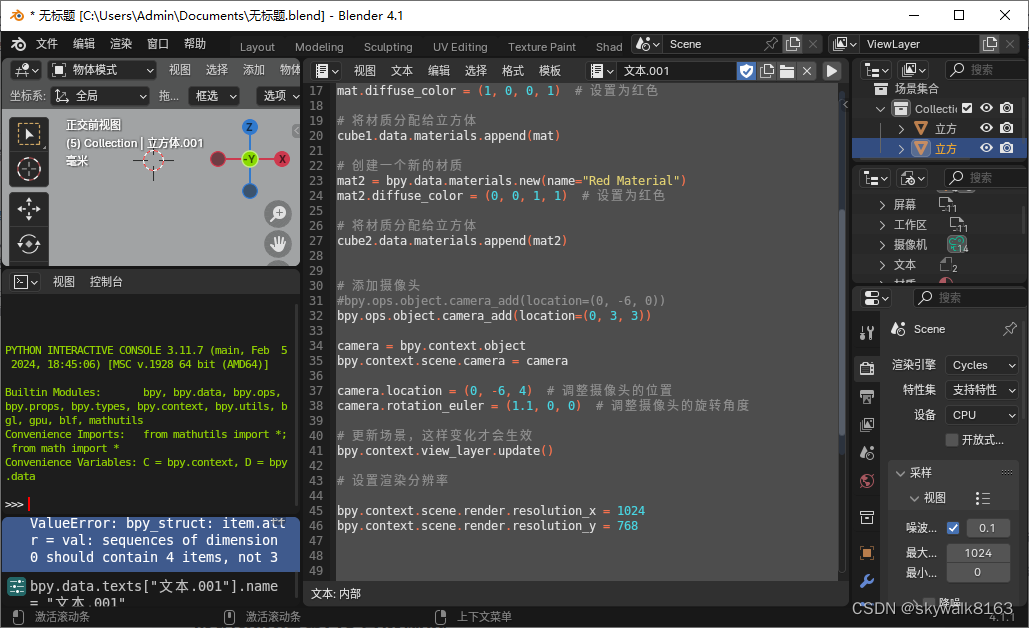
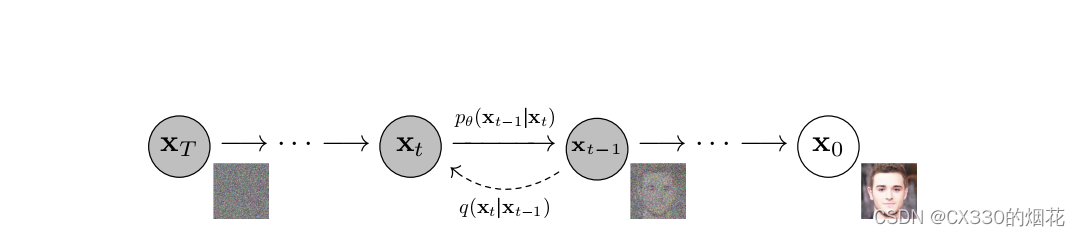
方案1
假设steps是100,
目标减去输入是总差异
训练的时候,输入就是图像 差异就目标减去输入,每步的差异(高斯噪声)是最大目标减去差异除以steps,
每次训练时把把目标减去每步差异,用unet去预测差异
预测的时候,输入图像,然后加上时间t,unet预测这个差异,然后加上这个差异,通过每次预测差异,然后就生成出了我们要的图像。
方案2
每步的差异(高斯噪声)是每个目标减去自己的输入差异除以steps。
方案1
假设steps是100,
目标减去输入是总差异
训练的时候,输入就是图像 差异就目标减去输入,每步的差异(高斯噪声)是最大目标减去差异除以steps,
每次训练时把把目标减去每步差异,用unet去预测差异
预测的时候,输入图像,然后加上时间t,unet预测这个差异,然后加上这个差异,通过每次预测差异,然后就生成出了我们要的图像。
方案2
每步的差异(高斯噪声)是每个目标减去自己的输入差异除以steps。






















![[Cesium for Supermap]加载iserver发布的wms服务](https://img-blog.csdnimg.cn/direct/d2950f3f7add4b5798ab73980dcc021c.png)