顺序表和链表之间各有优劣,我们不能以偏概全,所以我们在使用时要关注任务的注重点,以此来确定我们要使用两者中的哪一个。
不同点:
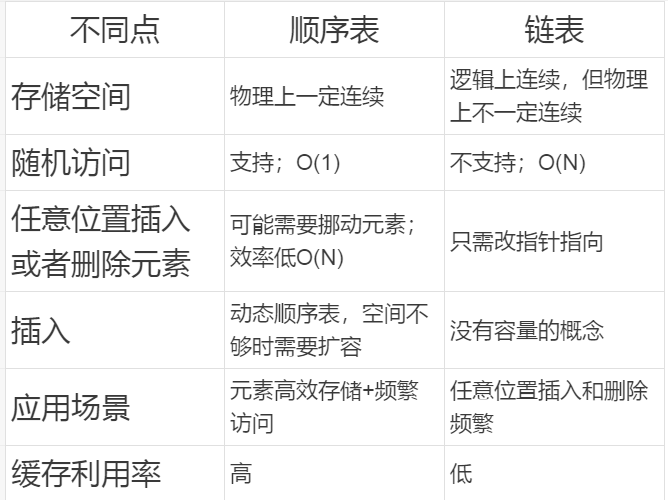
存储空间上:
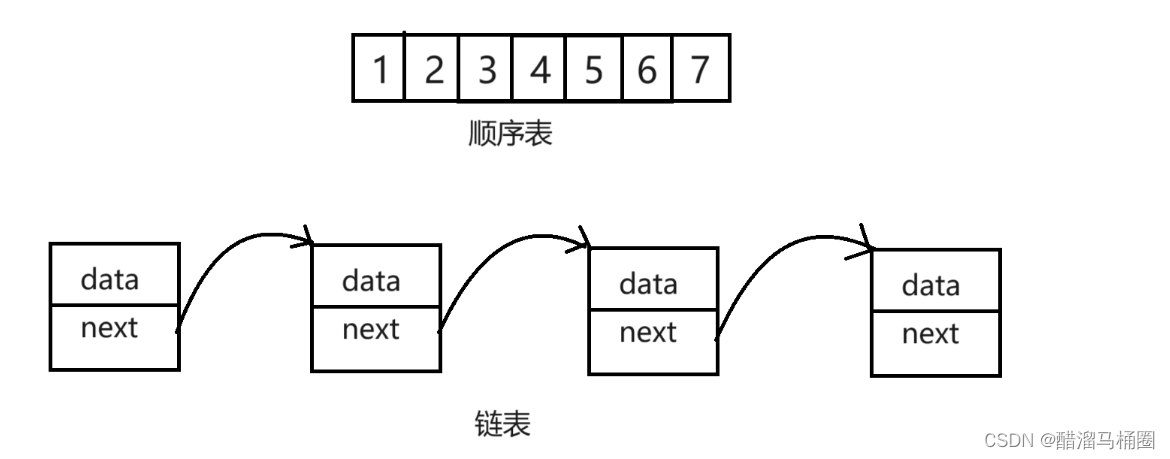
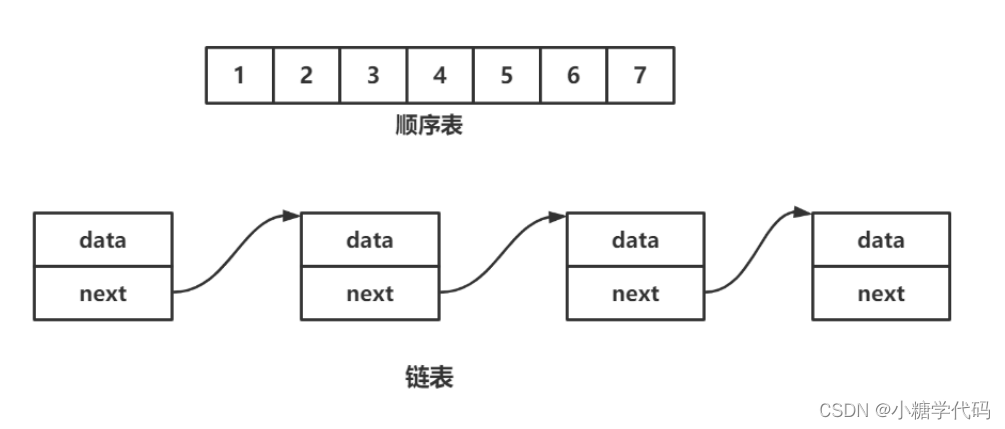
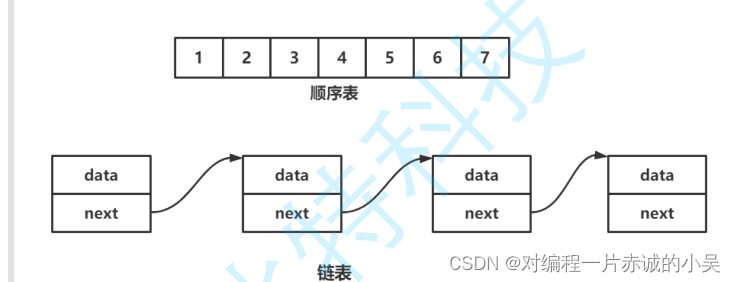
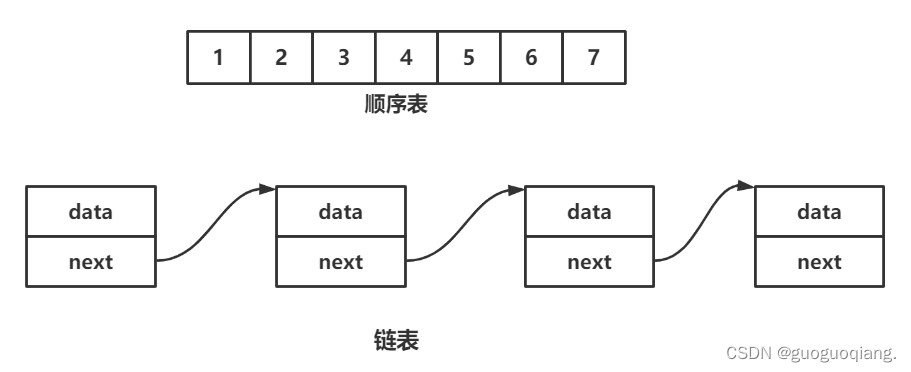
顺序表在物理结构上是一定连续的,而链表(这里以带头双向循环链表为主)在逻辑结构上连续,但在物理结构上不一定连续。
随机访问元素(下标)的时间复杂度:
顺序表支持且为O(1),链表不支持,所以为O(n)。
任意位置插入或删除元素的时间复杂度:
顺序表可能需要移动元素,所以效率较低,时间复杂度为O(n);链表只需要修改指针的指向即可,时间复杂度为O(1)。
扩容:
动态顺序表的空间不够时需要扩容,使用的realloc函数,其扩容分为原地扩容和异地扩容,本身就会有消耗,效率低下,且存在空间浪费。链表中没有容量的概念,每一个节点都是按需申请释放,因此效率较高。
应用场景:
顺序表大多应用于元素的高效存储+频繁访问;链表大多应用于任意位置频繁的插入和删除。
缓存利用率:
顺序表高,链表低。
我们再介绍一下缓存利用率:
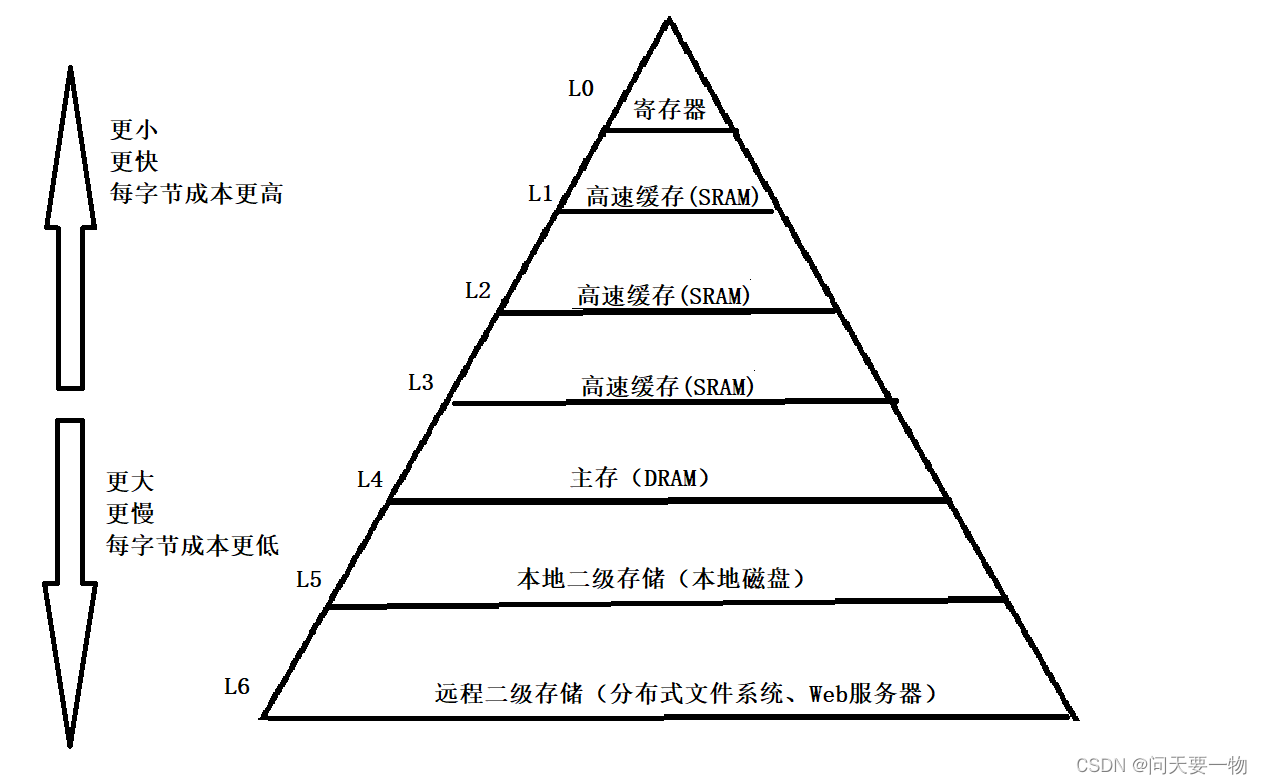
主存即内存,磁盘即硬盘。两者的差异是,内存为带电存储,速度快;硬盘的速度慢,但是可以不带电存储。远程二级存储其实就是我们经常用的网盘。我们的存储空间大概就分为这7层,第一层为寄存器,保存着L1高速缓存存储器中取出的数据,L1高速缓存中保存着从L2高速缓存中取出的缓存行,下同。在我们电脑使用的空间小时,我们可以直接使用寄存器处理,如果数据慢慢变多,我们就会用到更大的存储器,在寄存器有空闲时,下一层的的存储器会向上一层的缓存行中输出,保证计算机空间的有序和利用效率。
在正常情况下,计算机会将部分数据先加载缓存,如果在缓存(称为缓存命中),会直接访问;如果不在缓存(称为缓存不命中),要先把部分数据从内存加载到缓存,再访问。
我们知道顺序表在内存空间中的存储是连续的,这就会提高缓存的利用率。而链表在内存空间中的存储不一定连续,这会导致缓存区中会有很多无效数据,使缓存利用率降低。


























![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.4讲 GPIO中断实验-IRQ中断服务函数详解](https://img-blog.csdnimg.cn/direct/0e086a82394b481bb2c90d69163157ee.png)

![[redis] 说一说 redis 的底层数据结构](https://img-blog.csdnimg.cn/img_convert/8bb110112f61227de0ebf93810f4c5c1.png)