0. 简介
本文介绍了基于激光雷达的4D占用补全与预测。场景补全与预测是自动驾驶汽车等移动智能体研究中的两个常见的感知问题。现有的方法独立地处理这两个问题,导致这两方面的感知是分开的。在《LiDAR-based 4D Occupancy Completion and Forecasting》中,我们在自动驾驶的背景下引入了一种新型的激光雷达感知任务,即占用补全与预测(OCF),以将这两方面统一到一个整体的框架中。这项任务需要新的算法来解决总共三项挑战:(1)稀疏到稠密重建;(2)部分到完整补全;(3)3D到4D预测。为了能够进行监督和评估,我们根据公开的自动驾驶数据集创建了一个大规模数据集,称为OCFBench。我们在数据集上分析了密切相关的现有基线模型和自己模型的性能。我们展望,本研究将激励并且呼吁在4D感知这一不断发展的重要领域内进行进一步研究。相关的代码已经在Github开源了。
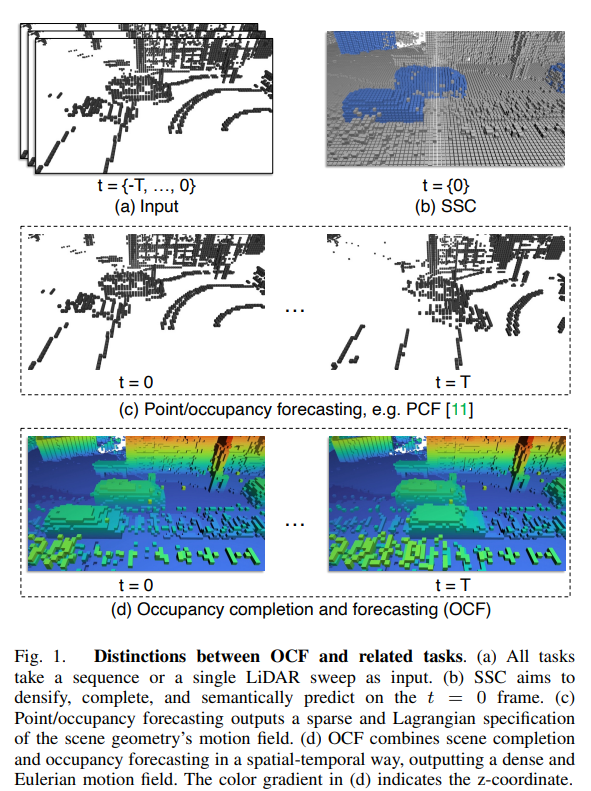
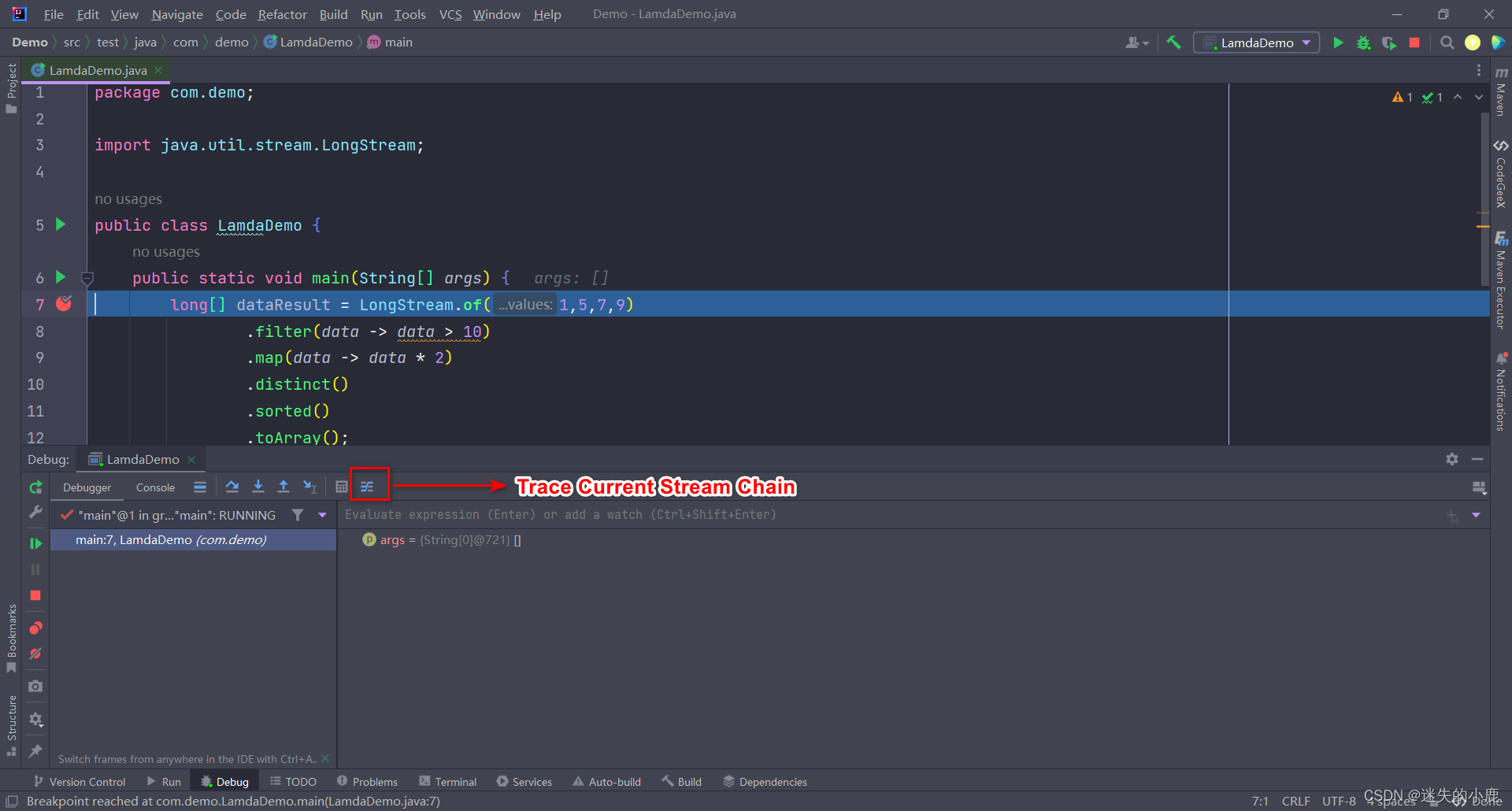
图1. OCF与相关任务的区别。(a) 所有任务都以序列或单个LiDAR扫描作为输入。(b) SSC旨在在t = 0帧上进行稠密化、完整化和语义预测。(c) 点/占据预测输出场景几何运动场的稀疏和拉格朗日规范。(d) OCF以时空方式结合场景完整化和占据预测,输出密集的欧拉运动场。(d)中的颜色渐变表示z坐标。
1. 主要贡献
本文的贡献总结如下:
1)本文提出了占用补全与预测任务,其要求从稀疏的3D输入中获取空间-时间稠密的4D感知结果;
2)本文利用公开自动驾驶数据生成了一个大规模数据集,称为OCFBench;
3)本文提出了基线方法来处理OCF任务,并且基于本文数据集提供了一个详细的基准。
2. 具体方法
2.1 问题表述
我们的目标是在给定点云输入的情况下,完成并预测表示为空间-时间范围内的场景,即占据栅格。具体而言,如图2所示,我们将输入表示为连续的点云序列,表示为体素栅格 P = { P t } t = − T 0 P = \{P_t\}^0_{t=−T} P={Pt}t=−T0。期望的输出是一系列完成的体素栅格 Y = { Y t } t = 0 T Y = \{Y_t\}^T_{t=0} Y={Yt}t=0T。每个输入和输出帧都是具有固定尺寸和相同坐标系的体素栅格,即 P t P_t Pt, Y t ∈ { 0 , 1 } H × W × L Y_t ∈ \{0, 1\}^{H×W×L} Yt∈{0,1}H×W×L,其中二进制值0和1表示每个体素是否为空闲或占据。这里, T T T表示输入/输出序列的帧数,而 H H H、 W W W和 L L L分别表示体素栅格的高度、宽度和长度维度。在深度学习的背景下,我们的目标是训练一个神经网络 f θ f_θ fθ,尽可能地预测 Y ~ = f θ ( P ) \tilde{Y} = f_θ(P) Y~=fθ(P)与真实值 Y Y Y接近。
值得注意的是,这个表述与现有的点云/占据预测文献不同之处在于OCF需要预测复杂的稠密体素栅格。从统计上讲,完成的体素栅格几乎比稀疏的体素栅格多出18倍。如图1所示,这个更具挑战性的任务旨在提供对环境的全面表示,同时减轻传感器内外参数的影响。这种对环境的欧拉规范强调了对更高效和更稳健的感知的需求。
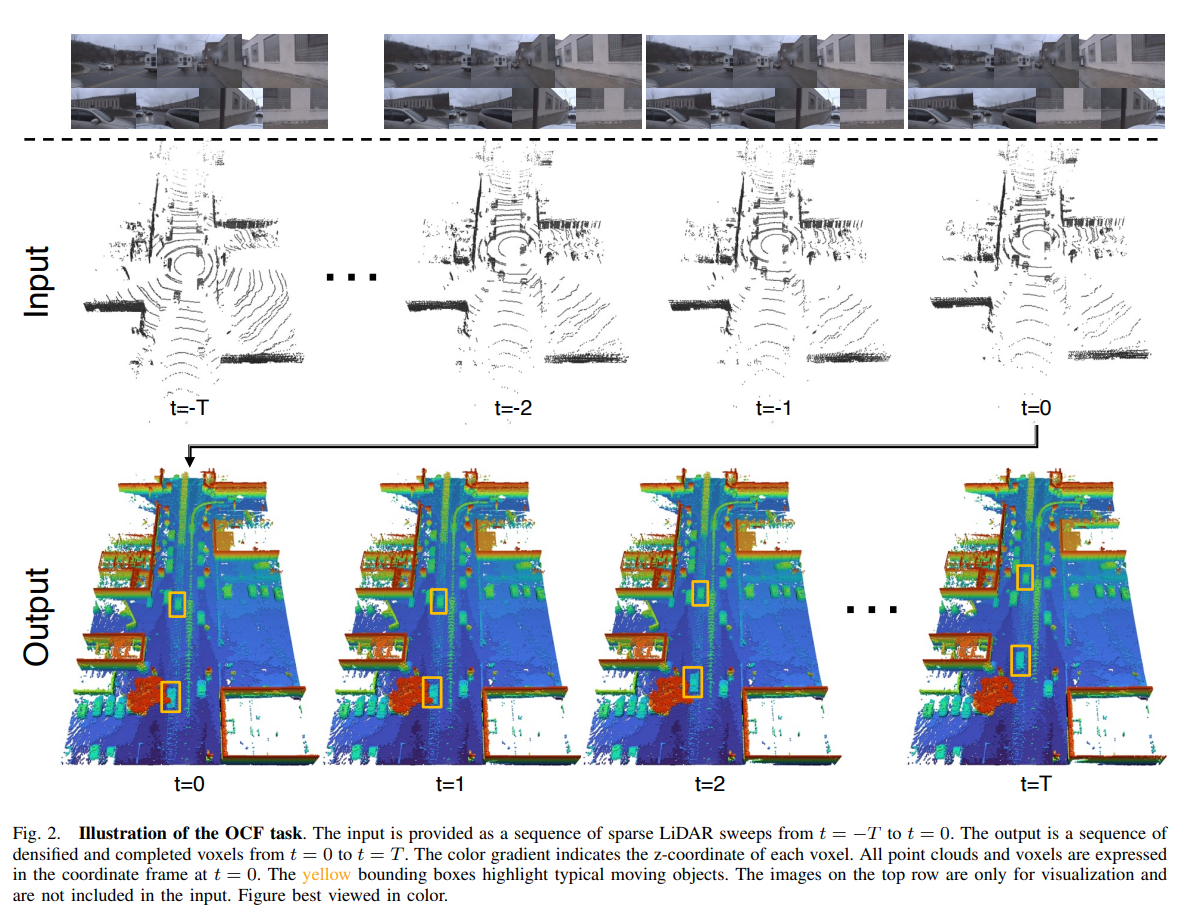
图2. OCF任务的示意图。输入以从 t = − T t = -T t=−T到 t = 0 t = 0 t=0的稀疏LiDAR扫描序列的形式提供。输出是从 t = 0 t = 0 t=0到 t = T t = T t=T的稠密和完整的体素序列。颜色渐变表示每个体素的z坐标。所有点云和体素都以 t = 0 t = 0 t=0的坐标框架表示。黄色边界框突出显示了典型的移动物体。顶部行的图像仅用于可视化,不包含在输入中。最佳观看效果请查看彩色图。
2.2 基础算法
2.2.1PCF
我们从[11]中提出的结构中得出这个基准线,该结构是从[10]和[53]中改编而来的。我们省略了深度渲染模块,以使其与OCF问题兼容。该模型具有简单的基于卷积的编码器-解码器结构。[11]中使用的一种技术是将张量重塑并将时间维度连接到高度上,从而将4D体素张量适应于2D卷积层。请注意,我们的改编是根据OCF问题的表述进行的,利用了前面提到的损失函数。因此,它与[11]中的原始模型不能直接进行比较。
2.2.2 ConvLSTM
这是一种广泛应用于序列结构化数据的模型结构,由[18]提出,并在视频感知、预测、预测和生成等领域有着众多应用。该模型结构通过用卷积层替换LSTM模块中的线性层,将卷积神经网络和循环神经网络的优势结合起来。在我们的实现中,我们使用基本结构中的卷积块,但去除了连接步骤。我们为所有输入帧使用共享的2D卷积编码器,并将时间特征递归地馈送到LSTM模块中。
2.2.3 3D卷积
将时间维度与高度维度连接起来并不直观,因为它无法利用3D输入中的归纳偏差,并且会使模型对每个时间帧之间的关系产生困惑。相反,处理3D结构化数据的一种更直观的方法是使用3D卷积层[19]。我们通过用3D卷积层替换基本结构中的2D卷积层来实现这个结构。虽然这意味着更大的内存占用,但我们的实验证明训练过程能够适应单个GPU。
2.3 损失函数
2.3.1 BCE损失
由于每个体素的真实值为0/1(表示自由或占用),我们将训练视为每个体素的二分类任务。因此,我们采用二元交叉熵(BCE)损失进行模型训练。在批量训练过程中,损失值在每个帧上进行平均。
2.3.2 Soft-IoU损失
Soft-IoU最初在[54]中引入,主要用作评估模型预测置信度的指标。作为副作用,该指标的软性使其可微分,并可用作损失函数。所提出的损失函数为:
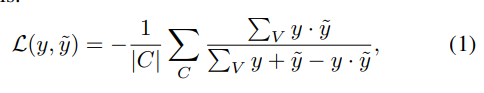
其中 C C C是小批量, V V V是一个样本中的体素集合, y y y是以 { 0 , 1 } \{0, 1\} {0,1}表示的真实占据情况, y ~ \tilde{y} y~是每个体素的预测占据概率。需要注意的是,这个损失函数不仅融合了IoU的概念,还使模型能够更自信地进行预测。在我们的实验中,我们使用BCE和soft-IoU损失的总和来训练3D卷积模型。
3. 数据整理
3.1 处理挑战和技术
3.1.1 概述
阻碍基于占用的感知发展的关键障碍之一是在现实世界中捕获真实占用的困难。虽然激光雷达传感器能够为扫描点提供准确的占用信息,但是密度与成本之间的权衡使得无法获得环境中所有物体和结构的密集占用。此外,由于传感器依赖于光探测和测距,遮挡造成了额外的挑战,特别是在自动驾驶场景中,大量动态物体导致大面积的遮挡。之前的研究[6],[16],[17]提出了一些解决这些挑战的方法。我们在下面的段落中回顾了其中一些方法,并引入了新的方法。