模型装配、训练与评估全流程实战
在深度学习的实践过程中,模型的装配、训练与评估是至关重要的三个环节,它们共同构成了一个完整的机器学习项目周期。本文将通过实战的方式,基于Keras这一高层API,详细介绍模型的创建、训练以及评估的全过程,确保读者能够掌握从零开始构建深度学习模型的技能。
1. 模型装配:Keras的高效构建工具
Keras通过高度模块化的API,让模型装配变得简单直观。首先,你需要定义模型的架构,这是通过叠加不同的层(Layer)来实现的。以一个简单的多层全连接网络(MLP)为例,用于MNIST手写数字识别任务:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, ReLU
# 创建Sequential模型
model = Sequential(name="mlp_mnist")
# 添加隐藏层,使用ReLU激活函数
model.add(Dense(256, input_shape=(28 * 28,), activation='relu', name='hidden1'))
model.add(Dense(128, activation='relu', name='hidden2'))
model.add(Dense(64, activation='relu', name='hidden3'))
model.add(Dense(32, activation='relu', name='hidden4'))
# 输出层,10分类问题,使用Softmax激活函数
model.add(Dense(10, activation='softmax', name='output'))
# 打印模型概述
model.summary()
2. 配置模型:编译步骤
在模型定义之后,需要通过compile方法配置训练过程,包括选择优化器、损失函数以及评估指标:
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import CategoricalCrossentropy
# 配置模型
model.compile(optimizer=Adam(learning_rate=0.001),
loss=CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
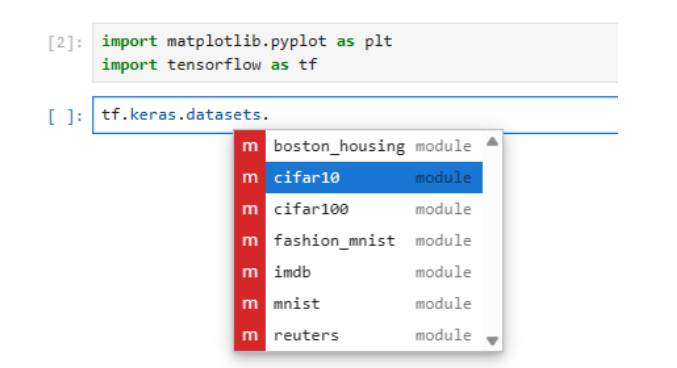
3. 数据准备:MNIST数据集加载
数据是深度学习的生命之血,Keras提供了方便的API来加载MNIST数据集:
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
4. 训练模型:fit函数
模型训练是通过fit函数完成的,它自动执行前向传播、计算损失、反向传播和权重更新:
history = model.fit(x_train, y_train,
epochs=10,
validation_data=(x_test, y_test),
batch_size=64)
5. 评估与可视化
训练结束后,可以使用evaluate方法来测试模型在测试集上的性能,并通过TensorBoard等工具可视化训练过程:
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f'\nTest accuracy: {test_acc}')
# 可视化代码略,一般涉及TensorBoard的使用,用于观察loss、accuracy等随epoch变化趋势
6. 模型保存与加载
训练好的模型可以保存,以便未来复用或部署:
model.save('mnist_mlp_model.h5')
加载模型同样简单:
from tensorflow.keras.models import load_model
model = load_model('mnist_mlp_model.h5')
结语
通过上述步骤,我们完整地走过了模型装配、训练、评估、保存与加载的全过程。Keras的高层API设计使得整个流程变得简单高效,降低了深度学习的门槛,让开发者能够专注于模型设计与问题解决。




















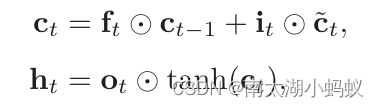




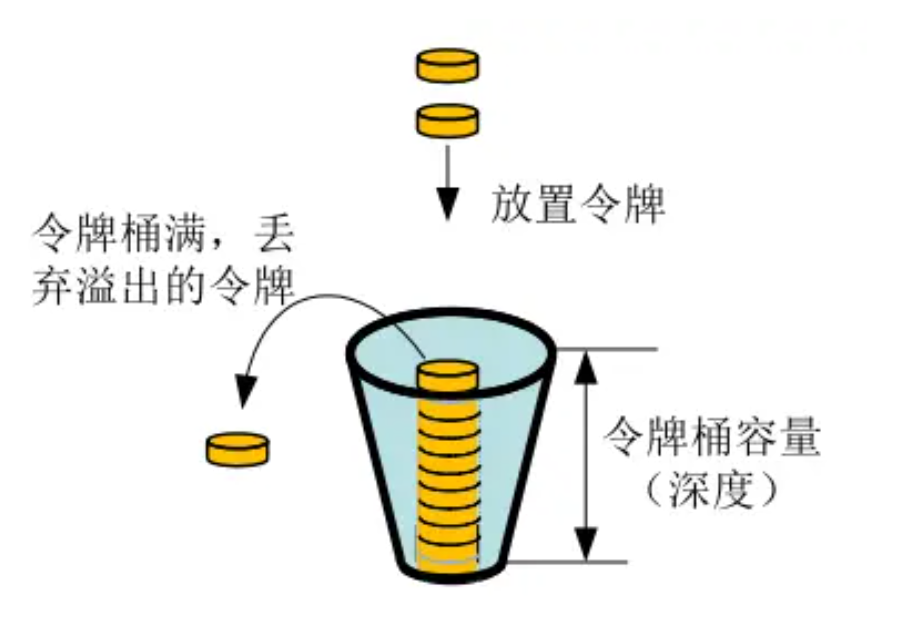

![61、内蒙古工业大学、内蒙科学技术研究院:CBAM-CNN用于SSVEP - BCI的分类方法[脑机二区还是好发的]](https://img-blog.csdnimg.cn/direct/2bc65a9d10a542f48b141cfe6a0530dd.png)



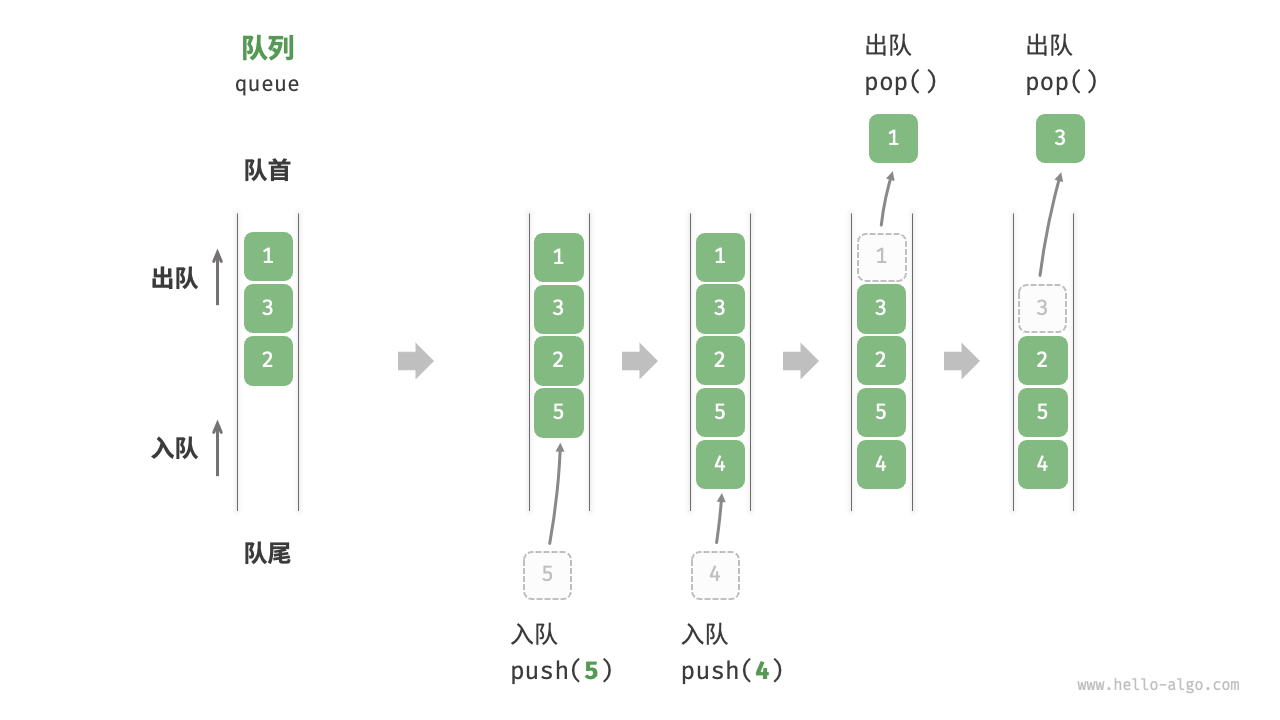
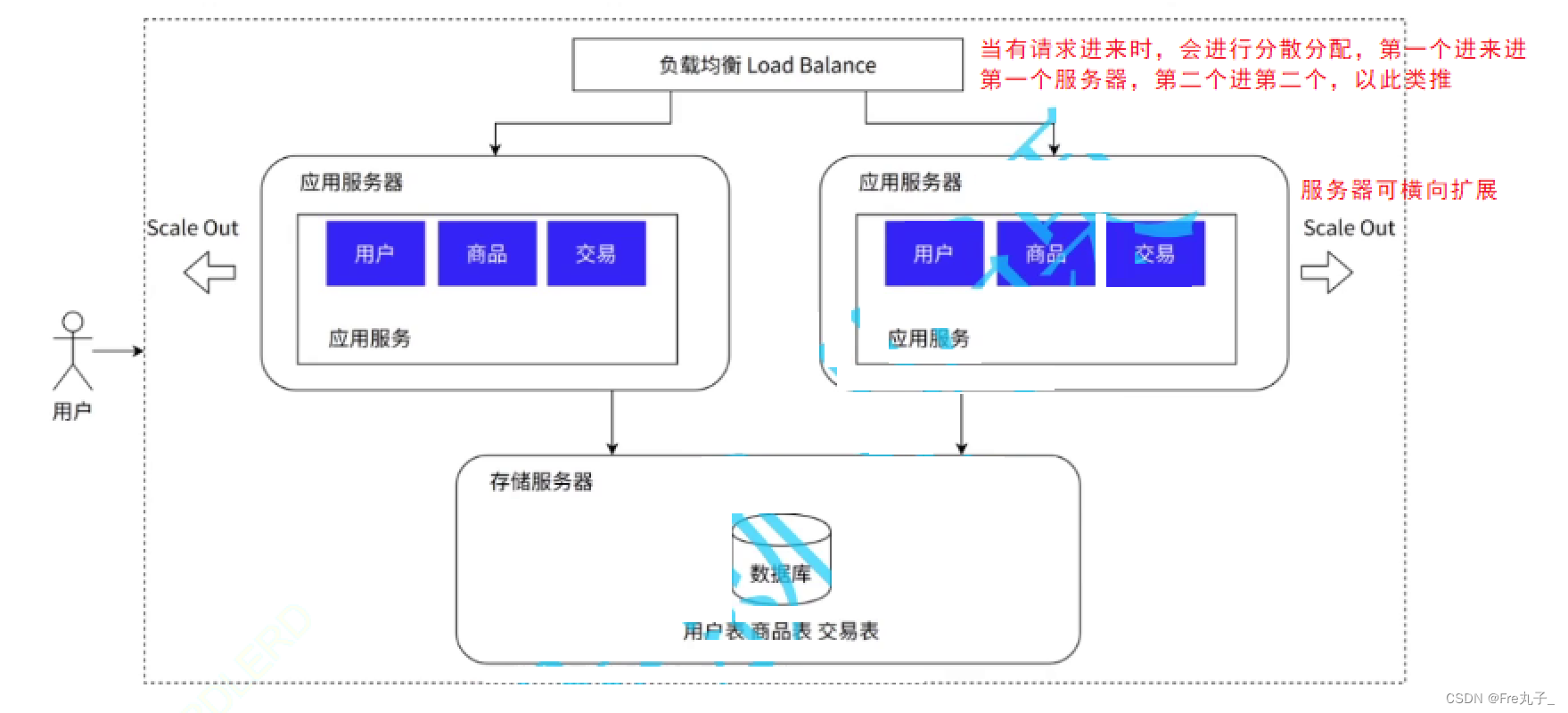



![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.1,2,3-GPIO中断控制实验](https://img-blog.csdnimg.cn/direct/d7578bcae69846e687fa107af1cb1916.png)