之前我们介绍了循环神经网络的原理以及实现。但是循环神经网络有一个问题,也就是长期依赖问题。我们之前的01序列预测案例中可以看到,当序列长度到达10以上之后错误就会增多,说明简单的RNN记忆容量较小,当长度更大时就不怎么适用了。本质上是由于随时间反向传播算法当序列长度太长后产生的梯度爆炸和梯度消失问题导致的。具体推导可以参见邱锡鹏的《神经网络与深度学习》6.5节。
从算法顺序来说是先有LSTM再有GRU的,不过由于LSTM比较复杂,且名气也更大,因此我们先来看一下LSTM(长短期记忆网络)。
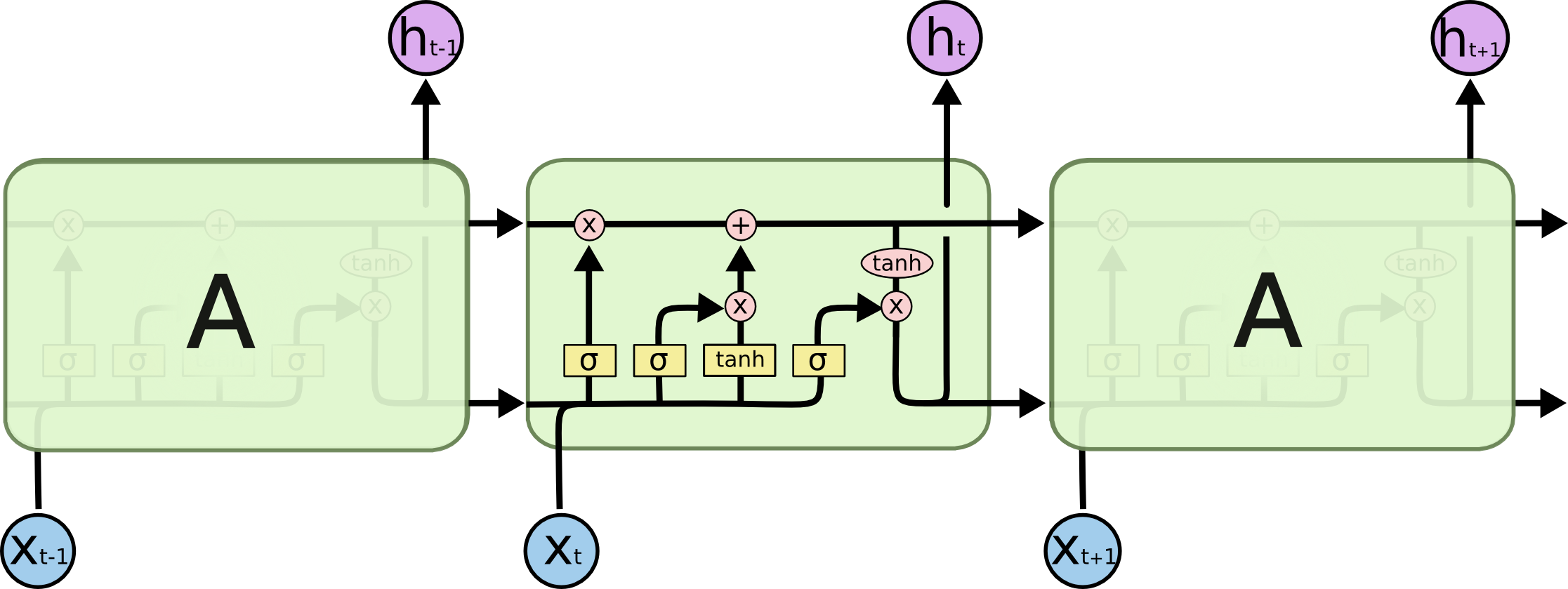
简单的来说,LSTM算法引入了三个门来解决这个问题,一个输入门input,一个遗忘门forget,一个输出门output。在每个时刻t,LSTM网络的内部状态ct记录了到当前时刻为止的历史信息。
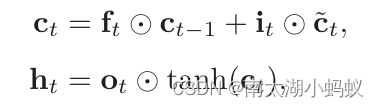
这里ft代表遗忘门,it代表输入门,ot代表输出门,ct代表上一个时刻的历史信息乘以遗忘门,决定是否要遗忘,再加上通过非线性函数得到的候选状态。
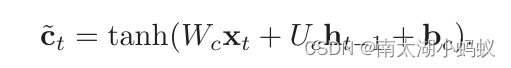
LSTM每个门取值都在(0,1)之间,ct在(-1,1)之间,候选状态也是在(-1,1)之间,ht也是在(-1,1)之间。
- 遗忘门ft控制上一个时刻的内部状态ct-1需要遗忘多少信息。
- 输入门it控制当前时刻的候选状态ct~多少信息需要保存。
- 输出门ot控制当前时刻的内部状态ct有多少信息需要输出给外部状态ht。
当ft=0,it=1时,记忆单元将历史信息清空,并将候选状态向量ct~写入,但此时记忆单元ct依然和上一时刻的历史信息相关,因为ct~的计算还是有ht-1参与的。当ft=1,it=0时,记忆单元将复制上一时刻的内容,不写入新的信息。
三个门的计算公式分别为:
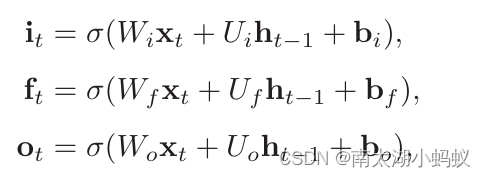
LSTM总体结构如下图所示:
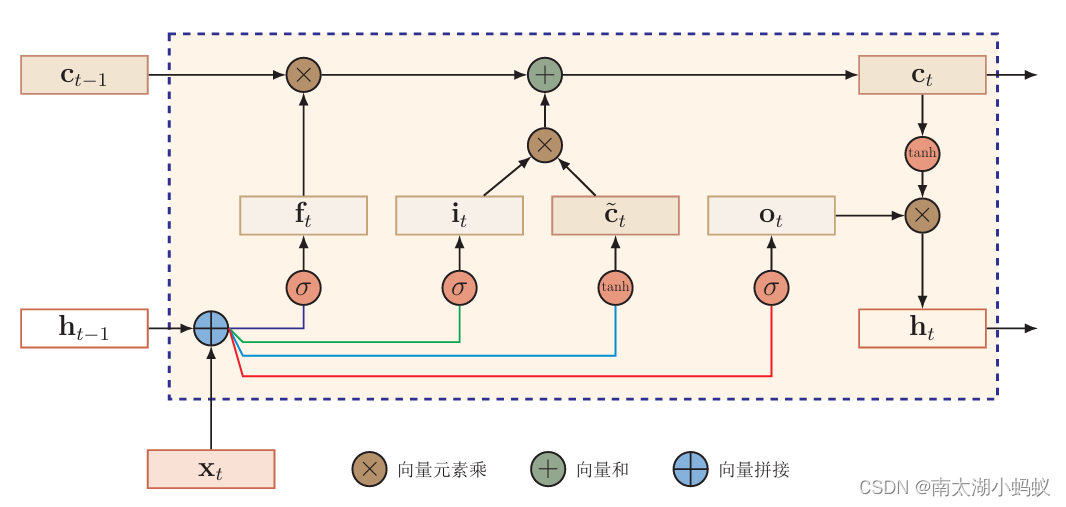
- 首先利用上一时刻的外部状态ht−1和当前时刻的输入xt,计算出三个门it,ft,ot,以及候选状态 ct~;
- 结合遗忘门ft和输入门it来更新记忆单元ct;
- 结合输出门ot,将内部状态的信息传递给外部状态ht。
循环神经网络中的隐状态h存储了历史信息,可以看作是一种“记忆”,在简单循环神经网络中,隐状态每个时刻都被会重写,可以看作是一种短期记忆。在神经网络中,网络参数可以看作是长期记忆,隐含了从训练数据中学到的经验,并且更新周期要远远慢于短期记忆。LSTM中的ct可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。ct中保存信息的生命周期要长于短期记忆h,又远远短于长期记忆,所以被称作是长短期记忆网络(LSTM)。
下面,我们来自己实现一下这个网络。
class LSTM(nn.Module):
def __init__(self, input_size, num_hiddens, batch_first=True):
super(LSTM,self).__init__()
def normal(shape):
return torch.randn(size = shape)*0.01
def three(): # 定义输入的权重,隐藏神经元的权重,截距的权重
wx = normal((input_size, num_hiddens))
wh = normal((num_hiddens, num_hiddens))
b = torch.zeros(num_hiddens)
return (wx,wh,b)
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # C,候选记忆参数
# 输出层参数
W_hq = normal((num_hiddens, num_hiddens))
b_q = torch.zeros(num_hiddens)
self.params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]
self.batch_first = batch_first
self.num_hiddens = num_hiddens
def forward(self,inputs):
# 获取各种预定义的权重
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = self.params
# 如果第一个维度是批量大小batch_size,则第二个维度是序列长度,否则第一个维度是序列长度
if self.batch_first:
batch_size = inputs.shape[0]
seq_len = inputs.shape[1] # 序列长度
else:
batch_size = inputs.shape[1]
seq_len = inputs.shape[0] # 序列长度
# 初始化状态state
self.h = torch.zeros((seq_len, self.num_hiddens))
self.c = torch.zeros((seq_len, self.num_hiddens))
H = self.h
C = self.c
outputs = []
for X in inputs: # 这里遍历的,其实就是批量batch,X就是一个批量的输入
# 输入门的计算
I = torch.sigmoid((X@W_xi) + (H@W_hi) + b_i)
# 遗忘门的计算
F = torch.sigmoid((X@W_xf) + (H@W_hf) + b_f)
# 输出门的计算
O = torch.sigmoid((X@W_xo) + (H@W_ho) + b_o)
# 候选状态的计算
C_tilda = torch.tanh((X@W_xc) + (H@W_hc) + b_c)
# 记忆单元的计算
C = F*C + I*C_tilda
# 输出的隐藏层权重
H = O*torch.tanh(C)
# 得到输出的结果
Y = H@W_hq + b_q
# 把每个批量的输出添加到数组outputs中
outputs.append(Y)
# 根据第0维进行拼接
out = torch.cat(outputs, dim=0)
# 恢复成输入的batch_size大小
out = out.reshape(batch_size,seq_len,self.num_hiddens)
return out,(H,C)# 我们构建一个输入维度位1,20个隐藏单元,默认一个隐藏层,输入的第一维度是batch_size
net = LSTM(input_size=1, num_hiddens=20, batch_first=True)
# 输入数据,第一维度是batch_size=8,第二个维度是序列长度,为10,第三个维度是input_size=1
data = torch.zeros(8,10,1)
out,ht = net(data)
print(out.shape)
print(out[:,-1,:].shape)
# 输出:
# 第一维度batch_size=10,第二维度是序列长度=10,第三维度是隐藏神经元的个数=20
torch.Size([8, 10, 20])
torch.Size([8, 20])我们可以用pytorch框架提供的LSTM模型和我们自己定义的LSTM对照一下:
input_size = 1
num_hiddens = 20
lstm=nn.LSTM(
input_size=input_size, #输入特征维度,当前特征为股价,维度为1
hidden_size=num_hiddens, #隐藏层神经元个数,或者也叫输出的维度
num_layers=1, # 隐藏层数量
batch_first=True
# 输入数据的第一维度是batch_size
)
data = torch.zeros(8, 10, 1)
out,ht = lstm(data)
print(out.shape)
print(out[:,-1,:].shape)
print(ht[0].shape)
print(ht[1].shape)
# 输出:
torch.Size([8, 10, 20])
torch.Size([8, 20])
torch.Size([1, 8, 20])
torch.Size([1, 8, 20])可以看到,pytorch框架提供的LSTM方法和我们自定义的LSTM方法的输出大小是一样的。下面我们可以根据LSTM的输出去做自己需要的事情,假设我们需要根据输入的序列数据,来预测序列数据的下一位,我们可以定义如下的神经网络模型:
class model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(model, self).__init__()
self.hidden_size = hidden_size
self.lstm = LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
#print("out.shape : ",out.shape)
return out可以看到,我们调用了LSTM模块,并把输出结果,再进行了一次线性全连接操作,得到了符合输出大小的结果。我们用一个数据来测试一下输出:
# 定义一个input_size=1,hidden_size=1,output_size=1的模型
net = model(1, 20, 1)
# 定义一个输入,batch_size=8,序列长度seq_len=4,input_size=1
data = torch.zeros(8, 4, 1)
out = net(data)
print(out.shape)
# 输出:
torch.Size([8, 1])可以看到输出的大小是[8,1],第0维是8,batch_size,输出就是一个数值,我们可以利用这个输出去跟标签对比,求得loss,就可以训练了。
下面,我们将之前《循环神经网络简介》一文中介绍的根据正弦函数的前四个输入来预测下一个输出值的案例来重新实现一下,改成用自定义的LSTM。
假设我们有一个预先定义的正弦函数数据:
import matplotlib.pyplot as plt
# 画出sin函数作为序列函数
y = []
for i in range(1000):
y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
x = [i for i in range(1000)]
plt.plot(x, y)
plt.show()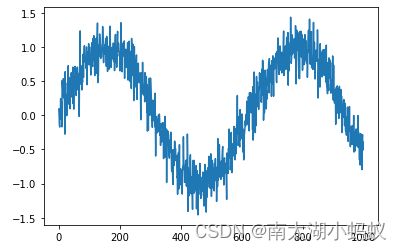
选择1000个样本,作为训练数据:
total = 1000
tau = 4
features = np.zeros((total-tau, tau))
data = [i for i in range(total)]
for i in range(tau):
features[:,i] = y[i:total-tau+i] # 获取到每一列的特征值
print(len(features)) # 样本个数
print(features) # 输出特征值定义数据集Dataset和DataLoader:
# 用前600个数字作为训练集,后400个作为测试集
class myDataset(Dataset):
def __init__(self, tau=4, total=600, transform=None):
data = [i for i in range(total)]
y = []
for i in range(total):
y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
# tau代表用多少个数字来作为输入,默认为4
self.features = np.zeros((total-tau, tau)) # 构建了996行4列的输入序列,代表了996个训练样本,每个样本有4个数字构成
for i in range(tau):
self.features[:,i] = y[i: total-tau+i] # 给特征向量赋值
self.data = data
self.transform = transform
self.labels = y[tau:]
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]transform = transforms.Compose([transforms.ToTensor()])
trainDataset = myDataset(transform=transform)
train_loader = DataLoader(dataset=trainDataset, batch_size=32, shuffle=False) 定义一个训练方法:
def train(epochs=1000):
net = model(1, 20, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
for epoch in range(epochs):
total_loss = 0.0
for i, (x, y) in enumerate(train_loader):
x = Variable(x)
x = x.to(torch.float32)
# unsqueeze是在最后增加一个维度,否则x的shape是[32,4]
x = x.unsqueeze(2)
# x的维度现在变成[32,4,1]
y = Variable(y)
y = y.to(torch.float32)
# unsqueeze是在最后增加一个维度,否则输出shape是[32]
y = y.unsqueeze(1) # 输出shape是[32,1]
optimizer.zero_grad()
outputs = net(x)
loss = criterion(outputs, y)
total_loss += loss.sum() # 因为标签值和输出都是一个张量,所以损失值要求和
loss.sum().backward()
optimizer.step()
if (epoch+1)%50==0:
print('Epoch {}, Loss: {:.4f}'.format(epoch+1, total_loss/len(trainDataset)))
torch.save(net, 'lstm.pt')train(epochs=1000) # 训练1000个epochs
# 输出:
Epoch 50, Loss: 0.0170
Epoch 100, Loss: 0.0156
Epoch 150, Loss: 0.0144
Epoch 200, Loss: 0.0132
Epoch 250, Loss: 0.0121
Epoch 300, Loss: 0.0110
Epoch 350, Loss: 0.0100
Epoch 400, Loss: 0.0091
Epoch 450, Loss: 0.0082
Epoch 500, Loss: 0.0074
Epoch 550, Loss: 0.0067
Epoch 600, Loss: 0.0060
Epoch 650, Loss: 0.0053
Epoch 700, Loss: 0.0048
Epoch 750, Loss: 0.0042
Epoch 800, Loss: 0.0038
Epoch 850, Loss: 0.0034
Epoch 900, Loss: 0.0030
Epoch 950, Loss: 0.0027
Epoch 1000, Loss: 0.0025结果验证:
# 预测
net = torch.load('lstm.pt')
features = torch.from_numpy(features)
features = features.float()
features = features.unsqueeze(2)
y_pred = net(features)
# 画出sin函数作为序列函数
y = []
for i in range(996):
y.append(np.sin(0.01*i)+np.random.normal(0,0.2))
x = [i for i in range(996)]
fig, ax = plt.subplots()
ax.plot(x, y) # 画出输入数据
ax.plot(x, y_pred.detach().numpy(), color="y") #画出预测数据
plt.show()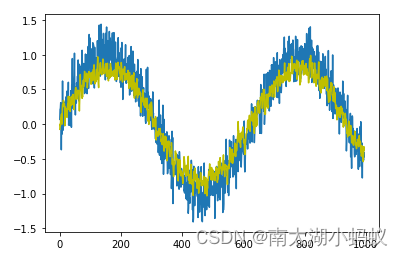
可以看到预测的结果和原始数据拟合较好,与我们前面使用的RNN网络模型结果类似。























![61、内蒙古工业大学、内蒙科学技术研究院:CBAM-CNN用于SSVEP - BCI的分类方法[脑机二区还是好发的]](https://img-blog.csdnimg.cn/direct/2bc65a9d10a542f48b141cfe6a0530dd.png)






![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.1,2,3-GPIO中断控制实验](https://img-blog.csdnimg.cn/direct/d7578bcae69846e687fa107af1cb1916.png)