hive自定义函数
当Hive的内置函数不能满足需要时,可以通过编写用户自定义函数UDF(User-Defined Functions)插入自己的处理代码并在查询中使用它们。
按实现方式,UDF分如下分类:
•普通的UDF,用于操作单个数据行,且产生一个数据行作为输出。
•用户定义聚集函数UDAF(User-Defined Aggregating Functions),用于接受多个输入数据行,并产生一个输出数据行。
•用户定义表生成函数UDTF(User-Defined Table-Generating Functions),用于操作单个输入行,产生多个输出行。
按使用方法,UDF有如下分类:
•临时函数,只能在当前会话使用,重启会话后需要重新创建。
•永久函数,可以在多个会话中使用,不需要每次创建。
说明:
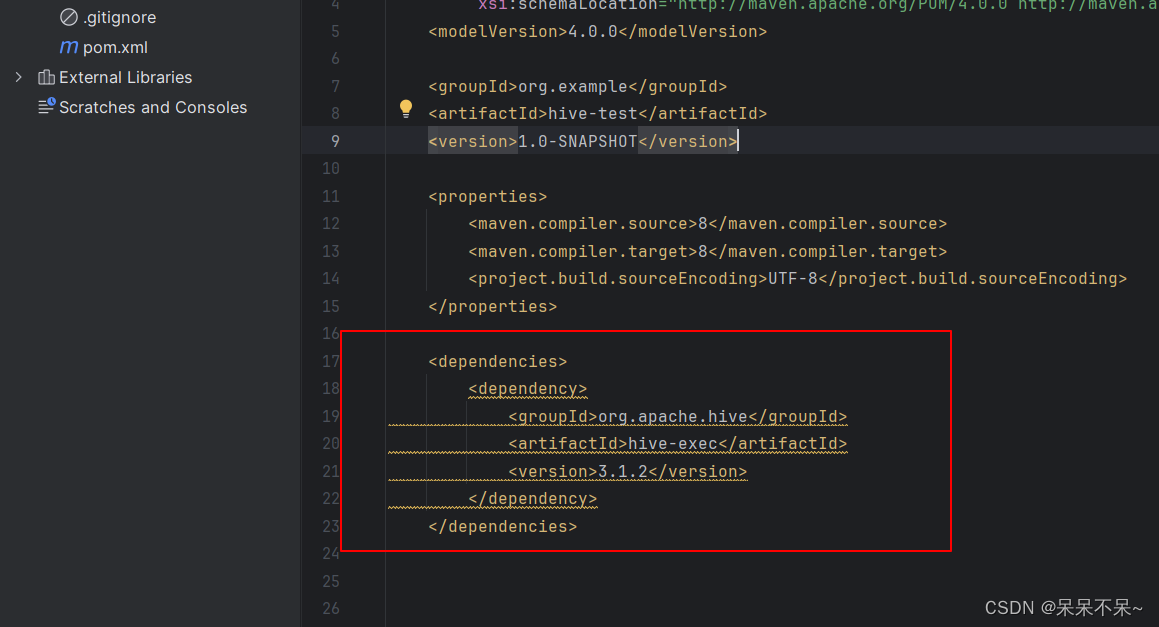
•一个普通UDF必须继承自“org.apache.hadoop.hive.ql.exec.UDF”。
•一个普通UDF必须至少实现一个evaluate()方法,evaluate函数支持重载。
•开发自定义函数需要在工程中添加hive-exec-3.1.0.jar依赖包,可从hive安装目录下获取。
示例:
java代码如下:
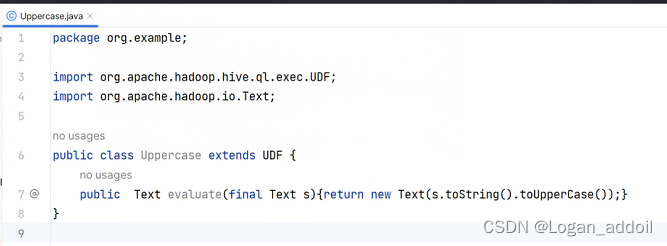
package day05_jar;
import org.apache.hadoop.hive.ql.exec.UDF;
public class TestHiveUdf extends UDF {
public static String evaluate(String str) {
return str.toUpperCase();
}
}
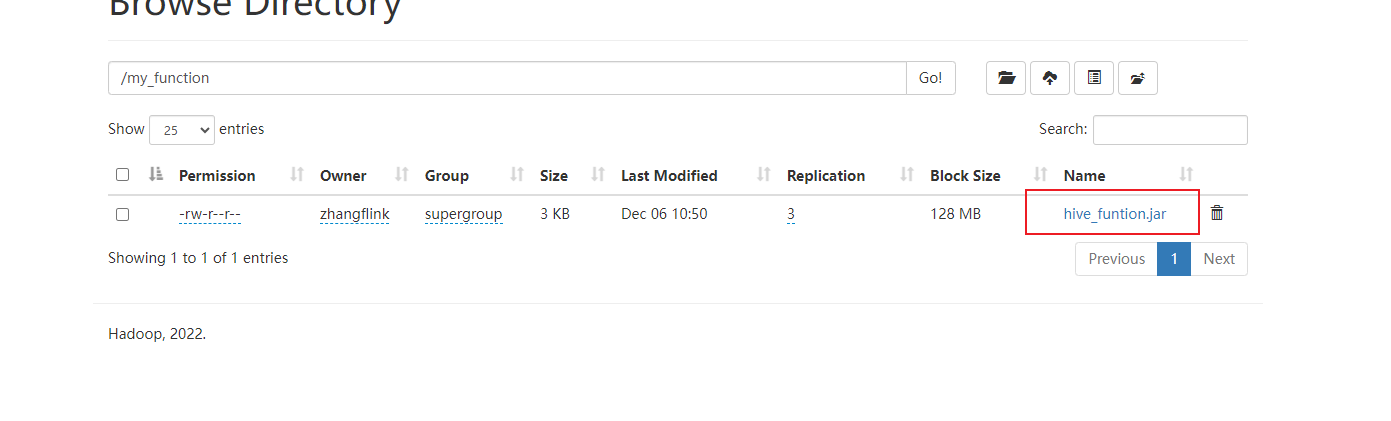
hadoop fs -mkdir /user/hive/warehouse/hdfs-examples
hadoop fs -put -f pinko.jar /user/hive/warehouse/hdfs-examples
CREATE FUNCTION ypg_upperstring AS 'day05_jar.TestHiveUdf' using jar ' /user/hive/warehouse/hdfs-examples/pinko.jar';
select ypg_upperstring('hello');
ypg_upperstring
-----------------
HELLO
(1 row)