自定义UDF函数
历经几雨洗礼,盼你始终坚强如昔。我把思念化为祝福,伴随你三百六十五天。
目录
1.UDF:表示传入一行数据 再通过计算逻辑输出一行数据
2.老版本UDF 不推荐使用(字符串后加###):
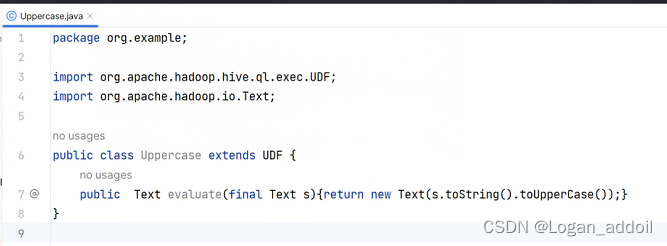
① 创建自定义类继承UDF
注意 自定义函数名必须使用 evaluate 不然识别不到
public class MyUDFAddString extends UDF {
/**
* 定义函数名 evaluate
* 实现将传入的String 增加后缀 ###
*
* @param col HIVE中使用函数时传入的数据
* @return 一行数据
*/
public String evaluate(String col) {
return col + "###";
}
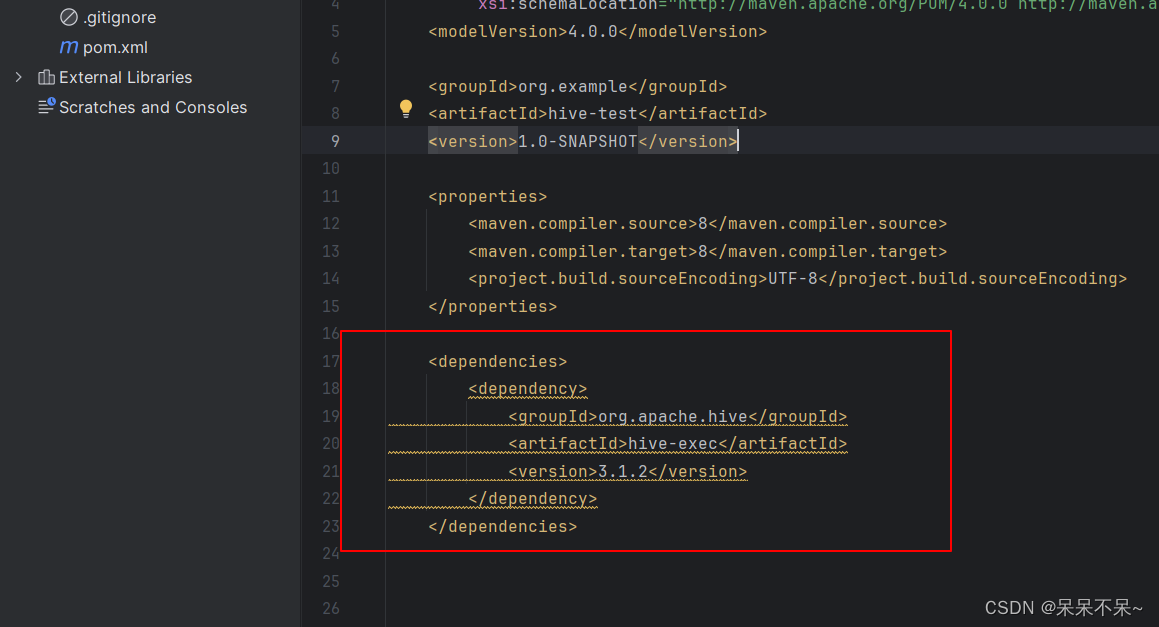
}② 将代码打包,添加jar包至HIVE中
add jar /usr/local/soft/test/jtxy_hdfs-1.0-SNAPSHOT.jar;
③ 创建临时自定义函数
CREATE TEMPORARY FUNCTION my_udf as "MyUDFAddString";

④查看效果
show functions like "*my*";
select my_udf("udf");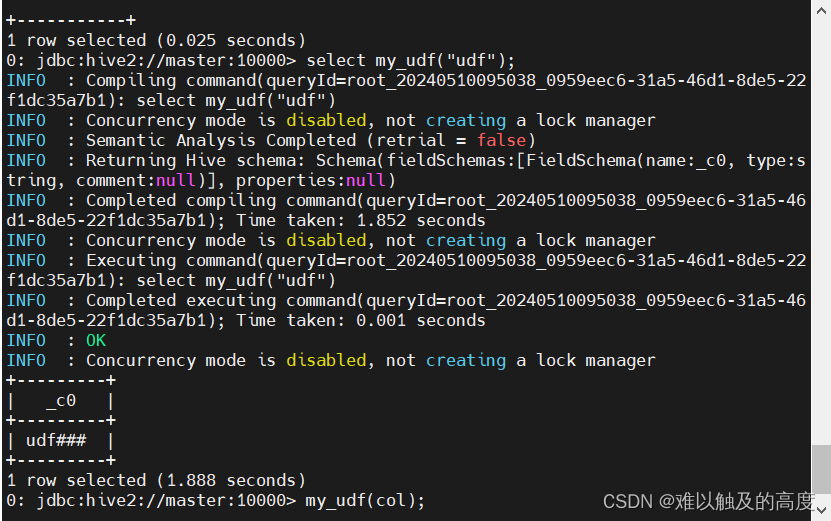
3.新版本UDF (返回字符串长度(一对一)):
① 创建自定义类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 需求:
* 传入一列数据 返回该列数据中每行的字符串长度
*
* 样例:getlen("abcd") -> 4
*/
public class MyNewUDFDemo extends GenericUDF {
/**
*实例化
* arguments 该参数为HIVE注册后的方法传入参数 是一个检查器对象的数组
* return 返回的类型是指 我们数据输出的数据类型 该例中 getlen("abcd") -> 4 指的是int
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
//如果传入参数长度不为1 那么就返回UDF长度异常 并提示异常信息
if(arguments.length != 1){
throw new UDFArgumentLengthException("传入参数长度不够...");
}
//获取一个参数 对比传入参数的数据类型
/**
* PRIMITIVE:hive中String int double float boolean等基础数据类型
* LIST:数组类型
* MAP:Map类型
* STRUCT:结构体数据类型
*/
if(arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
/**
* UDFArgumentTypeException(int argumentId, String message)
* 异常对象需要传入两个参数
* int argumentId 表示参数的位置 ObjectInspector中的下标
* String message 表示异常信息
*/
throw new UDFArgumentTypeException(0,"参数类型不正确...");
}
//可以通过查看GenericUDF 其他子类实现去比对查看继承关系快捷键 Ctrl + H
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* evaluate方法可以去实现数据的处理逻辑
*
* return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
// 获取第0位参数的值
String columns1 = arguments[0].get().toString();
return columns1.length();
}
/**
*
* @param strings
* @return
*/
@Override
public String getDisplayString(String[] strings) {
return "展现执行计划及流程...";
}
}
② 将代码打包,添加jar包至HIVE中
add jar /usr/local/soft/myjar/jtxy_hdfs-1.0-SNAPSHOT.jar;
③ 创建临时自定义函数
CREATE TEMPORARY FUNCTION getlen as "MyNewUDFDemo";

④查看效果
select getlen("abcd");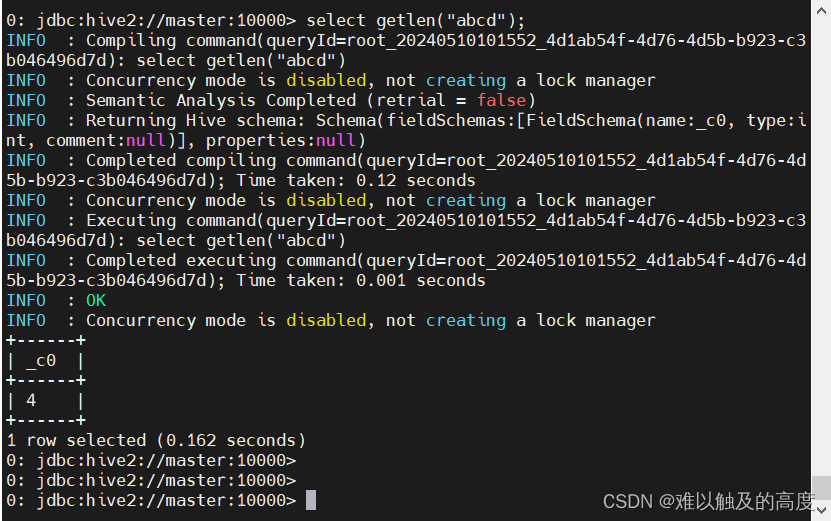
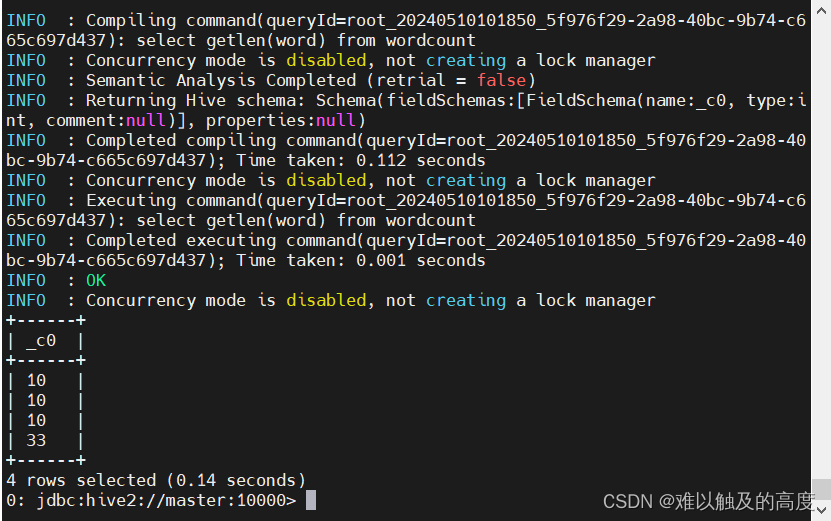
我们也可以通过表格来看一下效果:
use learn3;
show tables;
select * from wordcount;
select getlen(word) from wordcount;
4.返回字符串长度(一对多)
/**
*
* 需求:
* 通过wordCount 去实现一个 切分数据,并将一行数据变成多行数据
* 类似于:explode(split(word,''))
* 样例:
* myudtf(word,',')
*/select explode(split(word,',')) from wordcount;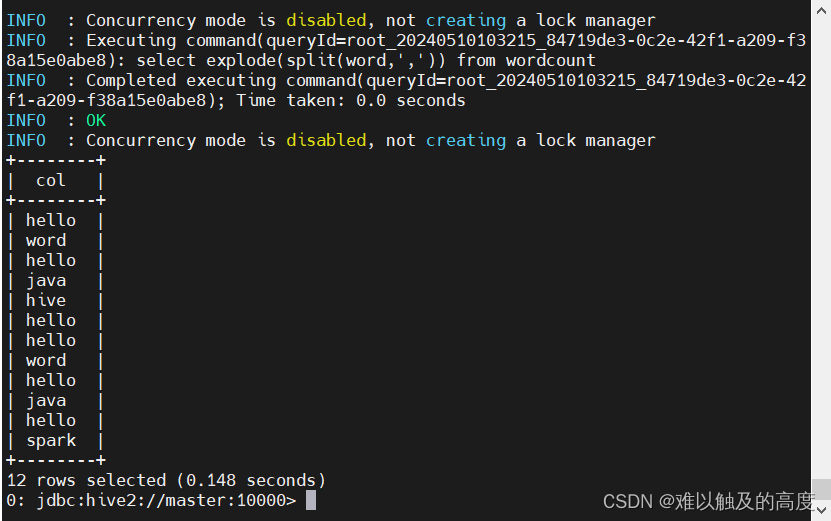
① 创建自定义类
注意:UDTF是没有自己的类型异常类 可以通过UDF的类型异常类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
/**
*
* 需求:
* 通过wordCount 去实现一个 切分数据,并将一行数据变成多行数据
* 类似于:explode(split(word,''))
* 样例:
* myudtf(word,',')
*/
public class MyUDTFDemo extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//获取所有字段的列表
List<? extends StructField> fieldRefs = argOIs.getAllStructFieldRefs();
if(fieldRefs.size() != 2){
throw new UDFArgumentLengthException("传入参数长度不对...");
}
if (!fieldRefs.get(0).getFieldObjectInspector().getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"");
}
for (int i = 0; i < fieldRefs.size(); i++) {
if(fieldRefs.get(i).getFieldObjectInspector().getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(i,"传入参数类型不对...");
}
}
// 输出字段的数据名称
ArrayList<String> fieldNames = new ArrayList();
fieldNames.add("OutPut");
// 输出字段的数据类型
ArrayList<ObjectInspector> fieldOIs = new ArrayList();
//fieldOIs.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
/**
* 具体的数据处理对象
*forward中的处理方法:
* collector.collect(o); 表示通过收集器的收集方法收集一行数据
*
* @param
* @throws HiveException
*/
@Override
public void process(Object[] args) throws HiveException {
ArrayList<Object> LineRes = new ArrayList<>();
if(args[0] == null){
LineRes.add(null);
forward(LineRes);
}
String line = args[0].toString();
String regex = args[1].toString();
for (String s : line.split(regex)) {
LineRes.clear();
LineRes.add(s);
forward(LineRes);
}
}
/**
*
* @throws HiveException
*/
@Override
public void close() throws HiveException {
System.out.println("Nothing to do....");
}
}
② 将代码打包,添加jar包至HIVE中
add jar /usr/local/soft/myjar2/jtxy_hdfs-1.0-SNAPSHOT.jar;
③ 创建临时自定义函数
CREATE TEMPORARY FUNCTION myudtf as "MyUDTFDemo";
④查看效果
select myudtf(word,",") from wordcount;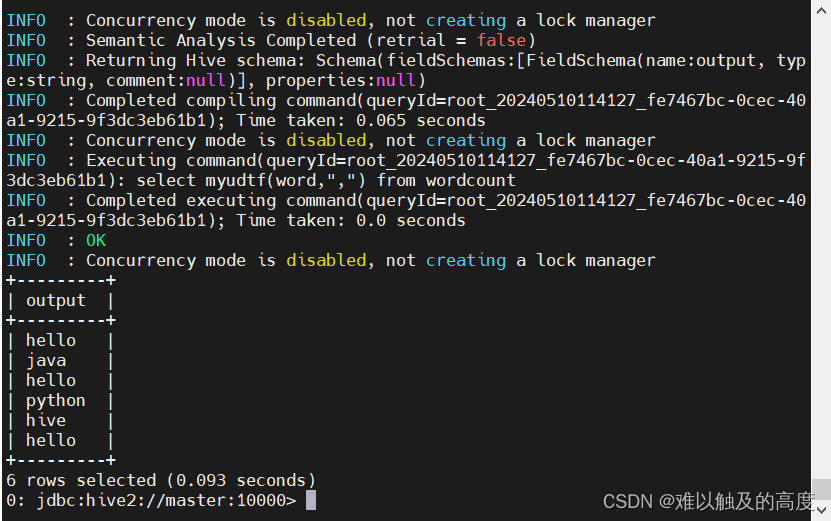
5.多对多(复杂)
1)需求及流程
/**
* 需求:
* {"movie": [{"movie_name": "肖申克的救赎", "MovieType": "犯罪" }, {"movie_name": "肖申克的救赎", "MovieType": "剧情" }]}
* 为一行数据 类型为JSON 需要从JSON中取出 movie_name MovieType 两个key对应的value值
*
* 并且数据输出的格式为:
* movie_name MovieType
* 肖申克的救赎 犯罪
* 肖申克的救赎 剧情
* .... .....
*
*
* 流程:
* 1.实例化UDTF 并且在实例化方法中判断传入参数的数据的长度及数据类型
* 2.创建输出字段名称的数组以及字段数据类型的数组
* 3.process中编辑处理的逻辑
* 4.讲处理好的数据通过forward方法将数据按行给出
* 5.将数据打包至Linux的hive中 创建使用
*/2)创建库及表 上传数据
create database learn4;
use learn4;
create table learn4.movie
(
json_str String comment "电影JSON"
)
STORED AS TEXTFILE;
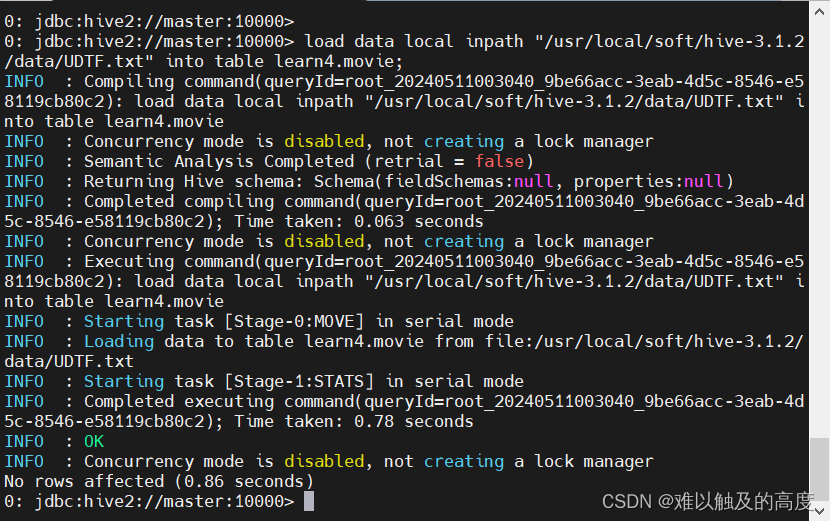
load data local inpath "/usr/local/soft/hive-3.1.2/data/UDTF.txt" into table learn4.movie;
select * from learn4.movie;
3)查看相应的json函数
show functions like "*json*";
desc function extended get_json_object;
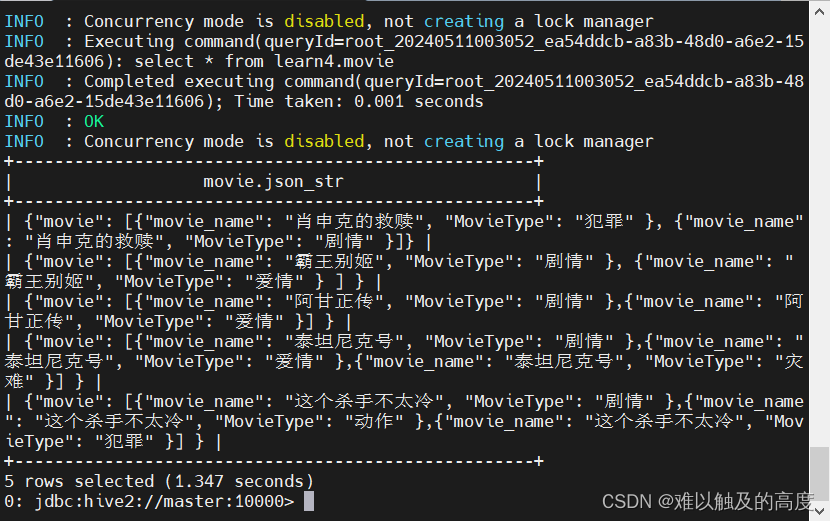
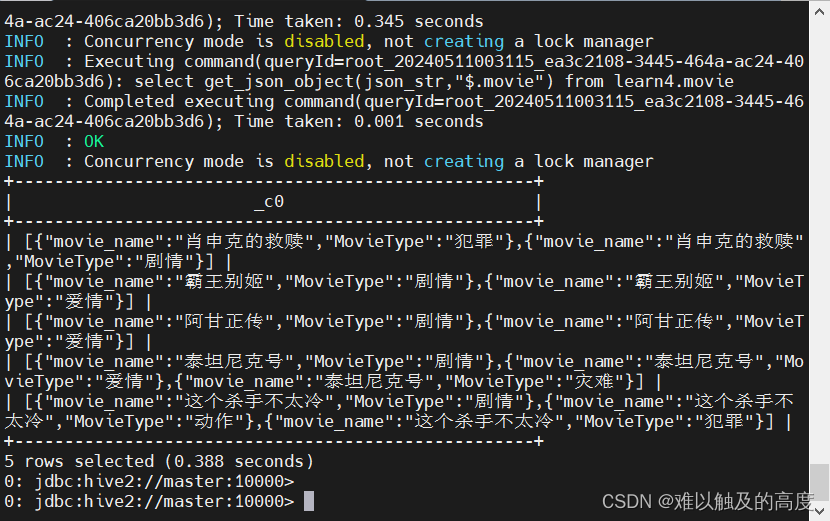
select get_json_object(json_str,"$.movie") from learn4.movie;
① 创建自定义类
注意:UDTF是没有自己的类型异常类 可以通过UDF的类型异常类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import org.json.JSONObject;
import java.util.ArrayList;
import java.util.List;
/**
* 需求:
* {"movie": [{"movie_name": "肖申克的救赎", "MovieType": "犯罪" }, {"movie_name": "肖申克的救赎", "MovieType": "剧情" }]}
* 为一行数据 类型为JSON 需要从JSON中取出 movie_name MovieType 两个key对应的value值
*
* 并且数据输出的格式为:
* movie_name MovieType
* 肖申克的救赎 犯罪
* 肖申克的救赎 剧情
* .... .....
*
*
* 流程:
* 1.实例化UDTF 并且在实例化方法中判断传入参数的数据的长度及数据类型
* 2.创建输出字段名称的数组以及字段数据类型的数组
* 3.process中编辑处理的逻辑
* 4.讲处理好的数据通过forward方法将数据按行给出
* 5.将数据打包至Linux的hive中 创建使用
*/
public class MyUDTFDemo2 extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 实例化UDTF 并且在实例化方法中判断传入参数的数据的长度及数据类型
List<? extends StructField> fieldRefs = argOIs.getAllStructFieldRefs();
if(fieldRefs.size() != 1){
throw new UDFArgumentLengthException("长度不是1 不符合要求");
}
if(!fieldRefs.get(0).getFieldObjectInspector().getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"数据类型不正确...");
}
// 创建输出字段名称的数组以及字段数据类型的数组
ArrayList<String> columNames = new ArrayList<>();
ArrayList<ObjectInspector> columType = new ArrayList<>();
columNames.add("movie_name");
columType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columNames.add("MovieType");
columType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(columNames, columType);
}
/**
*
* @param
* @throws HiveException
*/
@Override
public void process(Object[] args) throws HiveException {
//process中编辑处理的逻辑
String[] outline = new String[2];
if(args[0] != null){
JSONArray jsonArray = new JSONArray(args[0].toString());
for (int i = 0; i < jsonArray.length(); i++) {
JSONObject jsonObject = jsonArray.getJSONObject(i);
outline[0] = jsonObject.getString("movie_name");
outline[1] = jsonObject.getString("MovieType");
forward(outline);
}
}else{
outline[0] =null;
outline[1] =null;
//讲处理好的数据通过forward方法将数据按行给出
forward(outline);
}
}
/**
*
* @throws HiveException
*/
@Override
public void close() throws HiveException {
System.out.println("Nothing to do....");
}
}
② 将代码打包,添加jar包至HIVE中
add jar /usr/local/soft/myjar3/jtxy_hdfs-1.0-SNAPSHOT.jar;
③ 创建临时自定义函数
CREATE TEMPORARY FUNCTION myudtf2 as "MyUDTFDemo2";
④查看效果
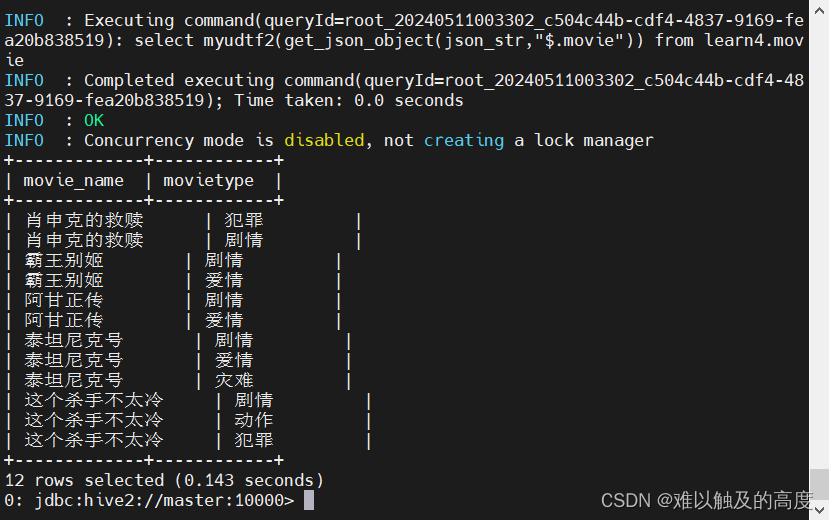
select myudtf2(get_json_object(json_str,"$.movie")) from learn4.movie;





















![[ES] ElasticSearch节点加入集群失败经历分析主节点选举、ES网络配置 [publish_address不是当前机器ip]](https://img-blog.csdnimg.cn/direct/26d2ccc593f444cd8d42b0f69fe26aaa.png)