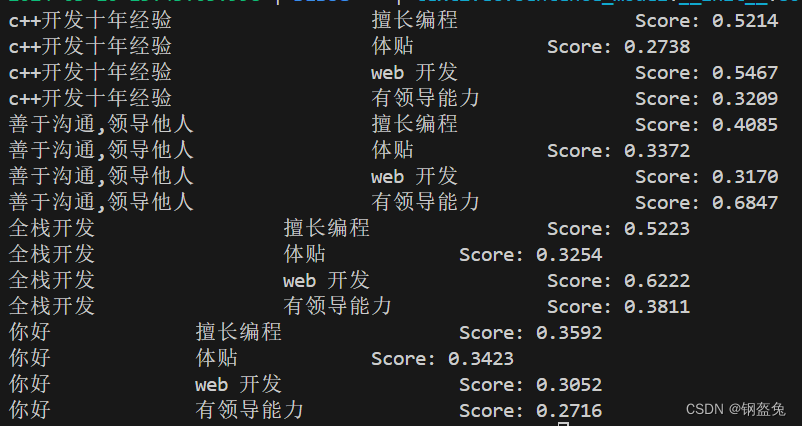
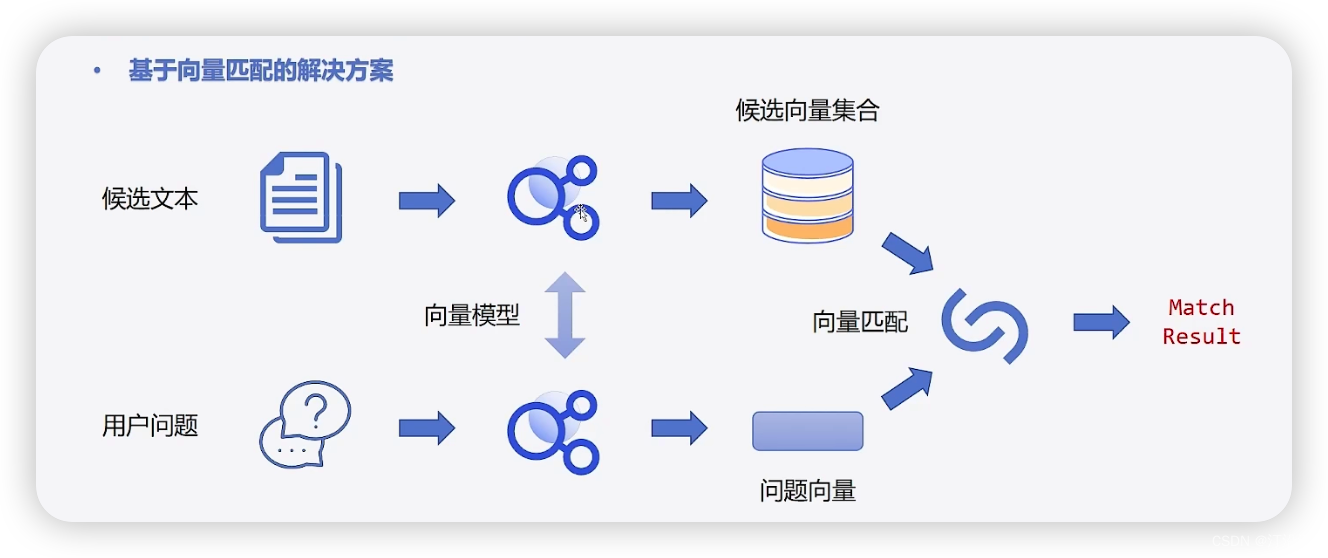
import os
import json
from sklearn.feature_extraction.text import TfidfVectorizer
from simhash import Simhash, SimhashIndex
import jieba
def process_txt_file(data, output_file, similar_json_file):
"""
处理 TXT 文件,去除相似文本后另存为新的 TXT 文件,并记录相似文本段到 JSON 文件中
"""
def chinese_tokenizer(text):
"""中文分词函数"""
return jieba.lcut(text)
def filter_similar_sentences_simhash(sentences, k=13):
"""使用 Simhash 过滤相似句子并记录"""
vectorizer = TfidfVectorizer(tokenizer=chinese_tokenizer)
tfidf_matrix = vectorizer.fit_transform(sentences)
similar_sentences = [] # 存储所有相似句子
def simhash_features(tfidf_vector):
features_weights = zip(vectorizer.get_feature_names_out(), tfidf_vector.toarray()[0])
return [(feature, weight) for feature, weight in features_weights if weight > 0]
fingerprints = [Simhash(simhash_features(tfidf_vector)) for tfidf_vector in tfidf_matrix]
index = SimhashIndex([], k=k)
unique_sentences = []
for i, (sentence, fingerprint) in enumerate(zip(sentences, fingerprints)):
# if sentence is None: # 跳过已经处理过的相似句子
# continue
duplicates = index.get_near_dups(fingerprint)
# 将字符串类型的索引转换为整数类型的列表
duplicates = [int(dup) for dup in duplicates]
if not duplicates or len(sentence) < 5:
unique_sentences.append(sentence)
index.add(i, fingerprint)
else:
# print("当前句子:", sentence)
for dup_index in duplicates:
similar_sentence = sentences[dup_index]
if similar_sentence:
# print("相似句子:", similar_sentence, len(similar_sentence))
# 记录相似的句子
similar_sentences.append({
'当前句子': sentence,
'相似句子': similar_sentence
})
print("---------------------")
# 移除相似的句子
sentences[dup_index] = None
print("移除相似的句子",sentences[dup_index])
sentences = [s for s in sentences if s] # 过滤掉已标记为相似的句子
print(sentences)
# 将所有相似句子记录写入文件
with open(similar_json_file, "w", encoding="utf-8") as json_file:
for similar_sentence in similar_sentences:
json_file.write(json.dumps(similar_sentence, ensure_ascii=False) + "\n")
return sentences
# 提取所有文本内容并拼接起来
all_content = ''.join(item['content'] for item in data)
# 将所有文本内容按句号切割成句子列表
sentences = all_content.split('。')
# 过滤相似句子并记录
unique_sentences = filter_similar_sentences_simhash(sentences, k=13)
# 按照原来的 content 归属顺序排列处理后的句子
processed_data = []
start_index = 0
for item in data:
content = item['content']
end_index = start_index + content.count('。') + 1
processed_content = '。'.join(unique_sentences[start_index:end_index])
item['content'] = processed_content
processed_data.append(item)
start_index = end_index
# 将处理后的文本数据写入新的 JSON 文件
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(processed_data, f, ensure_ascii=False, indent=4)
# 读取原始 JSON 数据
with open("a.json", 'r', encoding='utf-8') as f:
data = json.load(f)
output_file = 'a_output.json' # 新的 JSON 文件路径
similar_json_file = 'a_similar.jsonl' # 相似文本记录 JSON 文件路径
process_txt_file(data, output_file, similar_json_file)