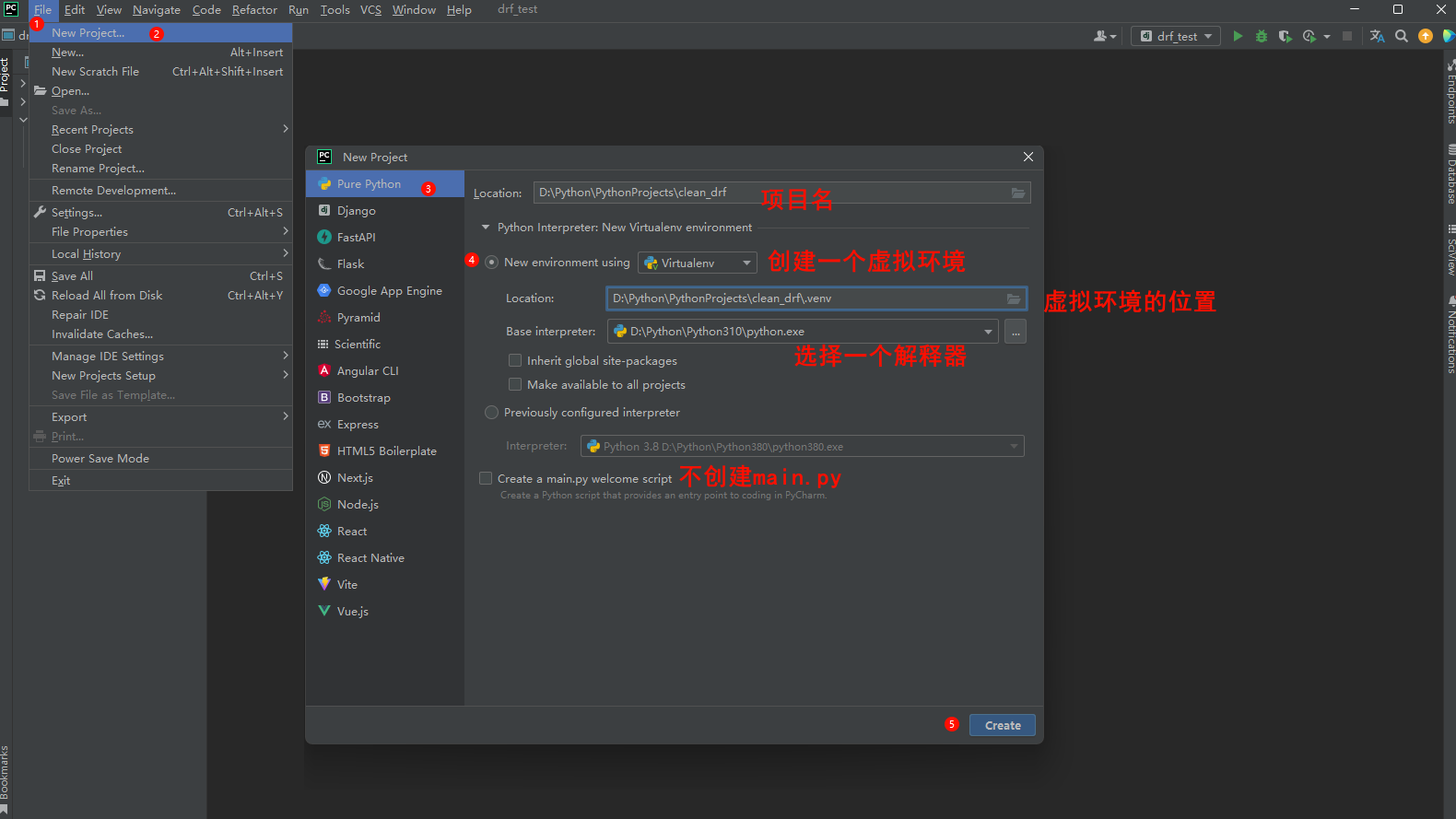
前言
对本博客比较熟悉的朋友知道,我司论文项目组正在基于大模型做论文的审稿(含CS英文论文审稿、和金融中文论文审稿)、翻译,且除了审稿翻译之外,我们还将继续做润色/修订、idea提炼(包含论文检索),是一个大的系统,包含完整的链路
由于论文项目组已壮大到18人,故目前在并行多个事,且我也针对idea提炼做一下技术探索,本文解析关于idea提炼的两篇论文
- 我司论文项目组三太子在内部18人大群里4.14发的这篇:ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Mode
- // 待定
第一部分 ResearchAgent: 围绕论文和引用提炼idea
1.1 从ResearchAgent到ReviewingAgent:idea的生成与其迭代
考虑到LLMs可以处理和分析大量的文献资料,并以超越人类能力的速度和规模处理数据,还可以识别人类研究者可能立即无法察觉的模式、趋势和相关性,从而使LLM能够发现原本未被发现的新的研究机会。 此外,LLM还可以通过进行实验和解释结果来协助实验验证,从而显着加快研究周期
近日,来自韩国的一研究团队便基于LLM做了相关尝试,即研究思路生成,其中包括问题识别、方法开发和实验设计(research idea generation, which involves problem identification, method development, and experiment design)
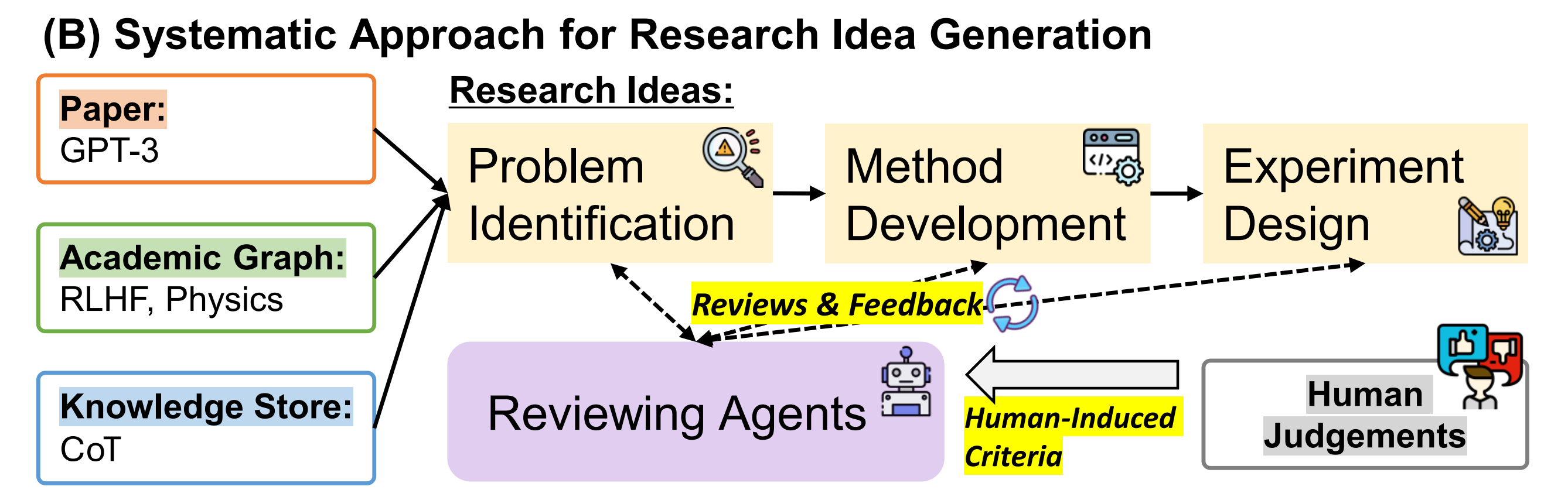
那基于LLM如何提炼idea呢?其实和科研人设计idea的过程差不太多,比如首要的第一步便是阅读大量相关领域的paper,然后提炼出一个初步的idea,最后针对这个初步的idea反复自我审视及让同行给予反馈、评价,以不断完善该idea
换言之,只阅读某篇论文及其对应的参考文献,从而根据references and citation relationship提炼idea可能不太够
- 首先构建一个知识存储,从科学文章中找到并聚合实体共现。 这个以实体为中心的知识存储捕捉了不同实体之间的相互关联性,并通过潜在的概念和原则为其检索到的知识提供了有价值的见解;我们将展示这些见解对我们的问题非常有价值。
- 此外,为了通过迭代改进增强生成的研究创意,我们设计了多个审查代理,每个代理都对开发的创意生成评论和反馈,具有自己的评估标准
1.1.1 ResearchAgent的流程:基于LLM确定问题、方法、实验
为了完成上述步骤,现有的文献(例如学术出版物)被用作主要来源,提供关于现有知识以及差距和未解答问题的见解
首先,形式上,设为文献,
为由问题
、方法
和实验设计
组成的想法,表示如下:
,其中每个项目由一系列tokens组成,
表示连接操作
然后,idea生成模型 可以表示如下:
,进一步分解为三个子模块步骤:
用于确定问题
用于开发方法
- 以及
用于设计实验
在这项工作中,依赖LLMs来操作 f,利用它们理解和生成学术文本的能力(we operationalize f with LLMs, leveraging their capability to understand and generate academic text)
具体而言,LLM接受一个输入token序列 x并生成一个输出token序列 y,表示为:,其中
是模型参数,在训练后固定不变(毕竟进一步微调的成本很高),
是提示模板(prompt template),是一个结构化的格式,概述了上下文(包括任务描述和指示)以指导模型生成所需的输出
从而,上述三个子模块便变成了
- 确定问题:
- 确定方法:
- 确定实验:
对于 LLM,我们通过提供一篇核心论文从
开始,然后根据citation graph选择性地纳入后续论文
,这些论文与核心论文直接相关,从而使得用于生成研究想法的 LLM输入更加可管理和连贯「we initiate its literature review process by providing a core paper l0 from L and then selectively incorporating subsequent papers {l1, ..., ln} that are directly related to it based on a citation graph」
且,对于核心论文及其相关引文(relevant citations)的选择,侧重以下两点
- 核心论文基于其引用计数进行选择(例如,在3个月内超过100次),通常表示具有高影响力
- 其相关论文(可能非常多)根据其摘要与核心论文的相似性进一步缩小范围,确保得到更加专注和相关的相关paper集合
1.1.2 ResearchAgent的增强:通过实体链接方法提取术语数据库
然后,核心论文及其引用的数量毕竟有限,所能带来的上下文知识范围过于局限,而使得无法提出更好的idea

- 好在我们可以使用现有的现成实体链接方法(实体链接是一个将文本中的不同实体识别并映射到知识库中实体的过程)在任何论文中提取术语数据库(term database),并将这些链接的出现聚合到一个知识库中
we can easily extract the term database whenever it appears in any paper, using existing off-the-shelf entity linking methods and then aggregate these linked occurrences into a knowledge store. - 然后,如果术语数据库在医学科学领域中普遍存在,但在血液学(医学科学的一个子领域)中不太常见,构建的知识库基于除数据库之外的重叠实体捕捉了这两个领域之间的相关性,然后便可在制定有关血液学的想法时提供术语数据库
Then, if the term database is prevalent with in the realm of medical science but less so in hematology (which is a subdomain of medical science), the constructed knowledge store captures the relevance between those two domains based on overlapping entities (other than the database) and then offers the term database when formulating the ideas about hematology.
换句话说,这种方法通过利用各个领域之间的相互关联性,能够提供新颖和跨学科的见解
In other words, this approach enables providing novel and interdisciplinary insights by leveraging the interconnectedness of entities across various field
具体的执行步骤为
- 将知识存储设计为一个二维矩阵
,其中
是已识别的唯一实体的总数,而
以稀疏格式实现
这个知识存储是通过从所有可用的科学文献(由于无法提取所有可用文章中的实体,故这里的目标是针对2023年5月1日之后出现的论文)中提取实体构建的,它不仅计算了个别论文中实体对的共现次数,还量化了每个实体的计数
- 此外,为了操作化实体提取,我们使用了现有的实体链接器 EL(即BLINK,Wu et al., EMNLP 2020,地址为:Scalable zeroshot entity linking with dense entity retrieval),它在特定论文
从
其中表示出现在
- 在提取实体
后,为了将它们存储到知识存储
中,我们考虑了所有可能的
,其中
,然后将其记录到
鉴于这个知识库
使得我们可以通过“知识库 - 形式上,定义从相互连接的论文组中提取的实体如下:
因此,检索前k个相关外部实体的概率形式可以表示如下
其中,且
此外,为了简化起见,通过应用贝叶斯规则并假
设实体是独立的,上面的检索前k个相关外部实体的操作可以近似表示如下:
其中和
可以从二维
- 最终,使用相关实体为中心的知识增强的研究提案生成实例
表示如下:
总之,将这种知识增强的LLM驱动的思路生成方法称为ResearchAgent
- 首先,通过ResearchAgent提出问题

- 其次,通过ResearchAgent生成方法

- 最后,通过ResearchAgent生成实验设计

1.1.3 ReviewingAgent给验证:通过与人类偏好对齐的LLM Agents迭代研究思路
当拿到初步的idea之后(包括其对应的问题、方法、实验设计),ReviewingAgents还会根据特定的标准提供review和反馈,以验证生成的研究思路
具体而言,类似于我们使用LLM和模板T实例化ResearchAgent的方法,ReviewingAgents也是类似地实例化,但使用不同的模板,如下面的三个图所示,分别涉及
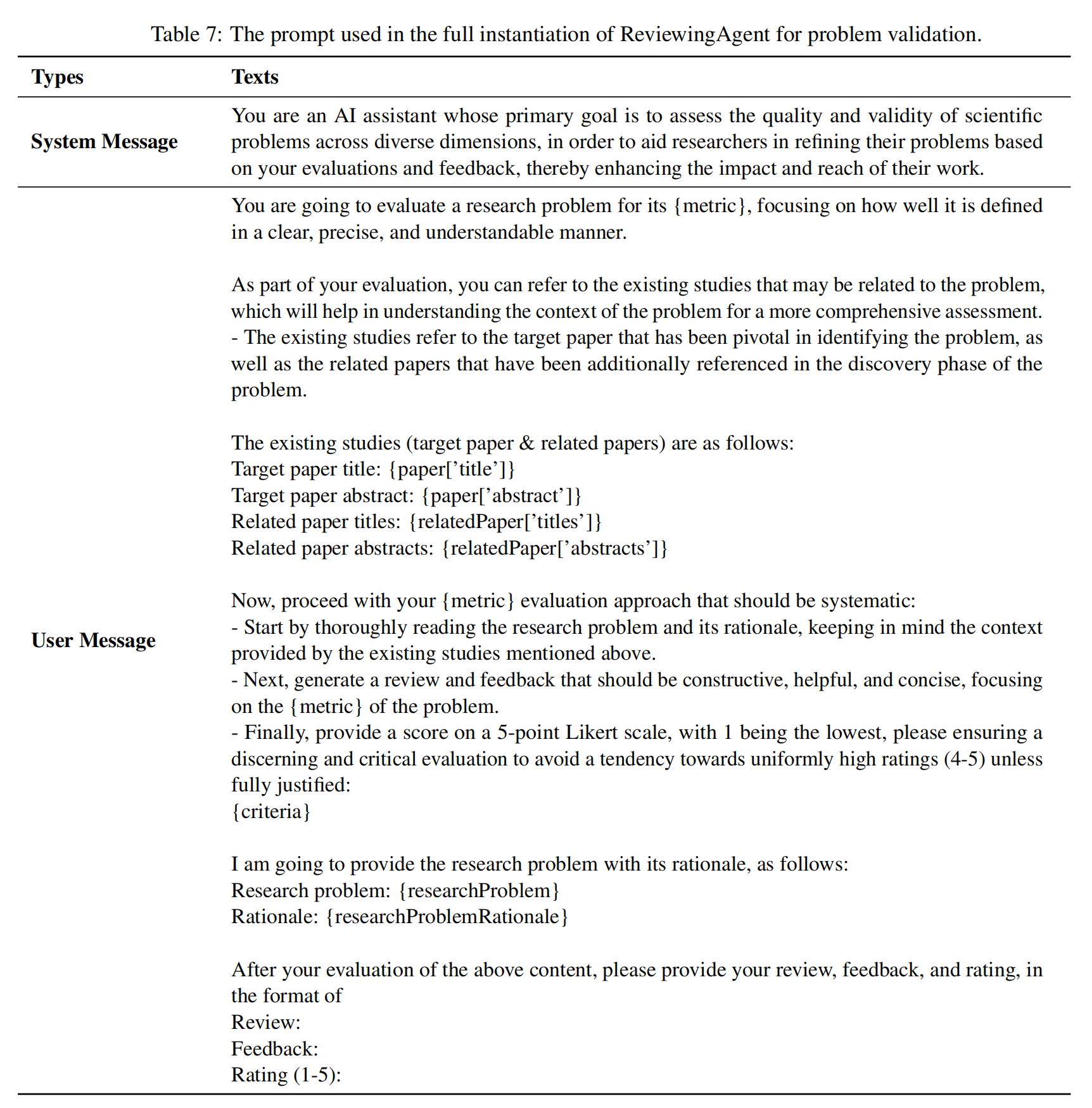


- 对ResearchAgent所提出问题的评价
现有研究(目标论文和相关论文)如下:
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
现在,按照系统的方式进行您的{指标}评估方法:- 首先彻底阅读研究问题及其基本原理,牢记上述现有研究提供的背景信息。
- 接下来,生成一篇评论和反馈,应该是建设性的、有帮助的和简明的,重点关注问题的{指标}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供研究问题及其理论基础,如下所示:
研究问题:{研究问题}
理论基础:{研究问题理论基础}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5): - 对ResearchAgent所提出方法的评价
研究问题和现有研究(目标论文和相关论文)如下:
研究问题:{researchProblem}
理由:{researchProblemRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
现在,继续你的{度量}评估方法,应该是系统的:- 首先,彻底阅读提出的方法及其基本原理,牢记研究问题所提供的背景和上述现有研究。
- 接下来,生成一个评论和反馈,应该是建设性的、有帮助的和简洁的,重点关注方法的{度量}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供以下关于提出的方法及其基本原理的信息:
科学方法:{科学方法}
基本原理:{科学方法基本原理}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5): - 对ResearchAgent所提出的实验设计的评价
研究问题、科学方法和现有研究(目标论文和相关论文)如下所示:
研究问题:{researchProblem}
理由:{researchProblemRationale}
科学方法:{scientificMethod}
理由:{scientificMethodRationale}
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
现在,继续你的{度量}评估方法,应该是系统的:- 首先,彻底阅读实验设计及其基本原理,牢记研究问题、科学方法和上述现有研究所提供的背景。
- 接下来,生成一个评论和反馈,应该是建设性的、有帮助的和简明扼要的,重点关注
实验的{度量}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供设计好的实验及其基本原理,如下所示:
实验设计:{实验设计}
基本原理:{实验设计基本原理}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5):
然后,使用ReviewingAgents,根据其各自的五个特定标准对生成的研究思路(问题、方法和实验设计)进行单独评估,这些标准如下图所示
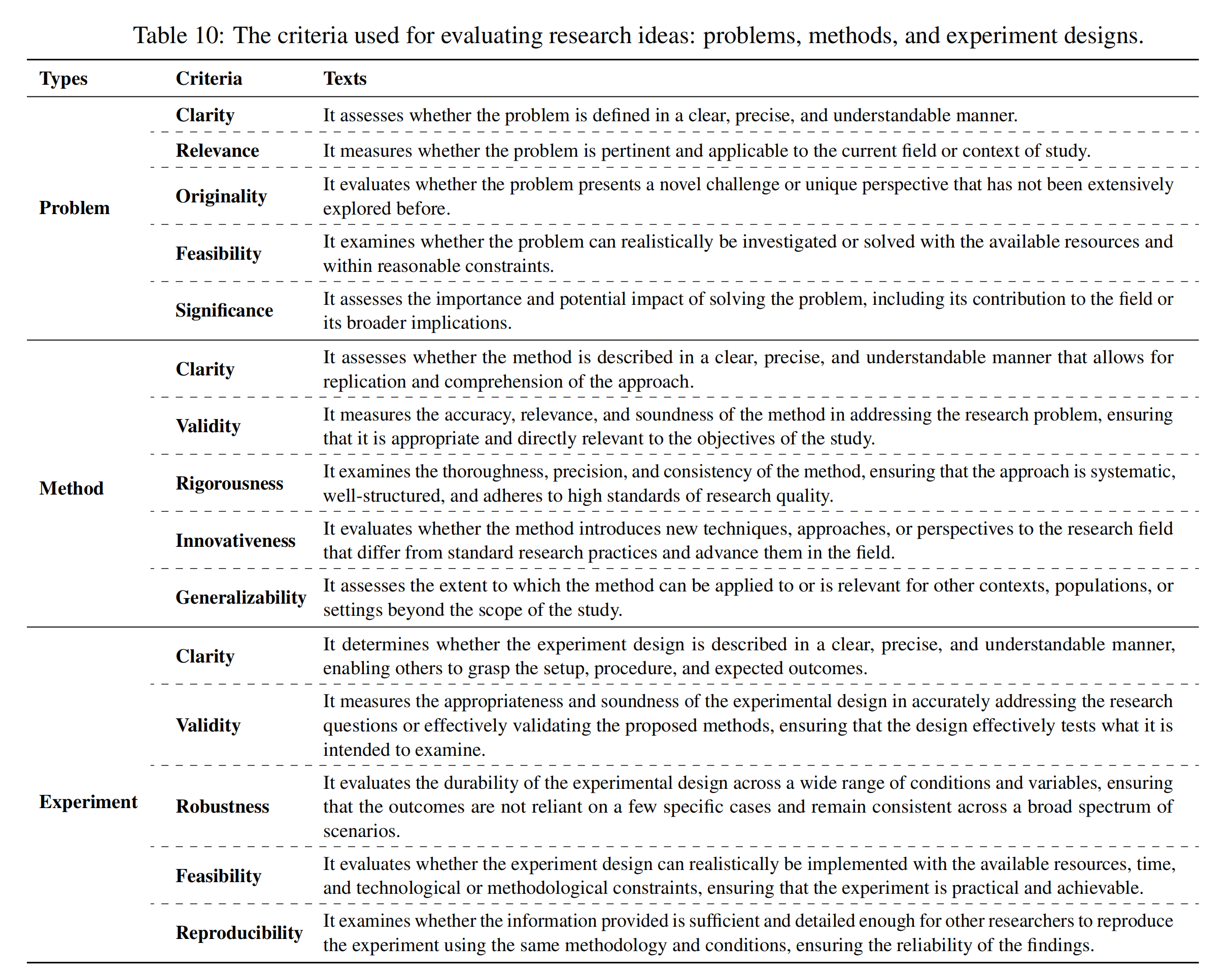
以下则是分别针对问题、方法、实验设计的各个标准下何以评分1-5分的的详细说明



最后,根据ReviewingAgents的审查和反馈,ResearchAgent进一步更新已生成的研究思路
值得一提的是,为了获得与人类对齐的评估标准
- 首先,筛选了10个人类专家「每个人至少自己发表过三篇论文(要不然,何以称为专家呢)」
然后,10个人类专家面对一篇篇论文时,针对每篇论文的问题、方法、实验设计在五个标准上进行评分,从而得到ResearchAgent针对每篇论文在问题、方法、实验设计这三个层面的10对分数(on a 5-point Likert scale)的标注
比如对于某一篇论文paperA而言,会有:
paperA-problem-score1 score2 score3 score4 score5 score6 score7 score8 score9 score10
paperA-method-score1 2 3 4 5 6 7 8 9 10
paperA-experiment design-score1 2 3 4 5 6 7 8 9 10
we first collect 10 pairs of the research idea and its score (on a 5-point Likert scale annotated by human researchers with at least 3 papers) on every evaluation criterion
最后,针对每篇论文的这个评分过程做三轮,相当于每篇paper在不同的思路下都会出来三个问题、三个方法、三个实验设计- 总之,针对每一篇论文,对ResearchAgent生成的3个问题、3个方法、3个实验设计做评判,然后每个问题、每个方法、每个实验设计均有5个标准
在每个标准上,由10个人类专家来针对论文提炼出来的3个问题、3个方法、3个实验设计进行打分
To conduct evaluations with human judges, we recruited 10 annotators, each with a minimum of 3 published papers. On average,with in an hour, they evaluated 3 sets of research ideas, with each set comprising three sub-ideas(problem, method, and experiment design) from three different approaches (i.e., a total of 9 ideas for one hour)
为方便大家快速理解以一目了然,我再画一个示意图,如下所示(A B C D E代表标准,_ _ _ _ _ _ _ _ _ _代表人类打的分数)

1.2 实验部分
1.2.1 数据
生成研究思路的主要来源是科学文献 L,具体而言
- 首先,从Semantic Scholar Academic Graph API(https://www.semanticscholar.org/product/api)获取,且选择在2024年5月1日之后出版的论文
- 然后,我们选择具有超过20次引用的高影响力论文作为核心论文,以确保生成的思路具有高质量,这与人类研究人员倾向于利用有影响力的工作相一致
- 我们进一步随机抽取300篇论文作为核心论文(以获得一个合理大小的基准数据集),这意味着我们随后为每个模型生成和评估300个研究思路
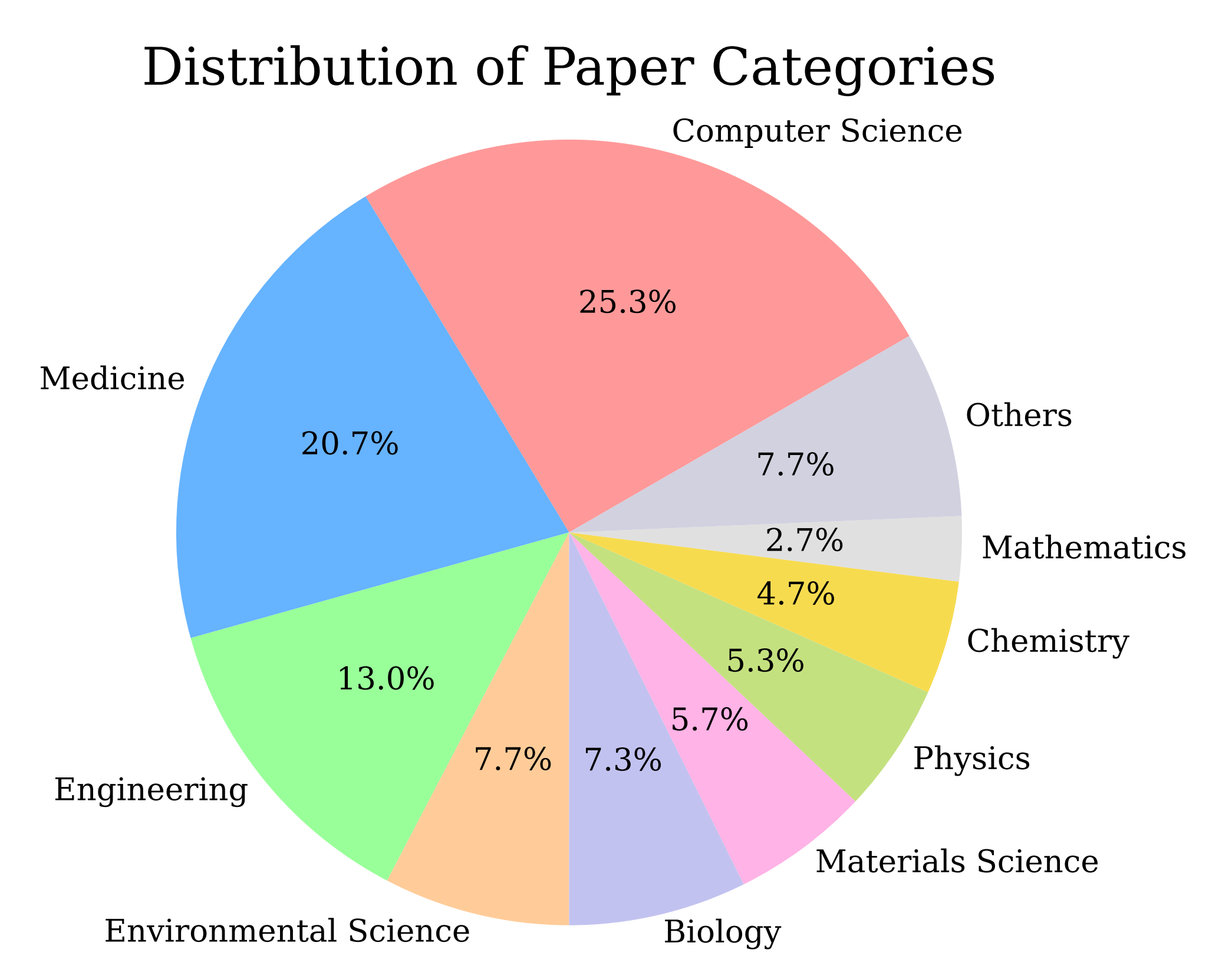
其中,每篇核心论文的平均参考文献数量为87,每篇论文的摘要平均有2.17个实体
所有论文的学科分布如下图所示
1.2.2 几个对比标准与评估方法
由于我们的目标是研究思路的生成,因此没有直接可供比较的基线。 因此,完整的ResearchAgent模型与以下削弱版本进行比较:
- Naive ResearchAgent- 仅使用核心论文生成研究思路
- 没有实体检索的ResearchAgent- 使用核心论文、及其相关参考文献,但不考虑实体
- ResearchAgent- 完整模型,使用相关参考文献、实体、以及核心论文,以增强语言模型
基于模型的评估根据最近在使用LLMs评判输出文本质量方面的趋势(尤其是在无参考评估设置中),我们使用GPT-4来评判研究思路的质量
我们注意到,每个问题、方法和实验设计都使用五个不同的标准进行评估
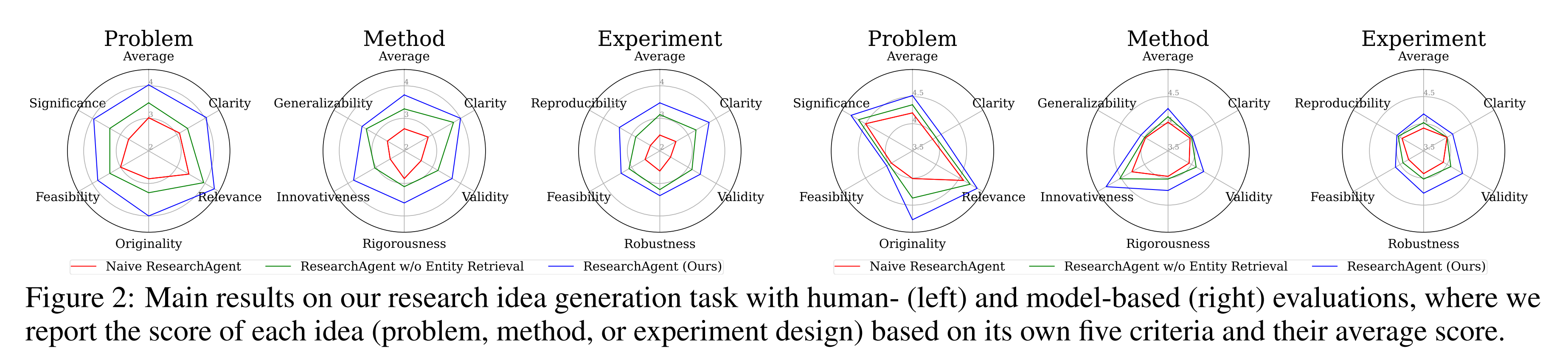
然后,我们要求评估模型对每个标准上生成的思路进行on a 5-point Likert scale的评分,或者在不同模型的两个思路之间进行两两比较
// 待更
1.3 ResearchAgent的三个完整示例
1.3.1 标题:用于零样本知识图问题回答的知识增强语言模型提示摘要
- 输入
标题:用于零样本知识图问题回答的知识增强语言模型提示摘要:大型语言模型(LLMs)能够根据它们在预训练期间存储在参数中的内部知识执行零样本闭书问题回答任务。 然而,这种内部化的知识可能是不足和不正确的,这可能导致LLMs生成错误的答案。 此外,对LLMs进行微调以更新它们的知识是昂贵的
为此,我们提出直接在LLMs的输入中增加知识
具体而言,我们根据问题和相关事实之间的语义相似性从知识图中检索与输入问题相关的事实。 然后,我们将检索到的事实以提示的形式添加到输入问题中,然后将其转发给LLMs生成答案
我们的框架,Knowledge-Augmented language model PromptING(KAPING),不需要模型训练,因此完全零样本。 我们在知识图问题回答任务上验证了我们的KAPING框架的性能,该任务旨在根据知识图上的事实回答用户的问题,在这方面,我们的方法在多个不同大小的LLMs上相对于相关的零样本基线平均提高了48%。
实体: ['自然语言', '学习管理系统', '问答', '维基百科', '人工智能', '命名实体识别', '质量保证', '长短期记忆', '英语', '谷歌图书', '自然语言编程', 'LMS颜色空间', 'GitHub', '逻辑学习机', '机器翻译', 'DBpedia', '集成图书馆系统', '西班牙语', '神经机器翻译', 'ArXiv', '人工通用智能', '自然语言理解', '非线性规划', 'Codex', 'LoRa', '粘合剂', 'Common Crawl', 'ROUGE(度量标准)', 'Transformer', 'Tomas Mikolov'] - 问题
开发一种多模态知识感知提示系统,用于跨结构化和非结构化数据源的多语言零-shot问答 - 方法
进一步改进和增强的方法,用于开发一种多模态知识感知提示系统,用于多语言零-shot问答(MMKP-ZSQA),包括以
下组件的先进改进,以满足创新性、清晰性和普适性的要求:
1. 互联的多模态知识编排(IMKO):
- IMKO是SMKI的先进演化,结合了最先进的语言和视觉模型,以处理具有上下文感知消歧方法的数据语言化。
- 在集成时,采用了注意机制等技术来衡量不同数据片段的相关性,揭示了文本和视觉数据在综合表示中如何相互增强。
2. 语言包容性检索引擎(LIRE):
- LIRE在EMKA的基础上扩展了语义理解,使用基于Transformer的模型在多样化的数据集上进行训练,包括跨语言的习
语和文化细微差别。
- 包括处理语言现象(如代码切换和音译)的特定算法,增强了应用于更广泛的语言和方言的能力。
3. 提示学习和优化交互(PLON):
- 在AMPL的基础上构建,PLON专注于创建一个按语言特征和数据模态分类的优化提示库,使用贝叶斯优化算法。
- 它包括领域自适应技术和更广泛的元学习策略,以及高资源和低资源语言的案例研究,并概述了它们实施的理论框架
4. 跨模态整合学习系统(C-MILS):
- C-MILS通过详细介绍跨模态的多头注意力在有效和可扩展的推理中的应用,以及每种模态如何协同增强理解能力的示
例,推进了SCAS的发展。
- 该组件现在包含了一个抽象层,将知识提炼成模态无关的格式,有助于推理并促进跨语言和数据类型的可解释性。
5. 用户中心自适应和隐私框架(UCAPF):
- UCAPF通过用户中心设计丰富了ALCUM,重点关注描述用户参与周期、反馈循环和隐私保护主动学习范例,提供了实
际工作流程和伪代码。
- 与GDPR和其他隐私框架保持一致,加强信任并解决动态学习环境中数据的道德使用问题。
6. 全球评估和反思测试系统(GERTS):
- GERTS通过提供多层次的验证和反思方法来调整基于各种指标的系统组件,包括公平性、偏见、可解释性和计算效率
- 提供了一种结构化的跨文化评估方法,包括在形成测试群体时使用人口统计和地区多样 - 实验设计
该实验名为“用于多模态知识感知的多语零样本问答系统的精细实验(RE-MKP-ZSQA)”,旨在系统地开发和验证先
进的人工智能系统。 该实验的流程经过简化,以解决可行性、清晰度和可重复性问题,并通过遵循以下精细阶段来保持
鲁棒性和有效性:
1. 详细的系统实施计划:
- 提供具体的里程碑、资源分配和时间表的公开可访问的项目路线图。
2. 具有明确指导方针的数据集策划:
- 发布精确的注释指导方针,并采取策略防止偏见。
- 记录数据集的组装过程,包括源选择和数据处理程序。
3. 透明系统训练:
- 提供详细的训练方案,包括超参数、优化策略和在PLON中使用的贝叶斯优化过程。
4. 结构化零样本评估:
- 概述基于GERTS的评估指标,用于测试零样本能力的基准数据集。
5. 更清晰的跨学科评估协议:
- 指定评估委员会的组成,评估标准和整合反馈的方法。
6. 通过验证指标进行迭代改进:
- 描述用于反思评估和持续改进的统计方法,与多层次的GERTS方法相一致。
7. 以用户为中心的设计和隐私合规评估:
- 结构化用户研究,以评估可用性和文化适应性的目标数据点。
- 概述遵守国际标准的隐私合规协议。
8. 详细的全球可扩展性评估方法:
- 定义可扩展性测试的评估指标,并描述不同的基础设施设置。
9. 增强的可重现性报告:
- 致力于创建一份详尽的报告,包括精确的规格、配置和复制指南。
- 利用GitHub进行代码和数据集的版本控制存储,利用arXiv公开获取实验方案和研究结果
1.3.2 用于问答的测试时自适应小语言模型
- 输入
标题:用于问答的测试时自适应小语言模型
摘要:最近,经过指令微调的大型语言模型(LMs)在各种任务中取得了显着的性能。 然而,尽管它们能够记忆大量的通用知识,但由于其有限的知识转移和适应目标任务的能力,它们在特定任务上可能不够优化。 此外,由于缺乏标记数据集,进一步微调LMs通常是不可行的,但我们也可以质疑是否可以将只具有有限知识的较小LMs与无标签的测试数据进行转移
在这项工作中,我们展示并研究了仅使用无标签测试数据的较小自适应LMs的能力。 特别地,我们首先随机
生成多个答案,然后在过滤掉低质量样本的同时将它们集成起来,以减轻来自不准确标签的噪声。 我们提出的自适应策
略在基准问答数据集上展示了显着的性能提升,具有更高的鲁棒性,使LMs保持稳定。
实体:['Codex','自然语言','英语','美国','问答','自然语言编程','GTRI信息与通信实验室','人工智能','LoRa','Llama','Python(编程语言)','学习管理系统','自然语言处理','强化学习','LMS颜色空间','维基百科','GitHub','自然语言理解','伦敦、中部和苏格兰铁路','集成图书馆系统','语言模型','中文','流明(单位)','西班牙语','英语维基百科','逻辑学习机','梯度下降','替代公开发行','技术转移','对话系统'] - 问题
开发一种可扩展的、适应领域的低资源语言问答测试时间训练协议,使用小型语言模型 - 方法
1. 选择可扩展的紧凑语言模型(CLMs):识别和评估适合适应的现有CLMs,重点考虑计算要求最小的模型
2. 创建多语言测试时间训练(TTT)框架:开发一个TTT协议,在推理阶段使CLMs能够适应新的领域和语言,利用无监督学习技术和伪标签生成
3. 合成和无监督数据生成:利用无监督和合成数据生成方法的组合,产生多语言问答对,采用反向翻译和基于上下文的问题合成等技术
4. 领域自适应机制:引入领域自适应组件,包括特征自适应层和元学习算法,以在测试时间将模型的行为调整到新的上下文和语言
5. 逐步语言添加和优势评估:从语言多样性和资源稀缺的子集开始。通过迭代过程评估每种语言的领域适应性,确保模型学会优先考虑资源效率。
6. 模型的鲁棒性和泛化性:进行鲁棒性调整(RT)以准备模型应对未知的语言变化,并在多个领域进行全面评估,以确保模型能够有效地泛化学习。
7. 人在循环评估:与母语人士和领域专家进行评估,验证问答输出的相关性和准确性,并将反馈纳入迭代训练过程中。
8. 开源和社区合作:将TTT协议、训练模型和评估基准公开提供给研究界,促进合作和进一步创新 - 实验设计
1. 选择和准备:
- 确定适合领域适应和测试时间训练的潜在紧凑语言模型(CLMs),重点关注计算要求最小且能够进行微调或无监督适
应的模型。
- 准备一组多样化的低资源语言和相应的文本语料库,确保语言多样性和社会文化重要性。 如果有的话,选择这些语言
的基准数据集。
2. 训练和适应过程:
- 创建一个测试时间训练(TTT)框架,允许选定的CLMs在推理阶段适应所选的低资源语言中的各种领域。
- 实施无监督学习技术和伪标签生成,利用反向翻译和基于上下文的问题合成为具有有限或无可用问答数据集的语言生
成合成数据集。
- 将领域自适应组件和元学习算法整合到CLMs中,以在测试时实现领域特定的适应性。
3. 迭代评估和改进:
- 从一个资源较少的语言开始适应和训练,并逐渐添加其他语言,在每次添加后监测领域适应性和模型性能指标。
- 对每个CLM和语言适应进行鲁棒性调优和跨领域评估,以确保泛化能力并防止过拟合。
4. 人机协同评估:
- 邀请母语人士和领域专家评估模型对每种语言的问答输出的相关性和准确性。
- 将反馈纳入迭代训练过程中,相应地改进和重新适应模型。
5. 开源和社区反馈:
- 将TTT协议、自适应CLMs、评估基准和任何合成数据集公开提供给研究社区。
6. 实验监控和文档记录:
- 详细记录所有参数、数据集、模型配置和评估指标,以确保鲁棒性和可重复性。
- 在实验过程中记录任何遇到的挑战、意外结果或适应性变化,以便进行开源目的。
7. 数据分析和报告:
- 使用适当的统计方法对收集到的性能数据进行定量分析,与非自适应基线进行比较。
- 报告人机交互评估的定性结果,解释对低资源语言领域中语言模型性能的影响
1.3.3 果蝇中整个大脑的注释和多连接组织细胞类型定量化研究
- 输入
标题:果蝇中整个大脑的注释和多连接组织细胞类型定量化研究
摘要:果蝇Drosophila melanogaster将令人惊讶的复杂行为与高度可追踪的神经系统相结合。 果蝇作为现代神经科学中的模式生物之一,其成功的一大部分源于协作生成的分子遗传学和数字资源的集中。 正如我们在FlyWire的伴随论文1中所介绍的,这现在包括成年动物的第一个完整的脑连接组
在这里,我们报告了这个包括神经元类、细胞类型和发育单元(半线)的130,000个神经元连接组的系统和分层注释。 这使得任何研究人员都可以浏览这个庞大的数据集,并通过Virtual Fly Brain数据库与文献进行关联。 关键是,这个资源包括4,552种细胞类型。其中3,094种是对先前在“半脑”连接组中提出的细胞类型的严格共识验证
此外,我们提出了1,458种新的细胞类型,主要是因为FlyWire连接组涵盖了整个大脑,而半脑来自一个子体积。 FlyWire和半脑的比较显示,细胞类型计数和强连接在很大程度上是稳定的,但连接权重在动物内部和动物之间变化很大。 进一步的分析确定了连接组解释的简单启发式方法:强度大于10个单元突触或为目标细胞提供>1%的输入的连接是高度保守的。 一些细胞类型在连接组中显示出更大的变异性:对于学习和记忆而言,蘑菇体中最常见的细胞类型在FlyWire中几乎是半脑的两倍。 我们发现通过调整兴奋性输入的绝对量来维持兴奋性和抑制性比例的功能稳态
最后,令人惊讶的是,在FlyWire连接组中,约三分之一的细胞类型在半脑连接组中尚无法可靠地识别。 因此,我们建议将细胞类型定义为对个体间变异具有稳健性的细胞群,即与同一大脑中的任何其他细胞相比,与不同大脑中的细胞更相似。 对FlyWire和半脑连接组的联合分析证明了这个新定义的可行性和实用性。 我们的工作为果蝇大脑定义了一个共识细胞类型图谱,并为大脑尺度的比较连接组学提供了一个知识框架和开源工具链。
实体:[’虚拟果蝇脑’, ’中枢神经系统’, ’可转座元件’, ’SUMO蛋白’, ’肯尼恩细胞’, ’罗姆人’, ’诱导干细胞’, ’腹神经索’, ’Fly
Base', '帕金森病', ’虚拟网络计算’, ’P元件’, ’Piwi相互作用RNA’, ’果蝇遗传参考面板’, ’贝茨-多布扬斯基-穆勒模型’, ’J. B. S.
Haldane’, ’ATG7’, '哈尔丹规则', ’牛津纳米孔技术’, ’毛里求斯果蝇’, ’生殖细胞系’, ’PINK1’, ’迁移性蝗虫’, ’CRISPR’, ’斑蝶
属’, ’GINS(蛋白质复合物)’, ’帕金酶(连接酶)’, ’鳞翅目’, ’Illumina, Inc.', ’果蝇’] - 问题
研究果蝇在不同环境和遗传背景下的学习和记忆回路的连接组变异的功能意 - 方法
所提出的方法采用多层次的方法,将连接组学、行为测定、基因操纵和计算建模相结合,研究果蝇学习和记忆回路的连接组变异的功能意义。 该方法包括以下步骤:
1. 连接组映射和变异分析:
a. 利用虚拟果蝇脑数据库识别和比较个体连接组,重点关注蘑菇体。
b. 利用统计方法和机器学习算法量化连接权重和细胞类型计数的变异,以识别变异模式。
2. 行为测定:
a. 为果蝇设计一系列学习和记忆任务,如嗅觉条件反射或视觉模式识别。
b. 在受控环境条件下测试具有已知连接组特征的果蝇群体,建立基线行为数据。
3. 环境和遗传扰动:
a. 将不同组的果蝇暴露在不同的学习范式和感觉输入下,以创建环境扰动。
b. 使用CRISPR-Cas9技术在基因中引入有针对性的突变,如PINK1或Parkin,从而创建遗传扰动。
c. 使用高分辨率成像和重建技术评估这些扰动对连接组结构的影响。
4. 转录组和空间分析:
a. 应用单细胞RNA测序和空间转录组学来描述对环境和遗传扰动的基因表达变化。
b. 将转录组数据与连接组变化相关联,以确定与结构和功能可塑性相关的分子途径。
5. 计算建模和网络分析:
a. 开发计算模型来模拟连接组变异对神经回路功能的影响。
b. 使用网络分析工具探索信息流和电路动力学,整合与嗅觉投射神经元和嗅觉系统信息流相关的论文数据。
6. 合成和验证:
a. 整合行为测定、连结组织图绘制、转录组分析和计算建模的发现。
b. 通过迭代实验和改进来验证提出的模型和假设 - 实验设计
1. 实验前设置:
a. 建立一个果蝇繁殖计划,以确保实验中供应一致的遗传相似的果蝇。
b. 制定一个标准化的果蝇饲养方案,以减少实验前的变异性。
c. 选择和验证CRISPR-Cas9构建物,用于靶向编辑PINK1、Parkin和其他感兴趣的基因。
d. 培训人员使用虚拟果蝇脑数据库和相关计算工具进行连结组织分析。
2. 连结组织图绘制和变异性分析:
a. 将单个果蝇随机分配到对照组和各种处理组(环境和遗传扰动)中。
b. 利用高分辨率成像技术绘制每个组中果蝇的连结组织图,重点关注蘑菇体。
c. 应用统计和机器学习算法来量化和比较连接权重和细胞类型计数在不同组之间的变异性。
3. 行为测验:
a. 设计和验证一系列学习和记忆任务,如嗅觉条件作用和视觉模式识别,确保任务对性能的微小差异敏感。
b. 在行为任务中测试每个组的果蝇并记录性能指标。
c. 分析行为数据以建立与连接组型的相关性。
4. 环境和遗传扰动:
a. 将果蝇暴露于不同的学习范式和感觉输入以诱导环境扰动。
b. 使用CRISPR-Cas9进行基因编辑,以在治疗组中创建遗传扰动。
c. 在扰动后重新映射连接组以评估结构变化。
5. 转录组和空间分析:
a. 从行为测验后收集果蝇的脑组织,并进行单细胞RNA测序和空间转录组学分析。
b. 分析转录组数据以识别基因表达变化,并将其与观察到的连接组和行为变异相关联。
6. 计算建模和网络分析:
a. 开发计算模型以模拟观察到的连接组变异对神经回路功能的影响。
b. 使用网络分析将行为、连接组和转录组数据整合起来,重点关注信息流和电路动力学。
7. 综合和验证:
a. 整合所有实验组件的发现,以形成对连接组变异功能影响的一致性理解。
b. 通过额外的有针对性的实验,根据初步发现进行模型验证和假设修正