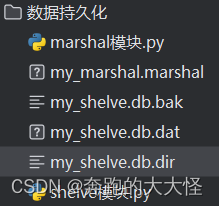
Marshal模块
1.是什么Marshal模块
Marshal是Python的一个内置模块,它提供了将Python对象序列化为字节流的功能,并允许将这些字节流保存到文件中或从文件中读取。序列化是指将对象转换为一种可以存储或传输的格式的过程,而反序列化则是将其恢复为原始对象的过程。
2.为什么要用Marshal模块
Marshal模块的主要目的是实现Python对象的持久化存储,以便在程序关闭后数据不会丢失,并在程序再次启动时能够重新加载这些数据。这对于保存程序状态、缓存数据或在不同程序之间共享数据非常有用。
3.Marshal模块的使用场景
Marshal模块通常用于简单的Python对象持久化,尤其是在Python的内部实现中。但由于其格式不是跨平台的,并且只支持Python特定的对象类型,因此在更广泛的应用场景中可能不是最佳选择。
4.代码实例
import marshal
# 保存对象
data = {'name': 'tom', 'age': 30}
with open('my_marshal.marshal', 'wb') as f:
marshal.dump(data, f)
# 从文件中读取对象
with open('my_marshal.marshal', 'rb') as f:
loaded_data = marshal.load(f)
# 输出: {'key': 'value'}
print(loaded_data)
Shelve模块
1.Shelve模块是什么
Shelve模块提供了一个简单的键值存储方案,它允许Python程序员以字典的方式存储持久化对象。Shelve模块内部使用了pickle模块来序列化对象,并将序列化的对象存储到文件中。
2.为什么要用Shelve模块
Shelve模块提供了一种更为方便和灵活的键值存储方式,使得程序员可以像操作字典一样来操作持久化数据。它简化了对象的存储和读取过程,并且支持存储复杂类型的Python对象。
3.Shelve模块的使用场景
Shelve模块适用于需要频繁存储和读取Python对象的情况,特别是在需要保存用户数据、缓存计算结果或在分布式系统中传输对象时。
4.代码实例
import shelve
u_dict = {'name': 'tom'} # 用户数据
s_dict = {'age': 30} # 学生信息
# 保存对象到shelve数据库
with shelve.open("my_shelve.db") as f:
f["user"] = u_dict
f['stu'] = s_dict
# 从shelve数据库读取对象
with shelve.open("my_shelve.db") as f:
s = f['stu']
print(s, type(s))
u = f['user']
print(u, type(u))
Marshal与Shelve之间的区别
格式与跨平台性:Marshal模块生成的格式是Python特有的,不是跨平台的;而Shelve模块内部使用pickle进行序列化,pickle是跨平台的,因此Shelve也具有跨平台性。
使用方式:Marshal模块直接操作字节流;而Shelve模块提供了一个类似字典的接口,使用上更为直观和方便。
支持的对象类型:Marshal模块主要支持Python的基本数据类型和一些内置类型;而Shelve模块则通过pickle支持几乎所有的Python对象类型。
安全性:由于Shelve使用pickle进行序列化,因此在安全性方面需要更加谨慎。不要反序列化来自不信任来源的数据,因为这可能导致安全问题。Marshal虽然格式简单,但也需要注意数据的来源和完整性。
两者生成文件的区别