2421. 好路径的数目
给你一棵
n个节点的树(连通无向无环的图),节点编号从0到n - 1且恰好有n - 1条边。给你一个长度为
n下标从 0 开始的整数数组vals,分别表示每个节点的值。同时给你一个二维整数数组edges,其中edges[i] = [a(i), b(i)]表示节点a(i)和b(i)( )之间有一条 无向 边。一条 好路径 需要满足以下条件:
开始节点和结束节点的值 相同 。
开始节点和结束节点中间的所有节点值都 小于等于 开始节点的值(也就是说开始节点的值应该是路径上所有节点的最大值)。
请你返回不同好路径的数目。
注意,一条路径和它反向的路径算作 同一 路径。比方说,
0 -> 1与1 -> 0视为同一条路径。单个节点也视为一条合法路径。示例 1:
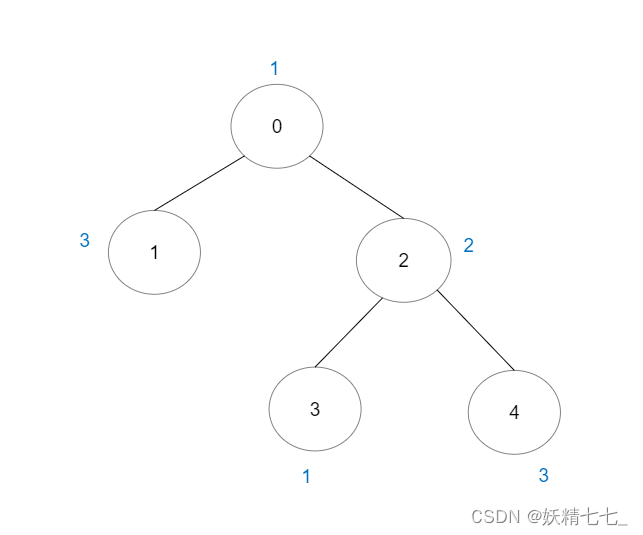
输入:vals = [1,3,2,1,3], edges = [[0,1],[0,2],[2,3],[2,4]] 输出:6 解释:总共有 5 条单个节点的好路径。 还有 1 条好路径:1 -> 0 -> 2 -> 4 。 (反方向的路径 4 -> 2 -> 0 -> 1 视为跟 1 -> 0 -> 2 -> 4 一样的路径) 注意 0 -> 2 -> 3 不是一条好路径,因为 vals[2] > vals[0] 。
示例 2:
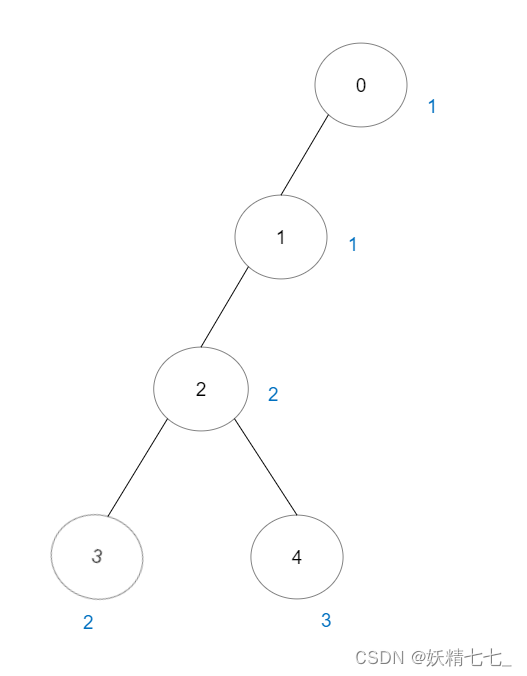
输入:vals = [1,1,2,2,3], edges = [[0,1],[1,2],[2,3],[2,4]] 输出:7 解释:总共有 5 条单个节点的好路径。 还有 2 条好路径:0 -> 1 和 2 -> 3 。
示例 3:
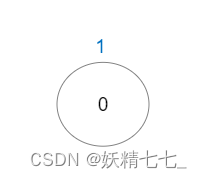
输入:vals = [1], edges = [] 输出:1 解释:这棵树只有一个节点,所以只有一条好路径。
提示:
n == vals.length
1 <= n <= 3 * 10(4)
0 <= vals[i] <= 10(5)
edges.length == n - 1
edges[i].length == 2
0 <= a(i), b(i) < n
a(i) != b(i)
edges表示一棵合法的树。
1.
对于所有的边元素,我们可以得到他max的vals的值,并且可以构造一个max数组一一对应.
max进行排序,从小到大排序,并且是绑定下标进行排序.
这样我们就可以按照元素的max信息顺序进行访问元素本身.
2.
对于每一个边,如果两个点的最大值是不一样的,那么肯定不是好路径.
如果两个点的最大值是一样的,那么好路径的个数是两个点所在集合元素个数相乘,然后这两个结合合并.
class Solution {
public:
vector<int> vals;//每一个点的值
vector<vector<int>> edges;//每一个边信息
int ret;//存储结果
using p = pair<int, int>;//定义pair
vector<p> max_edge;//为了绑定max和下标一起排序
int n;//点的个数
struct node {//存储所有元素对于的其他的信息
int max;//存储集合最大值信息
int size;//存储集合最大值个数信息
int father;//并查集核心部分
};
vector<node> vec;//所有元素对应的其他的信息
vector<int> st;//用vector模拟栈
int _find(int i) {//并查集中找i下标对应集合的代表元素的下标
while (!(i == vec[i].father)) {//当前节点是i,出口时i=vec[i].father
st.push_back(i);//用栈存储走过的路
i = vec[i].father;//进入下一节点的操作
}
while (st.size()) {//将所有走过的路的father直接设置为集合代表元素的下标
//扁平化处理
vec[st.back()].father = i;
st.pop_back();
}
return i;
}
bool isSameSet(int x, int y) { return _find(x) == _find(y); }//判断是否是同一个集合
void _union(int x, int y) {//将两个集合进行合并
if (_find(x) == _find(y))
return;
else {
int rx = _find(x);
int ry = _find(y);
int maxx = vec[rx].max;
int maxy = vec[ry].max;
if (maxx == maxy)//如果最大值是一样的,那么最大值的个数相加
vec[ry].size = vec[rx].size + vec[ry].size;
else if (maxx > maxy)//如果最大值不是一样的,只需要考虑这一种情况,修改ry的size
vec[ry].size = vec[rx].size;
vec[ry].max = max(vec[rx].max, vec[ry].max);
vec[rx].father = vec[ry].father;
}
}
void init() {//正式解题操作之前的初始化操作
n = edges.size();
for (int i = 0; i < n; i++) {
max_edge.push_back({max(vals[edges[i][0]], vals[edges[i][1]]), i});
//vector中绑定max值和下标,一起排序
}
sort(max_edge.begin(), max_edge.end(),
[](const auto& a, const auto& b) { return a.first < b.first; });
//sort的lambda写法
//第三个参数直接以函数的信息写出来了
//关注于第三个参数,直接使用auto,用于判断a是否位于b的前面
//pair中first存储的是max信息
vec.clear(), vec.resize(vals.size());
for (int i = 0; i < vals.size(); i++) {//初始化vec信息
vec[i].father = i;
vec[i].max = vals[i];
vec[i].size = 1;
}
}
void solve() {//正式开始解题步骤
for (int i = 0; i < max_edge.size(); i++) {
int id = max_edge[i].second;//找到边的下标
int id1, id2;
id1 = edges[id][0];//找边的两个点
id2 = edges[id][1];
int max_id1 = vec[_find(id1)].max;
int max_id2 = vec[_find(id2)].max;
if (max_id1 == max_id2) {//如果最大值是一样的,维护ret
ret += vec[_find(id1)].size * vec[_find(id2)].size;
_union(id1, id2);
} else {//如果不是一样的
_union(id1, id2);
}
}
ret += vals.size();//最后不要忘记了ret需要加入没一个独立的点
}
int numberOfGoodPaths(vector<int>& _vals, vector<vector<int>>& _edges) {
vals = _vals;
edges = _edges;
init();
solve();
return ret;
}
};928. 尽量减少恶意软件的传播 II
给定一个由
n个节点组成的网络,用n x n个邻接矩阵graph表示。在节点网络中,只有当graph[i][j] = 1时,节点i能够直接连接到另一个节点j。一些节点
initial最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。假设
M(initial)是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。我们可以从
initial中删除一个节点,并完全移除该节点以及从该节点到任何其他节点的任何连接。请返回移除后能够使
M(initial)最小化的节点。如果有多个节点满足条件,返回索引 最小的节点 。示例 1:
输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] 输出:0
示例 2:
输入:graph = [[1,1,0],[1,1,1],[0,1,1]], initial = [0,1] 输出:1
示例 3:
输入:graph = [[1,1,0,0],[1,1,1,0],[0,1,1,1],[0,0,1,1]], initial = [0,1] 输出:1
提示:
n == graph.length
n == graph[i].length
2 <= n <= 300
graph[i][j]是0或1.
graph[i][j] == graph[j][i]
graph[i][i] == 1
1 <= initial.length < n
0 <= initial[i] <= n - 1
initial中每个整数都不同
1.
解题的思路,首先有许多个点,有毒点有正常点.
把所有的正常点相互连接的部分合并成一个集合.
遍历所有的毒点,访问所有的与毒点相连的集合,给这个集合打上标签,这个标签是这个集合与之相连的毒点.
因此这个标签实际上可能有多个,也可有可能只有一个,或者没有.
最后搞一个count数组对应所有的毒点,遍历所有的集合,如果该集合的标签只有一个,那么对应的count加上该集合的所有元素.
遍历count找到最大的count值并且找到下标,通过下标找到对应毒点的下标.
2.
需要注意的一点是,如果count值相等,需要返回较小值的毒点下标.
因此我们提前将it数组进行排序.
class Solution {
public:
vector<vector<int>> g;//图的临界矩阵的存储方式
vector<int> it;//毒点的下标,位置
int ret;//最终结果存储遍历
int n;//邻接矩阵的端点个数,也就是有多少个点
struct node {//给每一个点,元素绑定一些信息,通过下标绑定所有的元素和元素对应的信息
int father;//每一个元素的father下标,并查集的核心
set<int> point_yuan;//每一个元素的毒点信息,实际上只需要关心集合头元素的该信息即可
int size;//集合的元素个数
};
map<int, int> point_yuan_index;//将元素和下标进行映射,这样我们就可以通过元素找到对应的下标进而找到对应的所有的信息
vector<node> v;//v表示所有元素对应的信息
vector<int> st;//用vector模拟栈的实现,用于对并查集进行扁平化处理
set<int> setnum;//set容器进行去重操作,存储所有的集合代表元素,代表元素的下标
vector<int> count;//对应所有毒点的count,表示每一个毒点如果删去可以拯救的点的个数
int _find(int i) {//并查集中查找的方法
while (!(i == v[i].father)) {//当前节点是i位置,出口时i==v[i].father
st.push_back(i);//对于每一个访问的下标进行存储,用栈存储走过的路
i = v[i].father;//进入下一节点的操作
}
while (!st.empty()) {//对于所有走过的路,修改其father直接改为i位置,此时i是集合的代表元素的下标
v[st.back()].father = i;
st.pop_back();
}
return i;
}
void _union(int x, int y) {//集合的合并操作
int rx = _find(x), ry = _find(y);//首先计算x下标,y下标所在集合的代表元素下标
if (rx == ry)//如果所在集合一样就不需要合并
return;
else {//如果所在集合不一样就需要合并
v[ry].size += v[rx].size;//对于每一个集合需要维护的信息是father和size信息
//首先维护size信息,合并之后集合代表元素的下标是ry
//所以需要改变ry的size信息
v[rx].father = ry;
}
}
void init() {//初始化函数,解题之前的必要操作
sort(it.begin(), it.end());//首先给it进行排序
n = g.size();//计算点的个数
v.clear(), v.resize(n);//对元素信息进行分配空间
for (int i = 0; i < n; i++) {
v[i].father = i;//初始化father
v[i].size = 1;//初始化size
}
for (int i = 0; i < it.size(); i++) {
point_yuan_index[it[i]] = i;//毒点与下标建立映射
}
count.clear(), count.resize(it.size());
ret = it[0];//一开始ret存储it第一个毒点的位置
}
void solve() {//正式开始解题过程
for (int i = 0; i < n; i++) {//首先合并所有正常点
for (int j = i + 1; j < n; j++) {
if (g[i][j] == 1 && !point_yuan_index.count(i) &&
!point_yuan_index.count(j))
_union(i, j);//如果i,j都是正常点,并且ij之间有边,那么就合并在一起
}
}
for (int i = 0; i < it.size(); i++) {//给所有的集合打标签
int id = it[i];//找到毒点对于的下标
for (int j = 0; j < n; j++) {
if (id == j)
continue;
if (g[id][j] == 1) {
v[_find(j)].point_yuan.insert(id);//set容器进行去重操作
}
}
}
for (int i = 0; i < n; i++) {//用set容器存储所有的集合的代表元素下标
if (!point_yuan_index.count(i))//不考虑毒点
setnum.insert(_find(i));
}
for (auto& x : setnum) {//遍历所有的集合点
if (v[x].point_yuan.size() > 1)
continue;
else if (v[x].point_yuan.size() == 1) {//如果毒点连接只有一个,那么对于毒点的count值加上该集合的元素个数
int id = point_yuan_index[*v[x].point_yuan.begin()];
count[id] += v[x].size;
}
}
int maxnum = 0;
for (int i = 0; i < count.size(); i++) {//最后遍历count数组,找到最大值对应的毒点位置
if (count[i] > maxnum) {
maxnum = count[i];
ret = it[i];
}
}
}
int minMalwareSpread(vector<vector<int>>& _graph, vector<int>& _initial) {
g = _graph, it = _initial;
init();
solve();
return ret;
}
};
结尾
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!



![[路由器]<span style='color:red;'>IP</span>-MAC<span style='color:red;'>的</span><span style='color:red;'>绑</span><span style='color:red;'>定</span><span style='color:red;'>与</span>取消](https://i-blog.csdnimg.cn/direct/600fa85e7b6448428d91d8a64b24fb31.png)

















![Milvus向量数据库(一)Milvus存储byte[]类型源向量数据](https://img-blog.csdnimg.cn/direct/d29a2ae1ca3949f8922855ff24a88938.png)