C++堆结构与堆排序深度解析
目录
1. 堆的概念
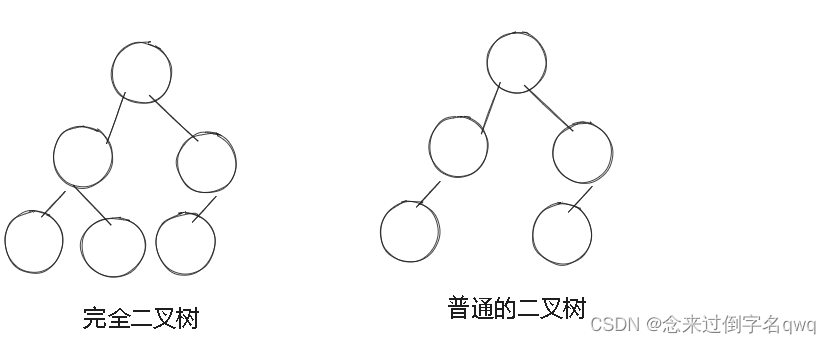
在计算机科学中,堆是一种特殊的完全二叉树数据结构,它满足堆属性:即在堆的任意节点,其值都小于或等于(在小顶堆中)或大于或等于(在大顶堆中)其子节点的值。这种属性使得堆常用于实现优先队列,其中每个元素都有一个优先级。
2. 堆的实现
堆可以通过数组来实现,其中索引`i`的元素的子节点分别是`2i + 1`和`2i + 2`,父节点则是`(i - 1) / 2`。由于堆是一个完全二叉树,它可以在不使用额外的指针的情况下在数组中表示。
3. 堆化过程
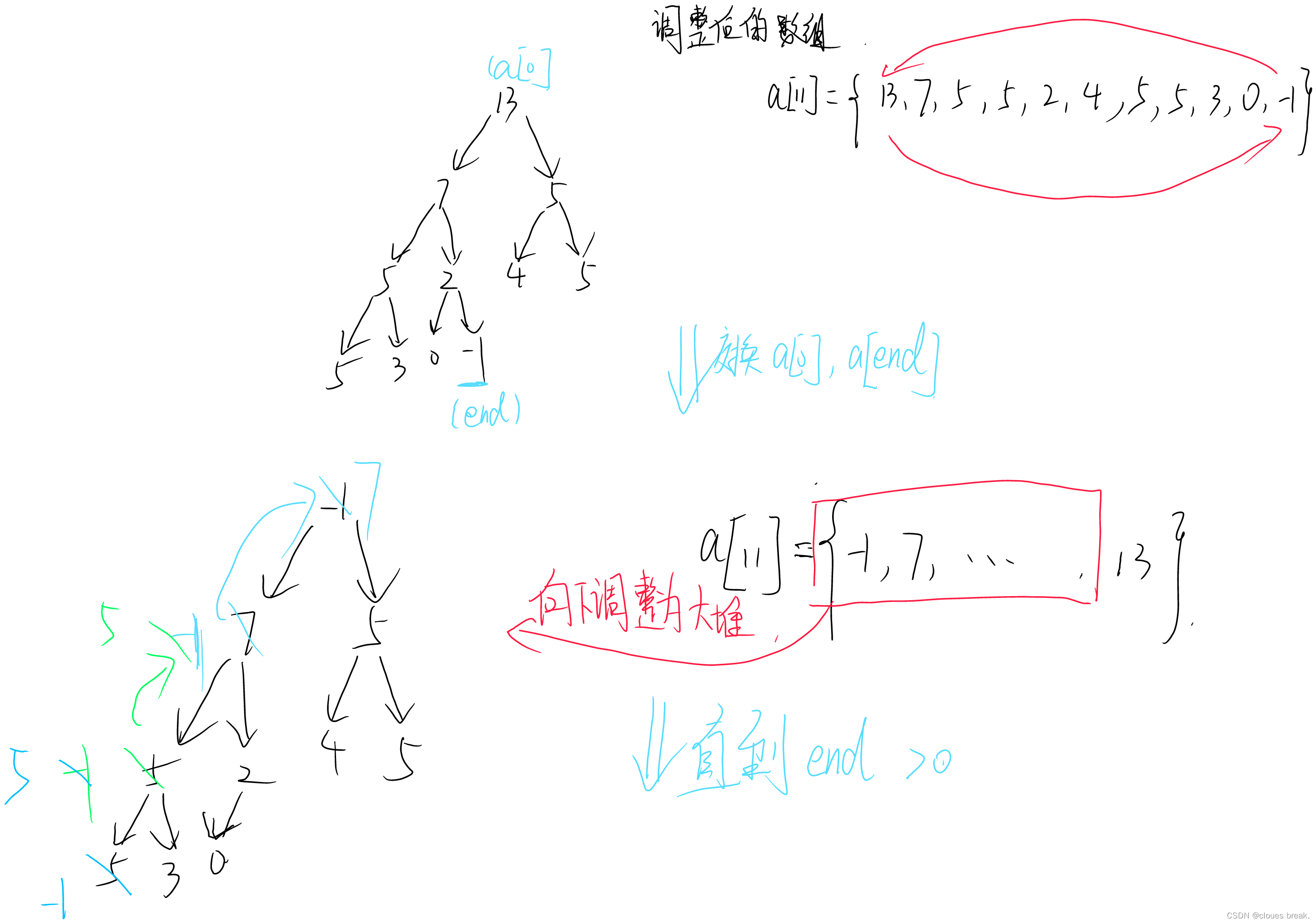
堆化是将一个无序的数组转换为堆的过程。这通常通过从最后一个非叶子节点开始,逐个向上调整每个节点来完成。这个过程称为“下沉”。
3.1 从底到顶的大顶堆构建
从底到顶的构建过程中,我们从最后一个非叶子节点开始,对每个节点执行下沉操作,直到根节点被处理。
void heapify_bottom_to_top(int arr[], int n, int i) {
int largest = i; // 初始化最大值为根节点
int left = 2 * i + 1;
int right = 2 * i + 2;
// 如果左子节点存在且大于当前最大值
if (left < n && arr[left] > arr[largest])
largest = left;
// 如果右子节点存在且大于当前最大值
if (right < n && arr[right] > arr[largest])
largest = right;
// 如果最大值不是根节点
if (largest != i) {
std::swap(arr[i], arr[largest]);
// 递归调整子树
heapify_bottom_to_top(arr, n, largest);
}
}
```
3.2 从顶到底的大顶堆构建
从顶到底的构建过程中,我们从根节点开始,对每个节点执行下沉操作,直到达到最后一个非叶子节点。
void heapify_top_to_bottom(int arr[], int n, int i) {
int largest = i; // 初始化最大值为根节点
int left = 2 * i + 1;
int right = 2 * i + 2;
// 如果左子节点存在且大于当前最大值
if (left < n && arr[left] > arr[largest])
largest = left;
// 如果右子节点存在且大于当前最大值
if (right < n && arr[right] > arr[largest])
largest = right;
// 如果最大值不是根节点
if (largest != i) {
std::swap(arr[i], arr[largest]);
// 递归调整子树
heapify_top_to_bottom(arr, n, largest);
}
}
```
4. 堆排序算法
堆排序是一种基于比较的排序算法,它利用了堆这一数据结构的特性。堆排序可以看作是选择排序的一种改进,它的时间复杂度为O(n log n)。
4.1 基本步骤
1. 将输入的数据构造成一个大顶堆。
2. 交换堆顶元素与最后一个元素,然后将堆的大小减1。
3. 对新的堆顶元素执行下沉操作,以维持大顶堆的性质。
4. 重复步骤2和3,直到堆的大小为1。
4.2 代码示例
void heapSort(int arr[], int n) {
// 构建大顶堆
for (int i = n / 2 - 1; i >= 0; i--)
heapify_bottom_to_top(arr, n, i);
// 一个个从堆顶取出元素
for (int i = n - 1; i >= 0; i--) {
std::swap(arr[0], arr[i]);
heapify_bottom_to_top(arr, i, 0);
}
}
```
5. 优化策略
5.1 迭代优化
在构建堆的过程中,我们可以使用迭代而不是递归来减少函数调用的开销。这可以通过使用循环和栈来实现。
5.2 尾递归优化
在某些编程语言中,尾递归可以被编译器优化以避免额外的内存消耗。虽然C++不保证这一点,但将递归调用放在函数的末尾可以提高某些编译器的优化机会。
5.3 空间优化
由于堆是通过数组实现的,我们可以避免使用额外的数据结构,从而减少内存使用。
6. 性能分析
堆排序的平均和最坏情况时间复杂度都是O(n log n)。由于堆排序是原地排序,它的空间复杂度为O(1)。这使得堆排序在空间受限的环境中非常有吸引力。然而,由于其较大的常数因子,它在实践中可能不如快速排序或归并排序快。
7. 最佳实践
- 选择合适的堆类型:根据应用场景选择小顶堆还是大顶堆。
- 避免频繁的堆调整:在可能的情况下,尽量减少对堆的调整次数。
- 考虑其他排序算法:如果数据量不大或者有特殊需求,可以考虑其他更适合的排序算法。




















![Milvus向量数据库(一)Milvus存储byte[]类型源向量数据](https://img-blog.csdnimg.cn/direct/d29a2ae1ca3949f8922855ff24a88938.png)