目录
二 使用SCINet助力YOLOv8在黑暗环境的目标检测效果
一 SCINet
官方论文地址:https://arxiv.org/pdf/2204.10137
官方代码地址:GitCode - 开发者的代码家园

现有的弱光图像增强技术不仅难以处理视觉质量和计算效率问题,而且在未知的复杂场景下通常无效。在本文中,提出了一种新的自校准照明(SCI)学习框架,用于在现实世界低光场景下快速,灵活和鲁棒的增亮图像。具体来说,建立了一个具有权重共享的级联照明学习过程来处理这个任务。作者考虑到级联模式的计算负担,构建了自校准模块,实现了各阶段结果之间的收敛,产生了仅使用单个基本块进行推理的增益(但在以往的工作中尚未被利用),大大降低了计算成本。然后,定义了无监督训练损失,以提高模型适应一般场景的能力。进一步,进行了全面的探索,挖掘SCI的固有属性(现有作品所缺乏的),包括操作不敏感的适应性。最后,大量的实验和消融研究充分表明了这一方法在质量和效率上的优势。在微光人脸检测和夜间语义分割等方面的应用充分显示了该方法潜在的实用价值。
在本文中,成功地建立了一个轻量级而有效的框架,即自校准照明(SCI),用于针对不同现实场景的低光图像增强。不仅对SCI的优良特性进行了深入的探索,还进行了大量的实验,证明了在弱光图像增强、暗人脸检测、夜间语义分割等方面的有效性和优越性。
1 本文方法
① 权重共享的照明学习
建立了一个具有权重共享的级联照明学习过程来处理低照度图像增强的任务。各个阶段共享权重。
② 自校准模块
构建了自校准模块,减少计算负担,实现了各阶段结果之间的收敛,产生了仅使用单个基本块进行推理的增益。
③ 无监督训练损失
定义了无监督训练损失,以提高模型适应一般场景的能力。
下图为SCI的整个框架。在训练阶段,SCI由照度估计和自校准模块组成。将自校准的模块映射添加到原始低照度输入中,作为下一阶段照度估计的输入。注意,这两个模块在整个训练过程中分别是共享参数。在测试阶段,只使用单个照明估计模块。权重共享的照明学习和自校准模块的设计为减少计算量并且提升结果的稳定性。

下图为比较是否使用自校准模块时各阶段结果的t-SNE[21]分布。这说明了为什么可以使用单级进行测试,即SCI中每级的结果都可以快速收敛到相同的值,而w/o自校准模块却无法始终实现这一点。

以下为各方法对比结果:


二 使用SCINet助力YOLOv8在黑暗环境的目标检测效果
整个结构的示意图如下所示:

1 整体修改
① 添加SCINet.py文件
在ultralytics/nn/modules目录下新建SCINet.py文件,文件的内容如下:
import torch
import torch.nn as nn
__all__ = ['EnhanceNetwork']
class EnhanceNetwork(nn.Module):
def __init__(self, layers, channels):
super(EnhanceNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.ReLU()
)
self.conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.conv)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
illu = fea + input
illu = torch.clamp(illu, 0.0001, 1)
return illu
class CalibrateNetwork(nn.Module):
def __init__(self, layers, channels):
super(CalibrateNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.layers = layers
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.convs = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.convs)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
delta = input - fea
return delta
class Network(nn.Module):
def __init__(self, stage=3):
super(Network, self).__init__()
self.stage = stage
self.enhance = EnhanceNetwork(layers=1, channels=3)
self.calibrate = CalibrateNetwork(layers=3, channels=16)
self._criterion = LossFunction()
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
ilist, rlist, inlist, attlist = [], [], [], []
input_op = input
for i in range(self.stage):
inlist.append(input_op)
i = self.enhance(input_op)
r = input / i
r = torch.clamp(r, 0, 1)
att = self.calibrate(r)
input_op = input + att
ilist.append(i)
rlist.append(r)
attlist.append(torch.abs(att))
return ilist, rlist, inlist, attlist
def _loss(self, input):
i_list, en_list, in_list, _ = self(input)
loss = 0
for i in range(self.stage):
loss += self._criterion(in_list[i], i_list[i])
return loss
class Finetunemodel(nn.Module):
def __init__(self, weights):
super(Finetunemodel, self).__init__()
self.enhance = EnhanceNetwork(layers=1, channels=3)
self._criterion = LossFunction()
base_weights = torch.load(weights)
pretrained_dict = base_weights
model_dict = self.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
i = self.enhance(input)
r = input / i
r = torch.clamp(r, 0, 1)
return i, r
def _loss(self, input):
i, r = self(input)
loss = self._criterion(input, i)
return loss
② 修改ultralytics/nn/tasks.py文件
具体的修改内容如下图所示:

修改parse_model函数的内容如下所示:

2 配置文件
yolov8_SCINet.yaml 的内容与原版对比:

3 训练
上述修改完毕后,开始训练吧!🌺🌺🌺🌺🌺🌺
训练示例:
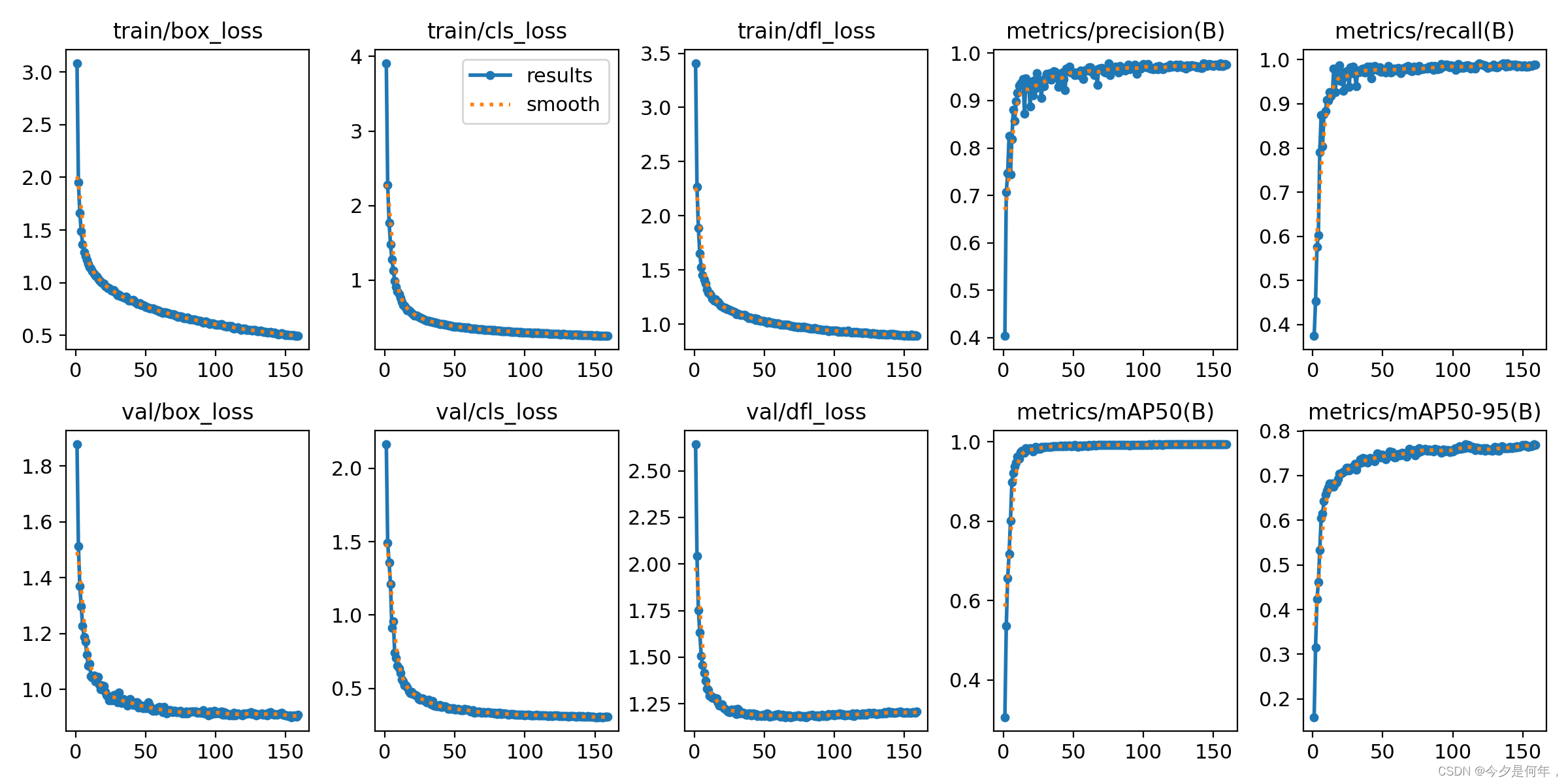
yolo task=detect mode=train model=cfg/models/v8/yolov8_SCINet.yaml data=cfg/datasets/coco128.yaml epochs=200 batch=16 device=cpu project=yolov8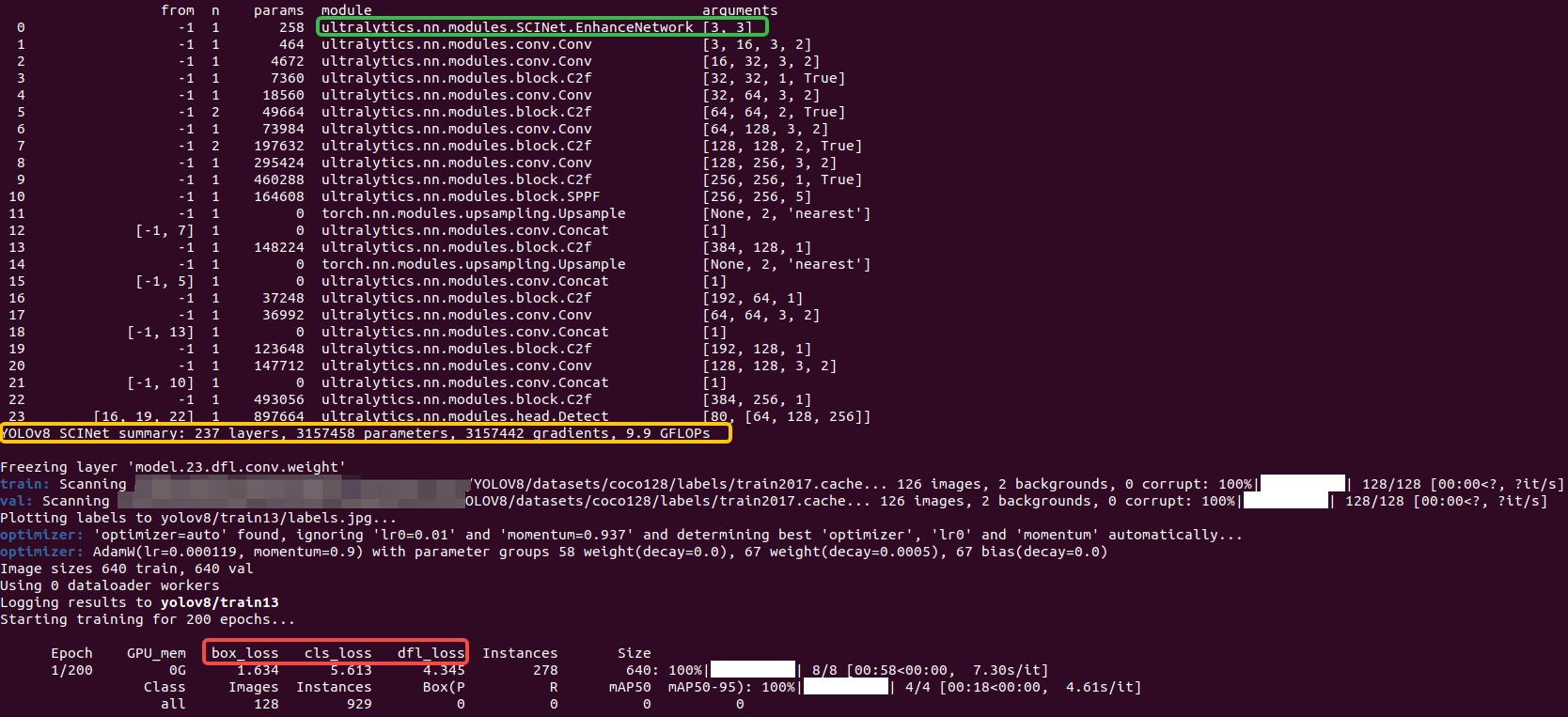
其他
说明:私信问题,不回答了哈,有问题可以评论,会随缘回答哈。希望理解哈!💛 💙 💜 ❤️ 💚 💛 💙 💜 ❤️ 💚
到此,本文分享的内容就结束啦!遇见便是缘,感恩遇见!!!💛 💙 💜 ❤️ 💚




![【<span style='color:red;'>YOLOv</span><span style='color:red;'>8</span><span style='color:red;'>改进</span>[CONV]】2024<span style='color:red;'>的</span>DynamicConv助力<span style='color:red;'>YOLOv</span><span style='color:red;'>8</span><span style='color:red;'>目标</span><span style='color:red;'>检测</span><span style='color:red;'>效果</span> + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/8f68a72128f14b169d778e563b93c5f0.png)



















![[ARM系列]coresight(一)](https://img-blog.csdnimg.cn/direct/fcee3f25569747088e774c701be867d0.png)











![[MRCTF2020]Ez_bypass1](https://img-blog.csdnimg.cn/direct/9d4d010780bd411faba1fa7ba31f7449.png)