文章目录
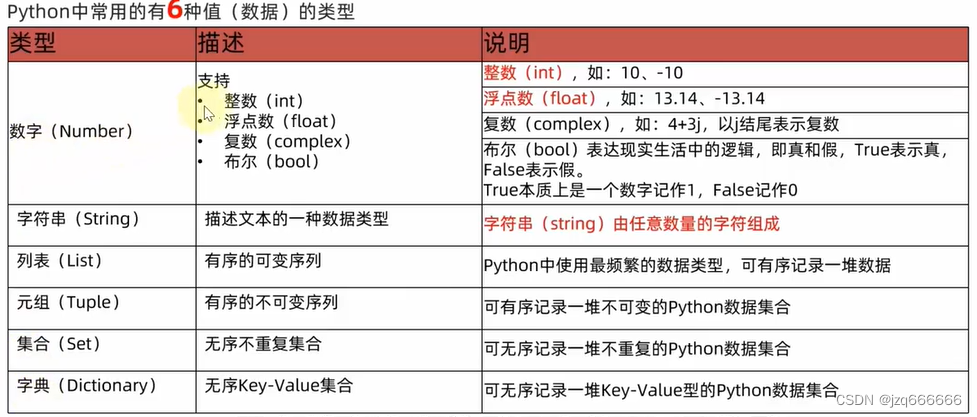
数值
- 整数(int):
- 表示整数,可以是正数、负数或零,通过不同的前缀还可以区分为二进制,八进制,十进制(默认),十六机制。
x = 5(默认十进制)x = 0b0101二进制x = 0o005八进制x = 0x005十六进制
- 浮点数(float):
- 表示有小数点的数字。
y = 3.14- 有时候浮点数表达式的计算可能不准确
- 布尔值(bool):
- 表示逻辑值,只有两个取值:True和False,一般情况下,非空和非零的值等价True,为空为零的值等价False。
is_true = True- 布尔值为False:False、整数0、浮点数0.0、None、空字符串、空列表、空元组、空字典、空集合
- 空值(NoneType):
- 表示一个特殊的空值,通常用于表示变量未赋值或函数没有返回值。
x = None
列表
列表的基本概念:
使用方括号
[]来表示列表,列表中的元素用逗号,分隔。列表是一种可以包含不同类型元素的数据结构,这意味着列表中可以有整数、浮点数、字符串、甚至是其他列表或者不同的类型数据结构等等。
my_list = [10, 3.14, "Hello", True, [1, 2, 3], {'name': 'Alice', 'age': 30}] print(my_list[0]) # 访问第一个元素,整数类型 print(my_list[1]) # 访问第二个元素,浮点数类型 print(my_list[2]) # 访问第三个元素,字符串类型 print(my_list[3]) # 访问第四个元素,布尔类型 print(my_list[4]) # 访问第五个元素,另一个列表类型 print(my_list[5]) # 访问第六个元素,字典类型列表是一种有序的数据结果,每一个元素都映射一个索引,列表中的元素可以通过索引来访问,可以使用正向索引(从左往右数,从 0 开始)和负向索引(从右往左数,从 -1 开始)来访问列表中的元素。
# 定义一个包含一些元素的列表 my_list = ['apple', 'banana', 'orange', 'grape', 'melon'] # 使用索引访问列表中的元素 first_fruit = my_list[0] # 第一个元素,'apple' second_fruit = my_list[1] # 第二个元素,'banana' last_fruit = my_list[-1] # 最后一个元素,'melon'列表是一种可变的数据结构,即可以通过索引来修改、添加或删除其中的元素,列表的长度和元素的值都可以发生变化。
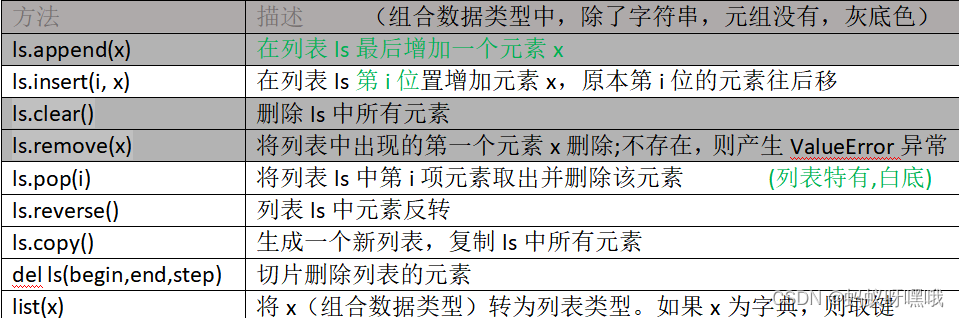
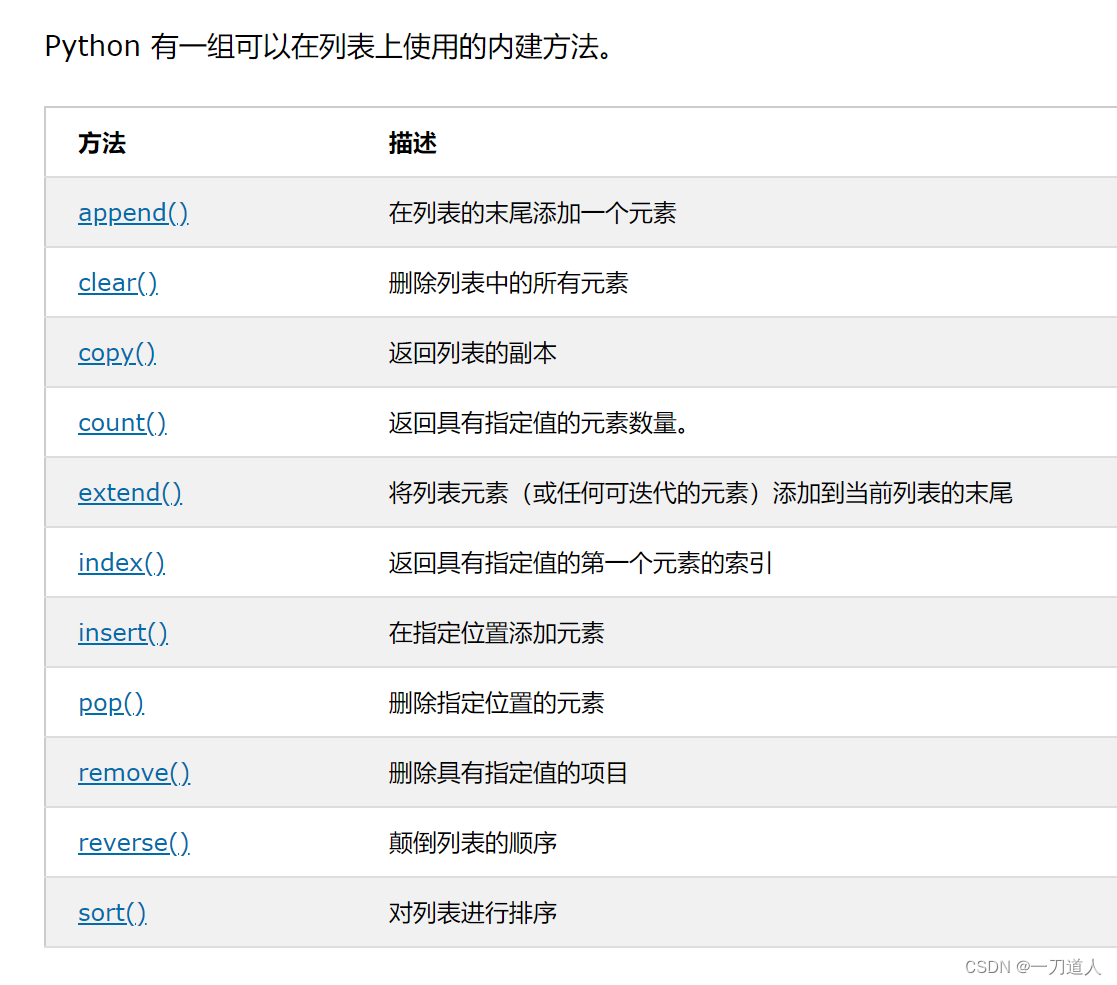
列表的常用方法和操作:
- 列表具有丰富的方法和操作,例如:
append()、insert()、remove()、pop()、extend()、sort()、reverse()等等。 - 这些方法可以用来在列表中添加、删除、修改元素,或者对列表进行排序、翻转等操作。
append():
append()方法用于在列表末尾添加一个元素,可以添加整个列表、词典等。语法:
list.append(element)参数:
element- 要添加到列表末尾的元素。示例:
my_list = [1, 2, 3] my_list.append(4) print(my_list) # 输出:[1, 2, 3, 4] my_list.append([1, 2, 3]) print(my_list) # 输出:[1, 2, 3, 4, 1, 2, 3]
extend():
extend()方法用于将另一个列表中的所有元素添加到当前列表的末尾。使用+也可完成此操作语法:
list.extend(iterable)参数:
iterable- 可迭代对象,如列表、元组、集合等。示例:
my_list = [1, 2, 3] another_list = [4, 5, 6] my_list.extend(another_list) print(my_list) # 输出:[1, 2, 3, 4, 5, 6]
insert():
insert()方法用于在指定索引位置插入一个元素,可以添加整个列表、词典等。语法:
list.insert(index, element)参数:
index- 要插入元素的索引位置,element- 要插入的元素。示例:
my_list = [1, 2, 3] my_list.insert(1, 1.5) print(my_list) # 输出:[1, 1.5, 2, 3] my_list.insert(1, [1, 2]) print(my_list) # 输出:[1, [1, 2], 1.5, 2, 3]
remove():
remove()方法用于删除列表中指定的元素(第一个匹配的元素)。语法:
list.remove(element)参数:
element- 要删除的元素。示例:
my_list = [1, 2, 3, 2, 4] my_list.remove(2) print(my_list) # 输出:[1, 3, 2, 4]
pop():
pop()方法用于删除并返回列表中指定位置的元素。语法:
list.pop([index])参数:
index(可选) - 要删除的元素的索引,默认为最后一个元素。返回值:返回被删除的元素。
示例:
my_list = [1, 2, 3] popped_element = my_list.pop(1) print(popped_element) # 输出:2 print(my_list) # 输出:[1, 3] # 使用这个也可以实现 del my_list[0] print(my_list) # 输出:[3]
sort():
sort()方法用于对列表进行排序。语法:
list.sort(key=None, reverse=False)参数:
key(可选) - 指定一个函数用于从每个列表元素中提取比较键,默认为 None(直接比较元素本身)reverse(可选) - 如果为 True,则按降序排序。
示例:
my_list = [3, 1, 2] my_list.sort() print(my_list) # 输出:[1, 2, 3]
reverse():
reverse()方法用于反转列表中的元素顺序。语法:
list.reverse()示例:
my_list = [1, 2, 3] my_list.reverse() print(my_list) # 输出:[3, 2, 1]
列表的迭代和遍历:
可以使用
for循环来遍历列表中的元素,也可以使用列表推导式等方式进行迭代操作。通过循环遍历列表,可以对列表中的每个元素进行处理,或者对列表进行相应的操作。
# 创建一个包含元素的列表 my_list = [1, 2, 3, 4, 5] # 使用 for 循环遍历列表中的元素并打印 for element in my_list: print(element)
列表的内部实现原理:
- 在 Python 中,列表通常是通过动态数组来实现的,即在内存中分配一块连续的空间来存储列表中的元素。
- 当列表中的元素数量超过当前分配空间时,Python 会自动分配更大的空间,并将元素复制到新的空间中,以保证列表的可变性和性能。
不对二维和多维列表做讲述
字典
字典的基本概念:
字典是一种键值对(key-value)的数据结构,每个元素都由一个键和一个对应的值组成。键必须是唯一的,但值可以重复。
字典是无序的,即没有按照元素添加的顺序来存储和访问元素。
字典是可变的,可以通过键来引用、添加、修改或删除其中的元素。
# 定义一个字典包含个人信息 person_info = { 'name': 'Alice', 'age': 30, 'address': '123 Main St' } # 将元素赋值给另一个变量 new_var = person_info['address'] # 添加新的元素 person_info['email'] = 'alice@example.com' # 修改元素 person_info['age'] = 31 # 删除元素 del person_info['address']使用大括号
{}来表示字典,键值对之间用冒号:分隔,冒号:左侧是键,右侧是值,每键值对之间用逗号,分隔。
字典的常用方法和操作:
- 字典具有丰富的方法和操作,例如:
keys()、values()、items()、get()、pop()、update()等等。 - 这些方法可以用来获取字典中的键、值、键值对,或者对字典进行添加、删除、更新等操作。
keys():
keys()方法用于获取字典中所有的键。语法:
dict.keys()返回值:返回一个包含字典所有键的可迭代对象。
示例:
my_dict = {'a': 1, 'b': 2, 'c': 3} print(my_dict.keys()) # 输出:dict_keys(['a', 'b', 'c'])
values():
values()方法用于获取字典中所有的值。语法:
dict.values()返回值:返回一个包含字典所有值的可迭代对象。
示例:
my_dict = {'a': 1, 'b': 2, 'c': 3} print(my_dict.values()) # 输出:dict_values([1, 2, 3])
items():
items()方法用于获取字典中所有的键值对。语法:
dict.items()返回值:返回一个包含字典所有键值对的可迭代对象,每个元素是一个元组,包含键和对应的值。
示例:
my_dict = {'a': 1, 'b': 2, 'c': 3} print(my_dict.items()) # 输出:dict_items([('a', 1), ('b', 2), ('c', 3)])
get():
get()方法用于根据键获取字典中对应的值,如果键不存在,则返回指定的默认值(默认为 None)。语法:
dict.get(key, default=None)参数:
key- 要获取值的键,default(可选) - 键不存在时返回的默认值。返回值:返回键对应的值,如果键不存在,则返回默认值。
示例:
my_dict = {'a': 1, 'b': 2, 'c': 3} value = my_dict.get('b') print(value) # 输出:2
pop():
pop()方法用于删除并返回字典中指定键的值。语法:
dict.pop(key, default=None)参数:
key- 要删除的键,default(可选) - 键不存在时返回的默认值。返回值:返回被删除的键对应的值,如果键不存在,则返回默认值或抛出 KeyError 异常。
示例:
my_dict = {'a': 1, 'b': 2, 'c': 3} value = my_dict.pop('b') print(value) # 输出:2 print(my_dict) # 输出:{'a': 1, 'c': 3}
update():
update()方法用于更新字典中的键值对,可以接受一个字典或者包含键值对的可迭代对象作为参数。语法:
dict.update([other])参数:
other- 字典或包含键值对的可迭代对象。示例:
my_dict = {'a': 1, 'b': 2} other_dict = {'b': 3, 'c': 4} my_dict.update(other_dict) print(my_dict) # 输出:{'a': 1, 'b': 3, 'c': 4}
词典的迭代和遍历:
可以使用
for循环来遍历字典中的键、值或键值对,也可以使用字典推导式等方式进行迭代操作。通过循环遍历字典,可以对字典中的每个键值对进行处理,或者对字典进行相应的操作。
for item in Zidian: # 使用for in循环获取的也是键 print(item,Zidian.get(item)) # 前面是键,后面是值 for key,value in user.items(): print("Key:" + key) print("Value:" + value)
词典的内部实现原理:
- 在 Python 中,字典通常是通过哈希表来实现的,即通过哈希函数将键映射到对应的存储位置,以实现快速的查找和插入操作。
- 当发生哈希冲突时,Python 使用链表或其他方法来处理冲突,保证字典的性能和可靠性。
集合
集合(set)的基本概念:
- 使用大括号
{}或set()函数来表示集合,元素之间用逗号,分隔,不存在像词典那样的键值对。 - 集合是一种无序的数据结构,这意味着集合不可以利用索引来操作数据。
- 集合是一种不重复的数据结构,存储的数据不能是相同的。
- 集合中的元素可以是任意不可变类型的数据,如整数、浮点数、字符串、元组等,但不能包含可变类型的数据,如列表、字典、集合等。若存在,则抛出TypeError异常。
- 集合是可变的,可以通过添加或删除元素来修改集合。
集合的常用方法和操作:
- 集合具有丰富的方法和操作,例如:
add()、remove()、discard()、pop()、clear()、union()、intersection()、difference()等等。 - 这些方法可以用来添加、删除、查找、合并、比较等操作集合中的元素。
add():
add()方法用于向集合中添加一个元素。语法:
set.add(element)参数:
element- 要添加的元素。示例:
my_set = {1, 2, 3} my_set.add(4) print(my_set) # 输出:{1, 2, 3, 4}
remove():
remove()方法用于删除集合中指定的元素,如果元素不存在则抛出 KeyError 异常。语法:
set.remove(element)参数:
element- 要删除的元素。示例:
my_set = {1, 2, 3} my_set.remove(2) print(my_set) # 输出:{1, 3}
discard():
discard()方法用于删除集合中指定的元素,如果元素不存在则不进行任何操作。语法:
set.discard(element)参数:
element- 要删除的元素。示例:
my_set = {1, 2, 3} my_set.discard(2) print(my_set) # 输出:{1, 3}
pop():
pop()方法用于移除并返回集合中的一个随机元素。语法:
set.pop()返回值:返回被移除的元素。
示例:
my_set = {1, 2, 3} popped_element = my_set.pop() print(popped_element) # 输出:随机一个元素 print(my_set) # 输出:移除随机元素后的集合
clear():
clear()方法用于移除集合中的所有元素,使集合变为空集。语法:
set.clear()示例:
my_set = {1, 2, 3} my_set.clear() print(my_set) # 输出:set()
集合的数学运算:
- 集合支持并集、交集、差集等数学运算,可以使用相应的方法或运算符来实现。
- 这些运算可以用来对集合进行合并、查找共同元素、找出不同元素等操作。
union():
union()方法用于返回两个集合的并集,即包含两个集合中所有不重复的元素。语法:
set.union(*others)参数:
others- 其他要并集的集合。示例:
set1 = {1, 2, 3} set2 = {3, 4, 5} union_set = set1.union(set2) print(union_set) # 输出:{1, 2, 3, 4, 5}
intersection():
intersection()方法用于返回两个集合的交集,即包含两个集合中共同的元素。语法:
set.intersection(*others)参数:
others- 其他要交集的集合。示例:
set1 = {1, 2, 3} set2 = {3, 4, 5} intersection_set = set1.intersection(set2) print(intersection_set) # 输出:{3}
difference():
difference()方法用于返回两个集合的差集,即包含在第一个集合中但不在第二个集合中的元素。语法:
set.difference(*others)参数:
others- 其他要比较的集合。示例:
set1 = {1, 2, 3} set2 = {3, 4, 5} difference_set = set1.difference(set2) print(difference_set) # 输出:{1, 2}
集合的迭代和遍历:
通过
for循环,可以依次迭代集合中的每个元素,并对每个元素进行相应的操作。通过集合推导式,可以对集合中的每个元素进行操作,并生成一个新的集合。
my_set = {1, 2, 3, 4, 5} # 使用 for 循环遍历集合中的元素并打印 for element in my_set: print(element)
元组
元组(tuple)的基本概念:
使用小括号**
()来表示元组,元素之间用逗号,** 分隔。元组是一种有序的数据结构,可以使用索引访问元组,但元组是不可变的,即一旦创建就不能修改其内容,因此可以作为字典的键、集合的元素等。
# 创建一个元组 my_tuple = (10, 20, 30, 40, 50) # 使用索引访问元组中的元素并打印 print("First element:", my_tuple[0]) # 访问第一个元素 print("Second element:", my_tuple[1]) # 访问第二个元素 print("Last element:", my_tuple[-1]) # 使用负向索引访问最后一个元素元组可以包含任意类型的元素,包括整数、浮点数、字符串、元组等。
元组的常用方法和操作:
- 元组相对于列表的方法和操作较少,但仍包括一些常用的方法,例如:
index()、count()等。 - 这些方法可以用来查找元组中的元素索引、统计元素出现次数等。
index():
index()方法用于查找指定元素在元组中的索引。语法:
tuple.index(element[, start[, end]])参数:
element- 要查找的元素,start(可选) - 查找起始位置的索引,end(可选) - 查找结束位置的索引。可选参数
start和end用于指定搜索范围的起始和结束位置(包含起始位置但不包含结束位置),如果未指定则默认搜索整个元组。返回值:返回指定元素在元组中第一次出现的索引,如果未找到则抛出 ValueError 异常。
示例:
my_tuple = (1, 2, 3, 2) index = my_tuple.index(2) print(index) # 输出:1 index = my_tuple.index(2, 2, 4) print(index) # 输出:3
count():
count()方法用于统计元组中指定元素的出现次数。语法:
tuple.count(element)参数:
element- 要统计出现次数的元素。返回值:返回指定元素在元组中出现的次数。
示例:
my_tuple = (1, 2, 3, 2) count = my_tuple.count(2) print(count) # 输出:2
主要的遍历方法
通过
for循环,可以依次迭代元组中的每个元素,并对每个元素进行相应的操作。通过
enumerate()函数,可以同时获取元组中每个元素的索引和值,然后进行相应的操作my_tuple = (1, 2, 3, 4, 5) # 使用 for 循环遍历元组中的元素并打印 for element in my_tuple: print(element)my_tuple = (1, 2, 3, 4, 5) # 使用 enumerate() 函数遍历元组中的元素及其索引并打印 for index, element in enumerate(my_tuple): print("Index:", index, "Element:", element)
字符串
字符串的基本概念:
- 字符串是一种有序的字符序列,用于表示文本数据。
- 字符串是不可变的,即一旦创建就不能修改其内容,但可以通过一些操作来生成新的字符串。
- 使用单引号
' '、双引号" "或三引号''' '''、""" """来表示字符串,其中三引号用于表示多行字符串。
字符串的常用方法和操作:
- 字符串具有丰富的方法和操作,例如:
split()、join()、strip()、replace()、find()、startswith()、endswith()等等。 - 这些方法可以用来对字符串进行分割、连接、去除空白字符、替换、查找等操作。
split():
split()方法用于将字符串分割成子串,并返回一个包含分割结果的列表。语法:
str.split(sep=None, maxsplit=-1)参数:
sep(可选) - 分隔符,默认为任意空白字符maxsplit(可选) - 最大分割次数。
返回值:返回一个包含分割后子串的列表。
示例:
my_string = "apple,banana,orange" splitted = my_string.split(',') print(splitted) # 输出:['apple', 'banana', 'orange']
join():
join()方法用于将列表中的字符串元素连接成一个字符串。语法:
separator.join(iterable)参数:
separator- 连接的分隔符,iterable- 包含字符串的可迭代对象。返回值:返回连接后的字符串。
示例:
fruits = ['apple', 'banana', 'orange'] joined = ','.join(fruits) print(joined) # 输出:'apple,banana,orange'
strip():
strip()方法用于去除字符串两端的空白字符(空格、制表符、换行符等)。语法:
str.strip(chars=None)参数:
chars(可选) - 要去除的指定字符。返回值:返回去除空白字符后的字符串。
示例:
my_string = " hello " stripped = my_string.strip() print(stripped) # 输出:'hello'
replace():
replace()方法用于替换字符串中的指定子串。语法:
str.replace(old, new[, count])参数:
old- 要被替换的子串,new- 替换后的新子串,count(可选) - 替换次数。返回值:返回替换后的新字符串。
示例:
my_string = "apple pie" replaced = my_string.replace('apple', 'banana') print(replaced) # 输出:'banana pie'
find():
find()方法用于在字符串中查找指定子串,并返回第一次出现的索引,如果未找到则返回 -1。语法:
str.find(sub[, start[, end]])参数:
sub- 要查找的子串,start(可选) - 查找起始位置的索引,end(可选) - 查找结束位置的索引。返回值:返回第一次出现的子串的索引,如果未找到则返回 -1。
示例:
my_string = "hello world" index = my_string.find('world') print(index) # 输出:6
startswith():
startswith()方法用于判断字符串是否以指定的前缀开头。语法:
str.startswith(prefix[, start[, end]])参数:
prefix- 要检查的前缀,start(可选) - 检查起始位置的索引,end(可选) - 检查结束位置的索引。
返回值:如果字符串以指定前缀开头则返回 True,否则返回 False。
示例:
my_string = "hello world" starts_with_hello = my_string.startswith('hello') print(starts_with_hello) # 输出:True
字符串的格式化:
字符串的格式化是指在字符串中插入变量、表达式或者其他字符串,并按照一定的格式进行排列和显示。在 Python 中,有多种方式可以进行字符串的格式化,包括使用字符串的 format() 方法、使用 f-strings(格式化字符串字面值)以及旧式的 % 运算符。在下面示例中,{} 或者 % 被用作占位符,后面的变量会按照顺序依次替换这些占位符。而在 f-strings 中,使用 {} 包含变量名或表达式即可,Python 会在运行时将这些表达式的值插入到字符串中。
使用
format()方法:name = "Alice" age = 30 formatted_string = "My name is {} and I am {} years old.".format(name, age) print(formatted_string)My name is Alice and I am 30 years old.
还可以在
{}进行如下操作:指定变量名:
在大括号中可以使用变量名,对应.format()方法中的关键字参数名。pythonCopy code formatted_string = "My name is {name} and I am {age} years old.".format(name="Alice", age=30) print(formatted_string)My name is Alice and I am 30 years old.
索引位置:
在大括号中也可以使用参数的索引位置。pythonCopy code formatted_string = "My name is {0} and I am {1} years old.".format("Alice", 30) print(formatted_string)My name is Alice and I am 30 years old.
格式指令:
- 更多格式指令
<、>、=:分别表示左对齐、右对齐和居中对齐,默认是左对齐。
"{:<9s}".format("hello") # 左对齐 "{:>9s}".format("hello") # 右对齐 "{:^9s}".format("hello") # 居中对齐宽度:使用数字指定字段的最小宽度。
"{:10s}".format("hello") # 总宽度为10个字符精度:在小数部分指定数字的精度。
"{:.2f}".format(3.14159) # 保留两位小数符号:控制数字的正负号显示。
"{:+}".format(10) # 显示正负号 "{:-}".format(-10) # 仅显示负号填充:指定填充字符。
"{:_>10s}".format("hello") # 使用下划线填充 "{:^10s}".format("hello") # 使用空格填充(默认)类型:指定格式化的类型。
"{:b}".format(10) # 二进制表示 "{:x}".format(255) # 十六进制表示
使用 f-strings(格式化字符串字面值):
name = "Alice" age = 30 formatted_string = f"My name is {name} and I am {age} years old." print(formatted_string)My name is Alice and I am 30 years old.
r"string":raw,原始字符串,用于防止转义字符的特殊处理。u"string":Unicode 字符串,在 Python 2 中用于指示字符串为 Unicode 类型,但在 Python 3 中默认所有字符串都是 Unicode 类型,因此此前缀不再需要。f"string": 格式化字符串字面值,可以在字符串中直接引用变量和表达式,并将它们的值插入到字符串中。使用旧式的
%运算符:name = "Alice" age = 30 formatted_string = "My name is %s and I am %d years old." % (name, age) print(formatted_string)My name is Alice and I am 30 years old.
字符串的驻留机制:
字符串的驻留机制是指在 Python 中对相同的字符串字面值进行内存优化,使得它们共享相同的内存地址,以减少内存使用和提高性能。在 Python 中,字符串的驻留机制遵循以下原则:
对于长度不超过20个字符的字符串,Python 在程序编译时会自动将其驻留(intern),即使是不同的字符串对象,只要它们的值相同,都会指向相同的内存地址。
s1 = "hello" s2 = "hello" print(id(s1), id(s2)) # 两个字符串对象的内存地址相同对于长度超过20个字符的字符串,Python 不会自动驻留,即使它们的值相同,也不会共享内存地址。
好像还是一样的,不确定的事情等以后再考验
s1 = "a" * 21 s2 = "a" * 21 print(id(s1), id(s2)) # 两个字符串对象的内存地址不同使用
intern()函数可以强制将一个字符串驻留,使得它与其他相同值的字符串共享内存地址。s1 = "hello" s2 = intern("hello") print(id(s1), id(s2)) # 两个字符串对象的内存地址相同import sys s1 = "hello" s2 = sys.intern("hello") print(id(s1), id(s2)) # 两个字符串对象的内存地址相同
虽然字符串驻留机制可以节省内存,但也可能导致意外的内存泄漏问题,因为驻留的字符串不会被垃圾回收。因此,不要在运行时动态地创建大量长度不超过20个字符的字符串,以避免潜在的内存泄漏问题。
综合示例
# 定义学生的数据结构
# 使用字典来存储学生信息,其中键是学生ID(字符串),值是另一个字典,包含姓名、年龄、成绩(列表)和联系方式(元组)
students = {
"S001": {
"name": "Alice",
"age": 20,
"grades": [88, 92, 85],
"contact": ("alice@email.com", "123-456-7890")
},
"S002": {
"name": "Bob",
"age": 22,
"grades": [76, 85, 90],
"contact": ("bob@email.com", "098-765-4321")
},
"S003": {
"name": "Carol",
"age": 21,
"grades": [92, 88, 91],
"contact": ("carol@email.com", "345-678-9012")
}
}
# 显示所有学生信息的函数
def display_students():
print("Displaying all students' information:")
for student_id, info in students.items():
print(f"Student ID: {student_id}")
print(f"Name: {info['name']}")
print(f"Age: {info['age']}")
print(f"Grades: {info['grades']}")
print(f"Contact Email: {info['contact'][0]}, Phone: {info['contact'][1]}")
print("-" * 40)
# 添加新学生的函数
def add_student(student_id, name, age, grades, email, phone):
if student_id in students:
print("Error: Student ID already exists.")
return
students[student_id] = {
"name": name,
"age": age,
"grades": grades,
"contact": (email, phone)
}
print(f"Student {name} added successfully.")
# 删除学生的函数
def delete_student(student_id):
if student_id in students:
del students[student_id]
print(f"Student {student_id} has been deleted.")
else:
print("Error: Student ID not found.")
# 搜索学生信息的函数
def search_student(student_id):
if student_id in students:
info = students[student_id]
print(f"Found student: {student_id}")
print(f"Name: {info['name']}")
print(f"Age: {info['age']}")
print(f"Grades: {info['grades']}")
print(f"Contact Email: {info['contact'][0]}, Phone: {info['contact'][1]}")
else:
print("Student not found.")
# 计算学生平均成绩的函数
def calculate_average(student_id):
if student_id in students:
grades = students[student_id]['grades']
average = sum(grades) / len(grades)
print(f"Average grades for {students[student_id]['name']}: {average:.2f}")
else:
print("Error: Student ID not found to calculate average.")
# 主函数,用于运行脚本
def main():
# 测试添加和删除功能
add_student("S004", "David", 23, [85, 80, 88], "david@email.com", "456-789-0123")
display_students()
delete_student("S002")
display_students()
# 测试搜索和计算平均成绩功能
search_student("S001")
calculate_average("S001")
add_student("S005", "Eve", 19, [92, 87, 90], "eve@email.com", "987-654-3210")
delete_student("S003")
search_student("S004")
calculate_average("S004")
display_students()
if __name__ == "__main__":
main()
本篇文章,如有错误,欢迎指正,感激不尽。