欢迎来到CILMY23的博客
本篇主题为:深入浅出C++中深拷贝和浅拷贝
个人主页:CILMY23-CSDN博客
系列专栏:Python | C++ | C语言 | 数据结构与算法
感谢观看,支持的可以给个一键三连,点赞关注+收藏。
写在前头:
在之前的一篇,我写了关于拷贝构造函数的内容,对于其中的几个点我还是挺疑惑的,例如什么是浅拷贝,深拷贝,它们之间有什么区别和联系等等,因此我也整理了这篇博客。
目录
但是在了解深浅拷贝之前,还是离不开C/C++中的内存管理。
首先数据类型我们还是需要了解的:
数据类型在C/C++中大概分为,内置类型(基本数据类型)和自定义类型(复合数据类型),例如整型,浮点型,布尔值,字符型等等这些C++语言内部原生支持的基础数据类型,自定义类型就是结构体,类,枚举等等这些由程序员在C++程序中定义的类型。这类类型通常基于内置类型。
回到正题,什么是浅拷贝,什么是深拷贝?
什么是浅拷贝(Shallow Copy)?
浅拷贝的概念大多如下:
- 对于基本数据类型的成员变量,浅拷贝直接进行值传递,也就是将属性值复制了一份给新的成员变量
- 对于引用数据类型的成员变量,比如成员变量是数组、某个类的对象等,浅拷贝就是引用的传递,也就是将成员变量的引用(内存地址)复制了一份给新的成员变量,他们指向的是同一个事例。在一个对象修改成员变量的值,会影响到另一个对象中成员变量的值。
对于第一点不难看懂,浅拷贝就是对内置类型的拷贝,按内存存储,字节序完成拷贝的,这点常常在C语言中体现,例如我们在给函数传实参的时候,通常是将实参拷贝一份传递给形参。这是一种值传递,值拷贝。
但是对于第二点引用数据类型的成员变量又是什么呢? 看不懂,根本不明白,但是既然有内置类型的拷贝,就有自定义类型的拷贝情况。那我们就拿一个数据结构中的栈的例子来看看吧。
typedef int datatype;
class stack
{
public:
stack(size_t capacity = 10)
{
_array = (datatype*)malloc(capacity * sizeof(datatype));
if (nullptr == _array)
{
perror("malloc申请空间失败");
return;
}
_size = 0;
_capacity = capacity;
}
void push(const datatype& data)
{
// checkcapacity();
_array[_size] = data;
_size++;
}
~stack()
{
if (_array)
{
free(_array);
_array = nullptr;
_capacity = 0;
_size = 0;
}
}
private:
datatype* _array;
size_t _size;
size_t _capacity;
};
int main()
{
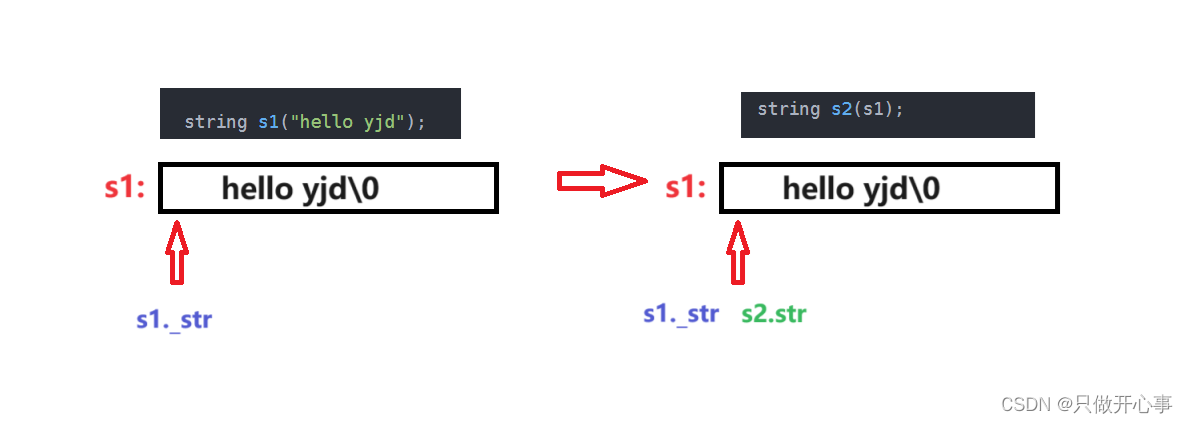
stack st1;
stack st2(st1);//编译器自动生成默认的拷贝构造函数
return 0;
}结果:
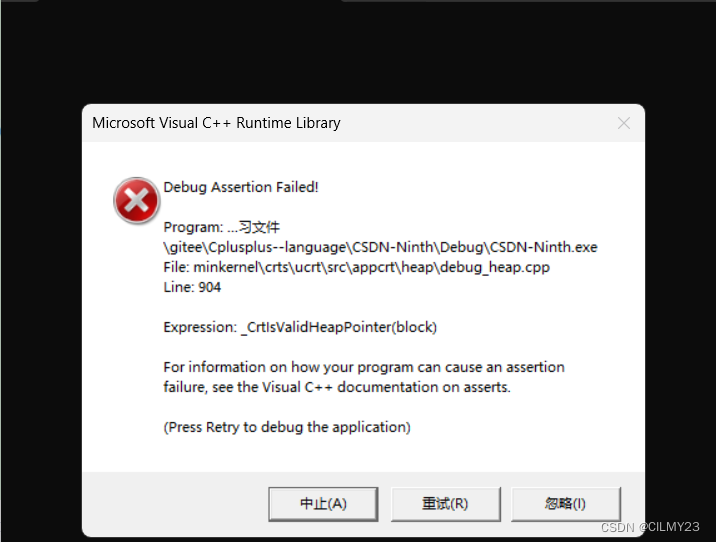
出现在调试日志中的错误消息“_CrtlsValidHeapPointer(block)”通常表明程序尝试访问或操作一个无效的堆指针,那为什么会这样的,其实这里是浅拷贝的隐患。
我们来看这段代码:
类 stack 包含了一个动态分配的数组 _array,用于存储数据。通过构造函数中使用 malloc 分配内存。在拷贝构造时(即 stack st2(st1)),编译器自动生成的默认拷贝构造函数会将 _array 指针从 st1 复制到 st2。因此两个 stack 对象,st2 和 st1 将共享相同的内存区域。问题就在这,main函数结束时,不是会调用拷贝构造吗,按照"后进先出"的原则,会先将 st2 的资源释放,然后再去释放st1,但是 st2 和 st1 共享相同的内存区域,多次释放相同的内存区域就会报错。
如下图所示:

所以这里的引用数据类型透过实例化我们也算知道它是跟地址有关的,在我看的博客中是这么说的:
基本数据类型的特点:直接存储在栈(stack)中的数据
引用数据类型的特点:存储的是该对象在栈中引用,真实的数据存放在堆内存里引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
无论怎样,到最后还是跟地址有关,也因此我们引入了深拷贝,来完成这些编译器完成不了的任务。
什么是深拷贝(Deep Copy)?
深拷贝的概念大多如下:
- 对于基本数据类型,深拷贝复制所有基本数据类型的成员变量的值
- 对于引用数据类型的成员变量,深拷贝申请新的存储空间,并复制该引用对象所引用的对象,也就是将整个对象复制下来。所以在一个对象修改成员变量的值,不会影响到另一个对象成员变量的值。
深拷贝和浅拷贝在对于内置类型的拷贝都是一样的,但是深拷贝不同的特点是它在拷贝的时候,会自己创建一个新的存储空间,来保存一份。
例如:我们为了规避浅拷贝的隐患,我们会使用深拷贝,深拷贝就需要我们自己写拷贝构造函数了,当然栈的深拷贝比较简单。
栈的深拷贝如下:
// Stack st2(st1);
stack(const stack& s)
{
datatype* tmp = (datatype*)malloc(s._capacity *(sizeof(datatype)));
if (tmp == nullptr)
{
perror("malloc fail");
exit(-1);
}
memcpy(tmp, s._array, sizeof(datatype) * s._size);
_array = tmp;
_size = s._size;
_capacity = s._capacity;
}
 当然这里的 memcpy 和 malloc 不是很好,可以考虑用 new 和 copy 进行进一步的优化,并且在C++中,通常更喜欢使用异常而不是手动错误处理,例如 perror 和 exit ,使用异常来表示内存分配失败。
当然这里的 memcpy 和 malloc 不是很好,可以考虑用 new 和 copy 进行进一步的优化,并且在C++中,通常更喜欢使用异常而不是手动错误处理,例如 perror 和 exit ,使用异常来表示内存分配失败。
深拷贝和浅拷贝的区别
浅拷贝的优缺点很明显:
- 浅拷贝速度较快,因为它只复制简单的属性和指针。
- 浅拷贝容易导致内存泄漏或重复释放。
深拷贝的优缺点如下:
- 深拷贝创建完全独立的复制,原始对象和复制对象之间没有共享资源。
- 深拷贝可以避免内存泄漏或重复释放。
- 深拷贝可能比浅拷贝更耗时,因为需要复制更多数据。
- 如果对象中含有复杂数据结构,深拷贝可能需要更多内存。
但是深拷贝的使用场景更复杂,如果对象中只有基本数据类型或者引用数据类型不会改动,则推荐浅拷贝,如果存在指针,引用等,并且会改动,则推荐使用深拷贝,具体使用拷贝中的哪个方法,需要具体情况具体分析,比如性能考虑、便捷考虑、依赖引入的考虑等等。
参考:
面试官问:什么是浅拷贝和深拷贝? - 知乎 (zhihu.com)
浅拷贝与深拷贝的区别(详解)_深拷贝和浅拷贝的区别-CSDN博客
感谢各位同伴的支持,本期深拷贝和浅拷贝就讲解到这啦,如果你觉得写的不错的话,可以给个一键三连,点赞关注+收藏,若有不足,欢迎各位在评论区讨论。