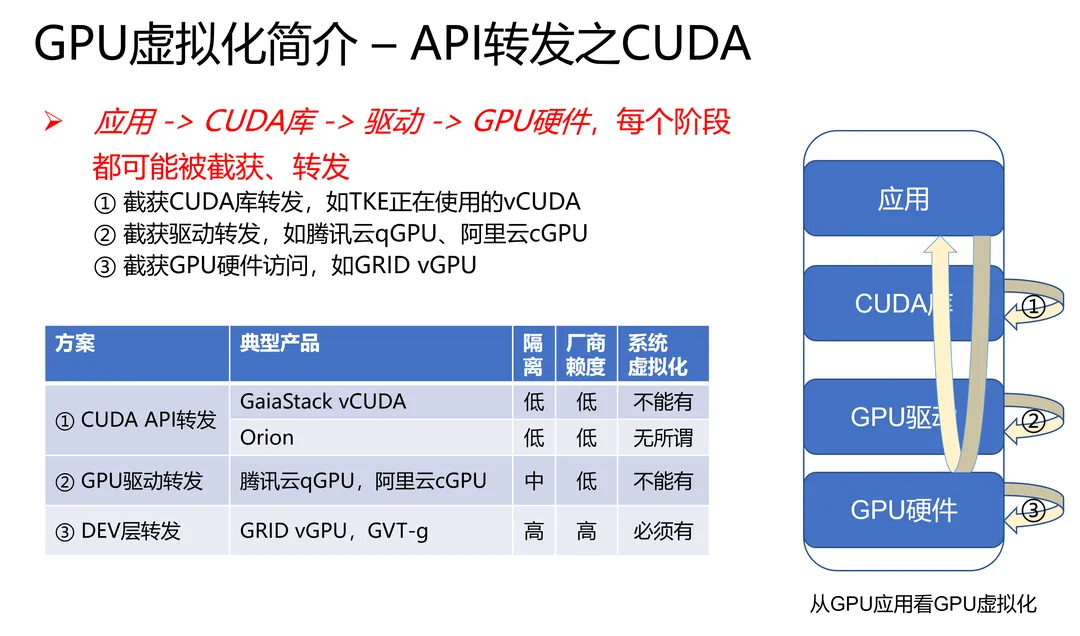
1. 术语介绍
术语 |
全称 |
说明 |
|---|---|---|
GPU |
Graphics Processing Unit |
显卡 |
CUDA |
Compute Unified Device Architecture |
英伟达2006年推出的计算API |
VT/VT-x/VT-d |
Intel Virtualization Technology |
-x表示x86 CPU,-d表示Device |
SVM |
AMD Secure Virtual Machine |
AMD的等价于Intel VT-x的技术 |
EPT |
Extened Page Table |
Intel的CPU虚拟化中的页表虚拟化硬件支持 |
NPT |
Nested Page Table |
AMD的等价于Intel EPT的技术 |
SR-IOV |
Single Root I/O Virtualization |
PCI-SIG 2007年推出的PCIe虚拟化技术 |
PF |
Physical Function |
物理卡 |
VF |
Virtual Function |
SR-IOV的虚拟PCIe设备 |
MMIO |
Memory Mapped I/O |
设备上的寄存器或存储,CPU以内存读写指令来访问 |
UMD |
User Mode Driver |
GPU的用户态驱动程序 |
KMD |
Kernel Mode Driver |
GPU的PCIe驱动 |
GVA |
Guest Virtual Address |
VM中的CPU虚拟地址 |
GPA |
Guest Physical Address |
VM看到的物理地址 |
HPA |
Host Physical Address |
Host看到的物理地址 |
IOVA |
I/O Virtual Address |
设备发出去的DMA地址 |
PCIe TLP |
PCIe Transaction Layer Packet |
|
BDF |
Bus/Device/Function |
一个PCIe/PCI功能的ID |
MPT |
Mediated Pass-Through |
受控直通,一种设备虚拟化的实现方式 |
MDEV |
Mediated Device |
Linux中的MPT实现 |
PRM |
Programming Rerference Manual |
硬件的编程手册 |
MIG |
Multi-Instance GPU |
Ampere架构的高端GPU如A100、A30支持的一种硬件partition方案 |
2. GPU虚拟化的历史和谱系
GPU天然适合向量计算。最常用的情景及API:
场景 |
API |
|---|---|
游戏渲染 |
OpenGL/OpenGL ES,DirectX,Vulkan,Metal |
媒体编解码 |
VAAPI,VDPAU |
深度学习计算 |
CUDA,OpenCL |
此外还有AES加密、哈希等场景,例如近些年来的挖矿。渲染是GPU诞生之初的应用: GPU的"G"就是Graphics —— 图形。
桌面、服务器级别的GPU,长期以来仅有三家厂商:
英伟达:GPU王者。主要研发力量在美国和印度。
AMD/ATI:ATI被AMD收购。渲染稍逊英伟达,计算的差距更大。
Intel: 长期作为集成显卡存在,2020开始推出独立显卡。
2006这一年,GPU工业界发生了三件大事: ATI被AMD收购;nVidia黄仁勋提出了CUDA计算;Intel宣布要做独立显卡。
如同经常发生的,这些事有成功有失败: Intel很快就放弃了它的独立显卡,直到2018才终于明白过来、自己放弃的到底是什么,开始决心生产独立显卡;AMD整合ATI不太成功,整个公司差点被拖死,危急时股票跌到1.8美元;而当时不被看好的CUDA,则在几年后取得了不可思议的成功。
从2012年开始,人工智能领域的深度学习方法开始崛起,此时CUDA受到青睐,并很快统治了这个领域。
3. 系统虚拟化和OS虚拟化
系统虚拟化演化之路,起初是和GPU的演化完全正交的:
1998年,VMWare公司成立,采用Binary Translation方式,实现了系统虚拟化。
2001年,剑桥大学Xen Source,提出了PV虚拟化(Para-Virtualization),亦即Guest-Host的主动协作来实现虚拟化。
2005年,Intel提出了VT,最初实现是安腾CPU上的VT-i (VT for Itanium),很快就有了x86上的VT-x。
2007年,Intel提出了VT-d (VT for Device),亦即x86上的IOMMU。
2008年,Intel提出了EPT,支持了内存虚拟化。
2010年,Linux中的PV Hypervisor lguest的作者,Rusty Russell(他更著名的作品是iptables/netfilter),提出了VirtIO,一种Guest-Host的PV设备虚拟化方案。
应该可以说,在PV时代和Binary Translation时代,虚拟化是很危险的。只有当VT在硬件层面解决了CPU的隔离、保证了安全性之后,公有云才成为可能。VT-x于2005~2006年出现,亚马逊AWS于2006年就提出云计算,这是非常有远见的。
系统的三个要素: CPU,内存,设备。CPU虚拟化由VT-x/SVM解决,内存虚拟化由EPT/NPT解决,这些都是非常确定的。但设备虚拟化呢?它的情况要复杂的多,不管是VirtIO,还是VT-d,都不能彻底解决设备虚拟化的问题,这些我们稍后还会谈到。
除了这种支撑完整OS的系统虚拟化,还有一种也往往被称作「虚拟化」的方式: 从OS级别,把一系列的libirary和process捆绑在一个环境中,但所有的环境共享同一个OS Kernel。
严格来说,这种容器技术,和以KVM为代表的系统虚拟化,有着本质的区别。随着容器的流行,「虚拟化」这个术语,也被用来指称这种OS级别的容器技术。因此我们也从众,把它也算作虚拟化的一种 —— 只不过为了区分,称之为OS虚拟化。
这种OS虚拟化最初于2005年,由Sun公司在Solaris 10上实现,名为「Solaris Zone」。Linux在2007~2008开始跟进,接下来有了LXC容器等;到了2013年,Docker横空出世,彻底改变了软件分发的生态,成为事实上的标准。
4. GPU虚拟化的谱系
4.1. 作为PCIe设备的GPU
不考虑嵌入式平台的话,那么,GPU首先是一个PCIe设备。GPU的虚拟化,还是要首先从PCIe设备虚拟化角度来考虑。
那么一个PCIe设备,有什么资源?有什么能力?
2种资源:
配置空间
MMIO
(有的还有PIO和Option ROM,此略)
2种能力:
中断能力
DMA能力
一个典型的GPU设备的工作流程是:
应用层调用GPU支持的某个API,如OpenGL或CUDA
OpenGL或CUDA库,通过UMD (User Mode Driver),提交workload到KMD (Kernel Mode Driver)
KMD写CSR MMIO,把它提交给GPU硬件
GPU硬件开始工作... 完成后,DMA到内存,发出中断给CPU
CPU找到中断处理程序 —— KMD此前向OS Kernel注册过的 —— 调用它
中断处理程序找到是哪个workload被执行完毕了,...最终驱动唤醒相关的应用
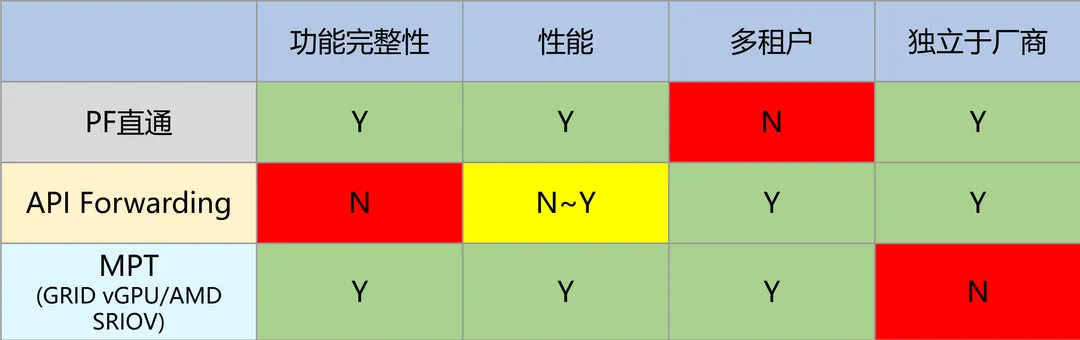
4.2. PCIe直通
我们首先来到GPU虚拟化的最保守的实现: PCIe设备直通。
如前述,一个PCIe设备拥有2种资源、2种能力。你把这2种资源都(直接或间接地)交给VM、针对这2种能力都把设备和VM接通,那么,VM就能完整使用这个PCIe设备,就像在物理机上一样。这种方案,我们称之为PCIe Pass-Through(PCIe直通)。它只能1:1,不支持1:N。其实并不能算真正的虚拟化,也没有超卖的可能性。
VM中,使用的是原生的GPU驱动。它向VM内核分配内存,把GPA填入到GPU的CSR,GPU用它作为IOVA来发起DMA访问,VT-d保证把GPA翻译为正确的HPA,从而DMA到达正确的物理内存。
PCIe协议,在事务层(Transaction Layer),有多种TLP,DMA即是其中的一类: MRd/MWr。在这种TLP中,必须携带发起者的Routing ID,而在IOMMU中,就根据这样的Routing ID,可以使用不同的IOMMU页表进行翻译。
很显然,PCIe直通只能支持1:1的场景,无法满足1:N的需求。
4.3. SR-IOV
那么,业界对1:N的PCIe虚拟化是如何实现的呢?我们首先就会想到SR-IOV。SR-IOV是PCI-SIG在2007年推出的方案,目的就是PCIe设备的虚拟化。SR-IOV的本质是什么?考虑我们说过的2种资源和2种能力,来看看一个VF有什么:
配置空间是虚拟的(特权资源)
MMIO是物理的
中断和DMA,因为VF有自己的PCIe协议层的标识(Routing ID,就是BDF),从而拥有独立的地址空间。
那么,什么设备适合实现SR-IOV?其实无非是要满足两点:
硬件资源要能partition好
无状态(至少要接近无状态)
常见PCIe设备中,最适合SR-IOV的就是网卡了: 一或多对TX/RX queue + 一或多个中断,结合上一个Routing ID,就可以封装为一个VF。而且它是近乎无状态的。
试考虑NVMe设备,它的资源也很容易partition,但是它有存储数据,因此在实现SR-IOV方面,就会有更多的顾虑。
回到GPU虚拟化: 为什么2007年就出现SR-IOV规范、直到2015业界才出现第一个「表面上的」SR-IOV-capable GPU【1】?这是因为,虽然GPU基本也是无状态的,但是它的硬件复杂度极高,远远超出NIC、NVMe这些,导致硬件资源的partition很难实现。
注释
【1】 AMD S7150 GPU。腾讯云GA2机型使用。 表面上它支持SR-IOV,但事实上硬件只是做了VF在PCIe层的抽象。Host上还需要一个Virtualization-Aware的pGPU驱动,负责VF的调度。
4.4. API转发
因此,在业界长期缺乏SR-IOV-capable GPU、又有强烈的1:N需求的情形下,就有更high-level的方案出现了。我们首先回到GPU应用的场景:
渲染(OpenGL、DirectX,etc.)
计算(CUDA,OpenCL)
媒体编解码(VAAPI...)
业界就从这些API入手,在软件层面实现了「GPU虚拟化」。以AWS Elastic GPU为例:
VM中看不到真的或假的GPU,但可以调用OpenGL API进行渲染
在OpenGL API层,软件捕捉到该调用,转发给Host
Host请求GPU进行渲染
Host把渲染的结果,转发给VM
API层的GPU虚拟化是目前业界应用最广泛的GPU虚拟化方案。它的好处是:
灵活。1:N的N,想定为多少,软件可自行决定;哪个VM的优先级高,哪个VM的优先级低,同理。
不依赖于GPU硬件厂商。微软、VMWare、Citrix、华为……都可以实现。这些API总归是公开的。
不限于系统虚拟化环境。容器也好,普通的物理机也好,都可以API转发到远端。
缺点呢?
复杂度极高。同一功能有多套API(如渲染的DirectX和OpenGL),同一套API还有不同版本(如DirectX 9和DirectX 11),兼容性就复杂的要命。以业界著名某厂商为例,其VDI团队就200多人的规模。
功能不完整。计算渲染媒体都支持的API转发方案,还没听说过。并且,编解码甚至还不存在业界公用的API!【1】
注释
【1】 Vulkan的编解码支持,spec刚刚添加,有望被所有GPU厂商支持。见下「未来展望」部分。
4.5. MPT/MDEV/vGPU
鉴于这些困难,业界就出现了SR-IOV、API转发之外的第三种方案。我们称之为MPT(Mediated Pass-Through,受控的直通)。 MPT本质上是一种通用的PCIe设备虚拟化方案,甚至也可以用于PCIe之外的设备。它的基本思路是:
敏感资源如配置空间,是虚拟的
关键资源如MMIO(CSR部分),是虚拟的,以便trap-and-emulate
性能关键资源如MMIO(GPU显存、NVMe的CMB等),硬件partition后直接赋给VM
Host上必须存在一个Virtualization-Aware的驱动程序,以负责模拟和调度,它实际上是vGPU的device-model
这样,VM中就能看到一个「看似」完整的GPU PCIe设备,它可以attach原生的GPU驱动。以渲染为例,vGPU的工作流程是:
VM中的GPU驱动,准备好一块内存,保存的是渲染workload
VM中的GPU驱动,把这块内存的物理地址(GPA),写入到MMIO CSR中
Host/Hypervisor/驱动: 捕捉到这次的MMIO CSR写操作,拿到了GPA
Host/Hypervisor/驱动: 把GPA转换成HPA,并pin住相应的内存页
Host/Hypervisor/驱动: 把HPA(而不是GPA),写入到pGPU的真实的MMIO CSR中
pGPU工作,完成这个渲染workload,并发送中断给驱动
驱动找到该中断对应哪个workload —— 当初我是为哪个vGPU提交的这个workload? —— 并注入一个虚拟的中断到相应的VM中
VM中的GPU驱动,收到中断,知道该workload已经完成,结果已在内存中
这就是nVidia GRID vGPU、Intel GVT(KVMGT、XenGT)的基本实现思路。一般认为graphics stack是OS中最复杂的,加上虚拟化之后复杂度更是暴增,随便什么地方出现BUG,调试起来都是无比痛苦。但只要稳定下来,这种MPT方案,就能兼顾1:N灵活性、渲染计算媒体的完整性、高性能...是不是很完美?
其实也不是。
该方案最大的缺陷,是必须有一个pGPU驱动,负责vGPU的模拟和调度工作。逻辑上它相当于一个实现在内核态的device-model。而且,由于GPU硬件通常并不公开其PRM,所以事实上就只有GPU厂商才有能力提供这样的Virtualization-Aware pGPU驱动。以nVidia GRID vGPU方案为例,GPU硬件卖给我们时nVidia收了一次钱,GRID vGPU方案在腾讯云上部署后,客户使用vGPU时,nVidia还要再收一次钱!
4.6. SR-IOV: revisited
我们重新回到GPU的SR-IOV。AMD从S7150开始、英伟达从Turing架构开始,数据中心GPU都支持了SR-IOV。但是again,它不是NIC那样的SR-IOV,它需要Host上存在一个vGPU的device-model,来模拟从VM来的VF访问。
所以事实上,到目前为止,GPU的SR-IOV仅仅是封装了PCIe TLP层的VF路由标识、从而规避了runtime时的软件DMA翻译,除此之外,和基于MDEV的MPT方案并无本质的不同。
4.7. 谱系表
在介绍完了上述的这些方案后,我们重新看下CUDA计算、OpenGL渲染两种场景的软件栈,看看能发现什么:
CUDA计算stack:
OpenGL渲染Stack:
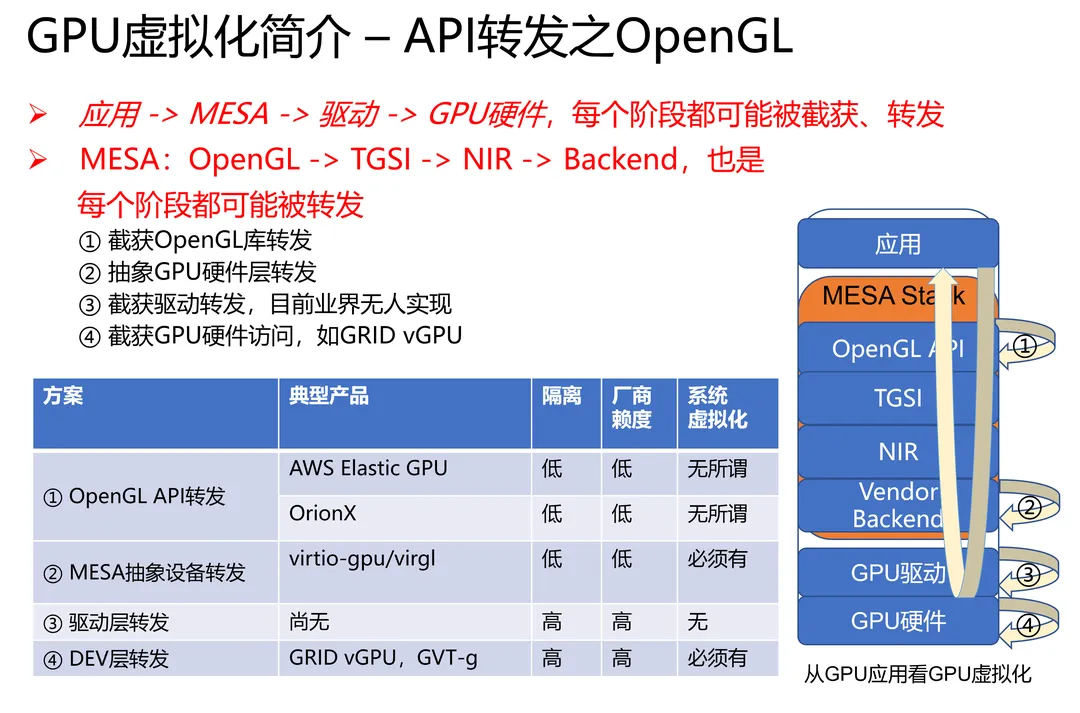
可以看出,从API library开始,直到GPU硬件,Stack中的每一个阶段,都有被截获、转发的可能性。甚至,一概称之为「API转发」是不合适的 —— 以GRID vGPU、GVT-g为例的DEV转发,事实上就是MPT,和任何API都没有关系。
5. 容器GPU虚拟化
首先,我们这里谈到的,都是nVidia生产的GPU、都只考虑CUDA计算场景。其次,这里的虚拟化是OS虚拟化的容器技术,不适用于KATA这样的基于系统虚拟化的安全容器。
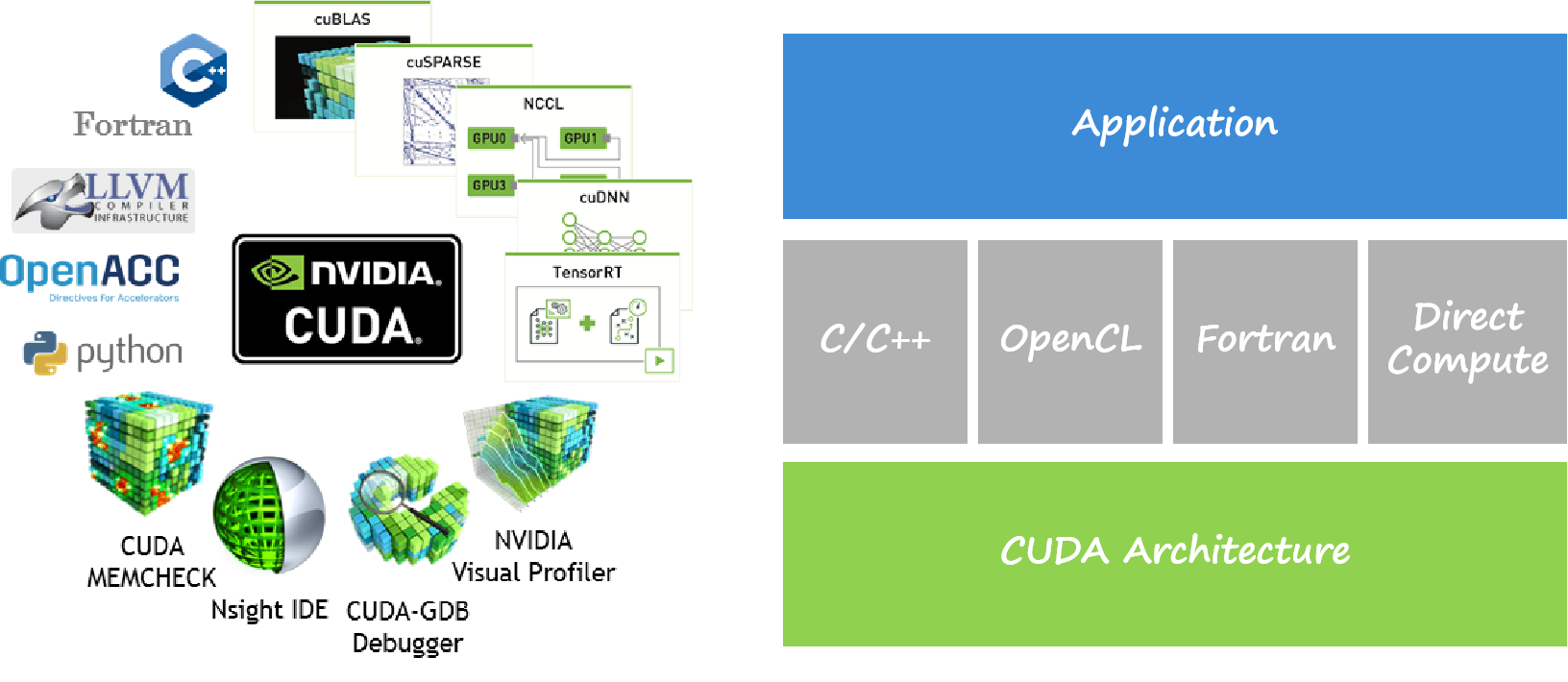
5.1. CUDA的生态
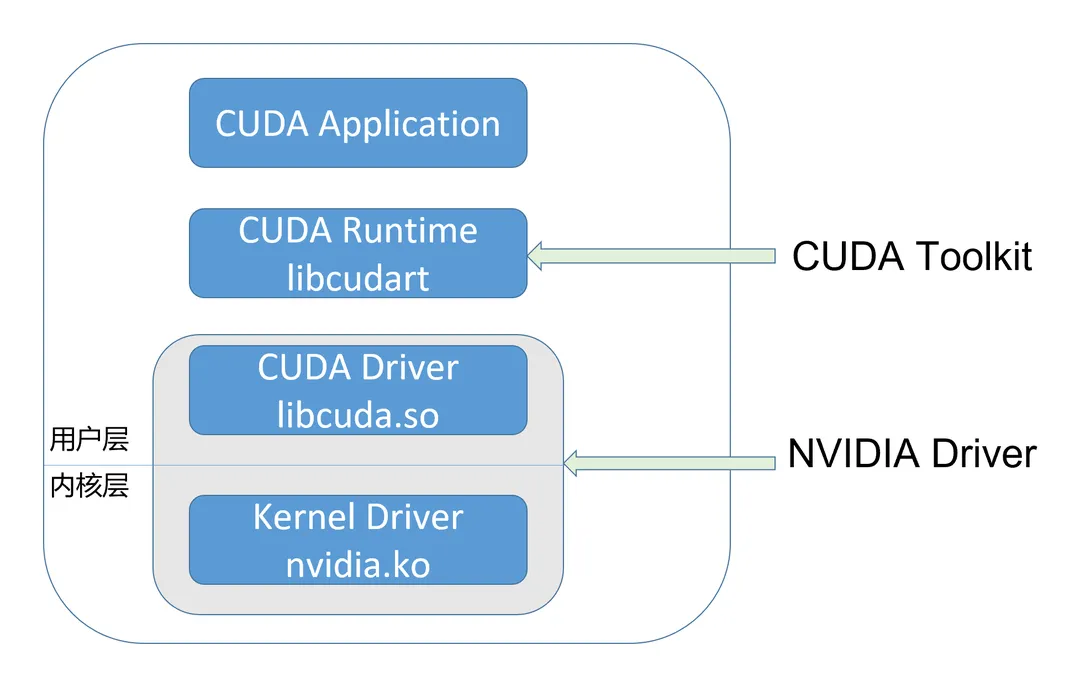
CUDA开发者使用的,通常是CUDA Runtime API,它是high-level的;而CUDA Driver API则是low-level的,它对程序和GPU硬件有更精细的控制。Runtime API是对Driver API的封装。
CUDA Driver即是UMD,它直接和KMD打交道。两者都属于NVIDIA Driver package,它们之间的ABI,是NVIDIA Driver package内部的,不对外公开。
英伟达软件生态封闭:
无论是nvidia.ko,还是libcuda.so,还是libcudart,都是被剥离了符号表的
大多数函数名是加密替换了的
函数调用不直接进行,而是大量使用了函数指针,进行变换和跳转
代码中随处检查栈深度,防止插入函数调用
以nvidia.ko为例,为了兼容不同版本的Linux内核API,它提供了相当丰富的兼容层,于是也就开源了部分代码:
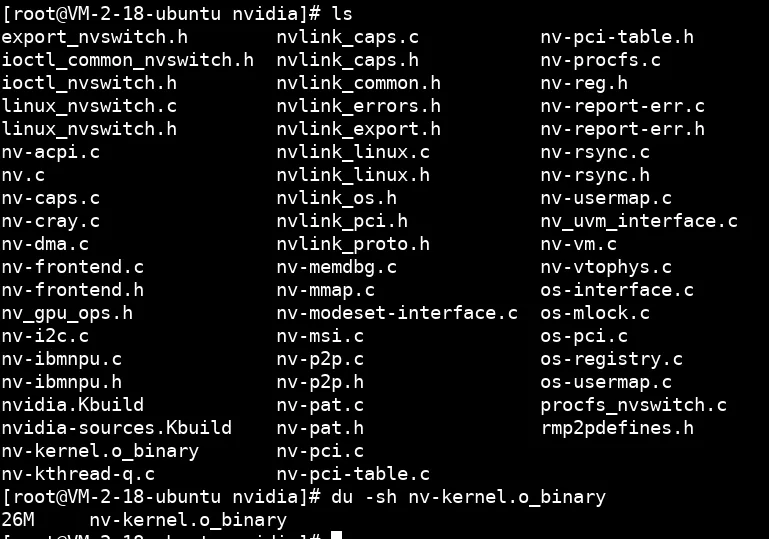
这个26M大小的、被剥离了符号表的nv-kernel.o_binary,就是GPU驱动的核心代码,所有的GPU硬件细节都藏在其中。
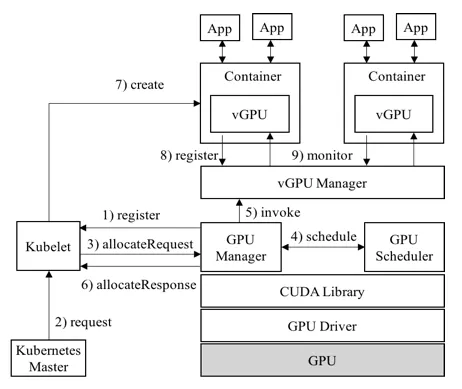
5.2. vCUDA和阿里云cGPU
vCUDA架构图:
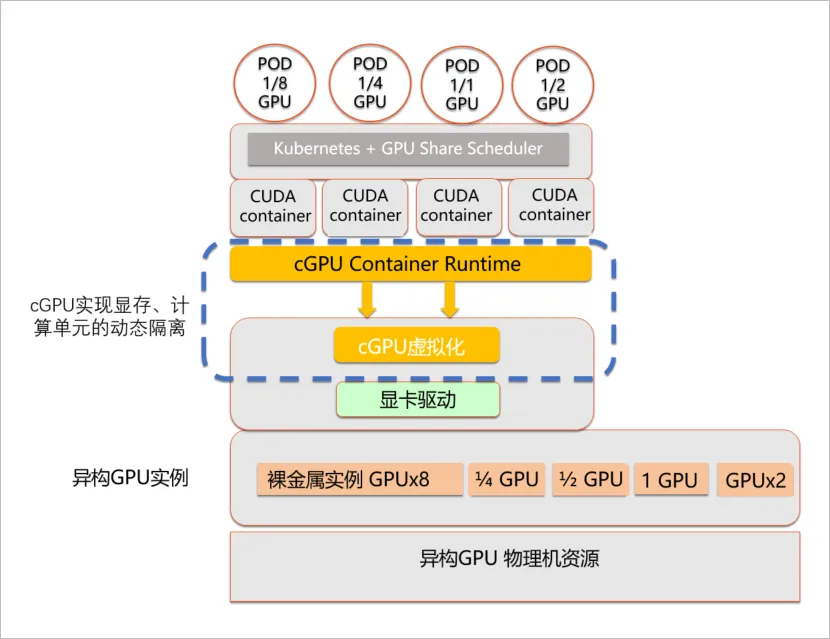
cGPU架构图:
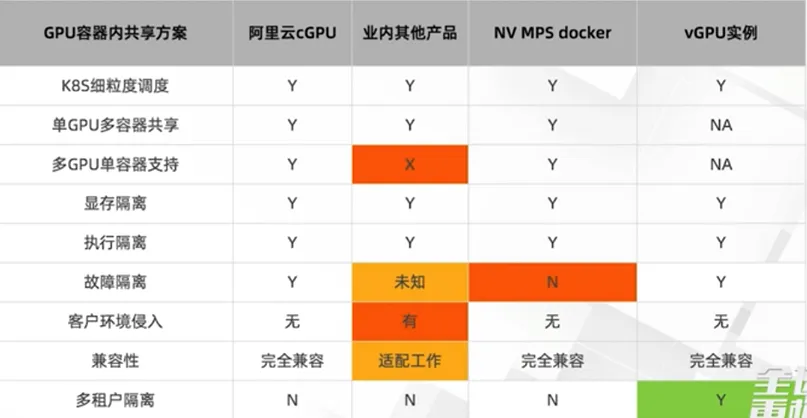
不同厂商的隔离行对比
5.3. GPU池化和算力隔离
GPU池化的谱系:
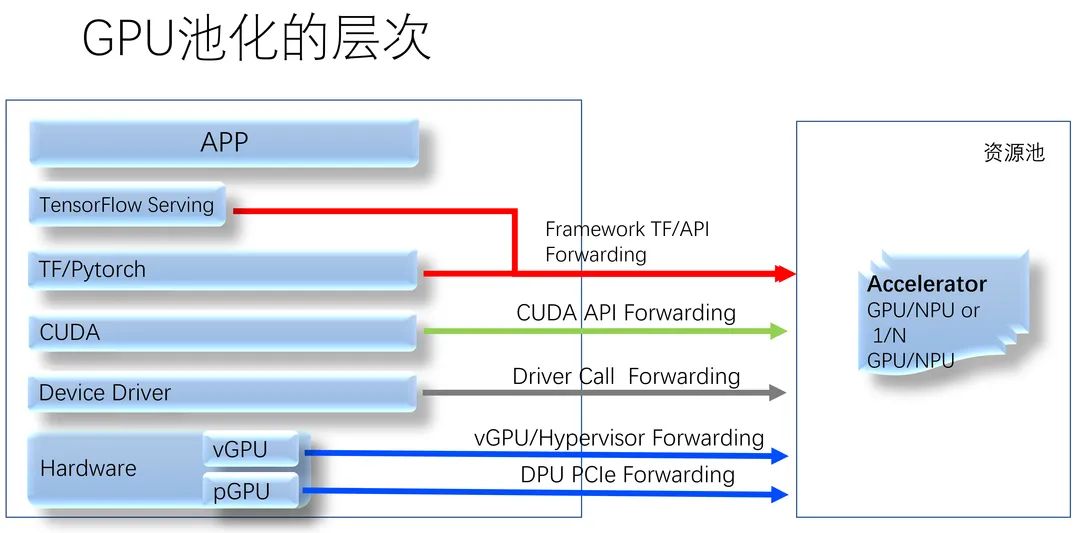
以CUDA API level的转发池化方案、趋动科技公司的Orion为例,它到了GPU所在的后端机器上,由于一个GPU卡可能运行多个GPU任务,这些任务之间,依然需要有算力隔离。Orion为了实现这一点,在后端默认启用了nVidia MPS —— 也就是故障隔离最差的方案。这会导致什么?一个VM里的CUDA程序越界访问了显存,一堆风马牛不相及的VM里的CUDA应用就会被杀死。
所以很显然,GPU池化也必须以同时满足故障隔离和算力隔离的方案作为基础。
5.4. 算力隔离的本质
从对阿里云cGPU的介绍上、从Orion池化方案的后端缺陷上,都可以看出:算力隔离是GPU虚拟化、GPU池化的关键。如果没有算力隔离,不管虚拟化损失有多低,都会导致其方案价值变低(例如: cGPU);而Orion,宁肯牺牲实例间的故障隔离,也要用MPS实现算力隔离 —— 这是一种自毁口碑的行为,但至少,对尚未意识到MPS致命缺陷的小白客户来说,还能够看到算力隔离的存在。
英伟达GPU提供了丰富的硬件特性,支持硬件partition,支持Time Sharing。
1. Hardware Partition,亦即: 空分
Ampere架构的A100、A30 GPU所支持的MIG,即是一种Hardware Partition。其资源隔离、故障隔离都是硬件实现的 —— 这是无可争议的隔离性最好的方案。它的问题是不灵活: 只有高端GPU支持;只支持CUDA计算;A100只支持7个MIG实例。
2. nVidia MPS
除了MIG,算力隔离表现最优秀的,是MPS —— 它通过将多个进程的CUDA Context,合并到一个CUDA Context中,省去了Context Switch的开销,也在Context内部实现了算力隔离。如前所述,MPS的致命缺陷,是把许多进程的CUDA Context合并成一个,从而导致了故障传播。所以尽管它的算力隔离效果极好,但长期以来工业界使用不多,多租户场景尤其如此。
3. Time Sharing,亦即: 时分
基于Engine的Context Switch。不管是哪一代的GPU,其Engine都是支持多任务调度的。一个OS中同时运行多个CUDA任务,这些任务就是在以Time Sharing的方式共享GPU。
鉴于MIG的高成本和不灵活、MPS故障隔离方面的致命缺陷,事实上就只剩下一种可能:Time Sharing。唯一的问题是,如何在原厂不支持的情况下,利用Time Sharing支持好算力隔离、以保证QoS。这也是学术界、工业界面临的最大难题。
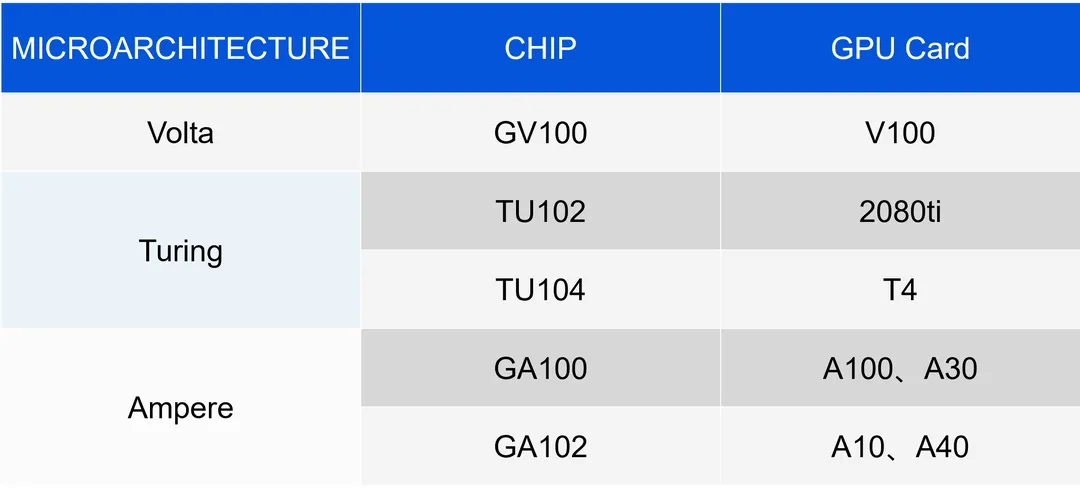
5.4.1. GPU microarchitecture和chip
真正决定GPU硬件以何种方式工作的,是chip型号。不管是GRID Driver还是Tesla Driver,要指挥GPU硬件工作,就要首先判断GPU属于哪种chip,从而决定用什么样的软硬件接口来驱动它。
5.4.2. PFIFO: GPU Scheduling Internals
PFIFO架构:
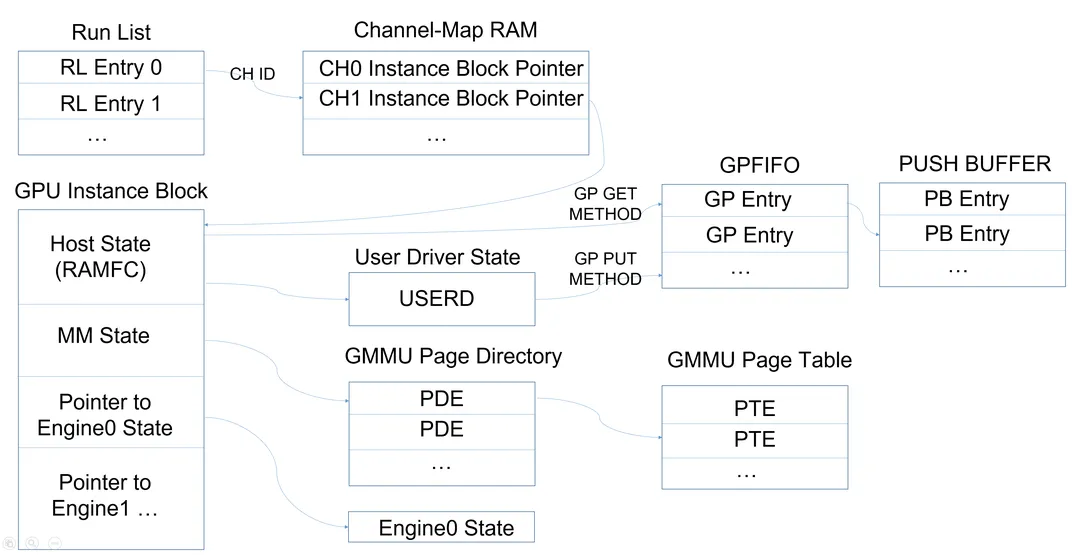
概念解释:
PFIFO: GPU的调度硬件,整体上叫PFIFO。
Engine: 执行某种类型任务的GPU硬件单元。常见engine有:
PGRAPH CUDA/Graphics
PCOPY Copy Engine
PVENC Video Encoding
PVDEC Video Decoding
...
最重要的就是PGRAPH Engine,它是CUDA和渲染的硬件执行单元。
Channel: GPU暴露给软件的,对Engine的抽象。一个app可以对应一或多个channels,执行时由GPU硬件把一个一个的channel,放在一个一个的engine上执行。channel是软件层的让GPU去执行的最小调度单位。
TSG: Timeslice Group。
由一组(一或多个)channel(s)组成。一个TSG共享一个context,且作为一个调度单位被GPU执行。
runlist: GPU调度的最大单位。调度时,GPU通常是从当前runlist的头部摘取TSG或channel
来运行。因此,切换runlist也意味着切换active TSG/channel。
PBDMA: pushbuffer DMA
GPU上的硬件,用于从Memory中获取pushbuffer。
Host
GPU上和SYSMEM打交道的部分(通过PCIe系统)。PBDMA是Host的一部分。
注意,Host是Engine和SYSMEM之间的唯一桥梁。
Instance Block
每个Channel对应一个Instance Block,它包含各个Engine的状态,用于Context Switch时的Save/Restore;包含GMMU pagetable;包含RAMFC —— 其中包括UMD控制的USERD。
5.4.3 runlist/TSG/channel的关系
1. Tesla驱动为每个GPU,维护一或多个runlist,runlist或位于VIDMEM,或位于SYSMEM
2. runlist中有很多的entry,每个entry是一个TSG或一个channel
一个TSG是multi-channel或single-channel的
一个channel必定隶属于某个TSG
3. 硬件执行TSG或channel,当遇到以下情景之一时,进行Context Switch:
执行完毕
timeslice到了 —— Tesla Driver默认2ms
发生了preemption
5.4.4 pending channel notification
pending channel notification是USERD中的机制。UMD可以利用它通知硬件: 某个channel有了新的任务了【1】。这样,GPU硬件在当前channel被切换后(执行完毕、或timeslice到了),就会执行相应的channel。
注释
【1】 不同chip,实现有所不同。
5.4.5 从硬件调度看GRID vGPU
GRID vGPU支持3种scheduler:
1. Best Effort: 所有vGPU的任务随意提交,GPU尽力执行。
【现象】 如果启动了N个vGPU,它们的负载足够高,那么结果就是均分算力。
【原理】所有的vGPU使用同一个runlist。runlist内,还是按照channel为粒度进行调度。如同在native机器上运行多个CUDA任务一样。
2. Equal Share: 所有vGPU严格拥有同样的GPU配额
【现象】如果启动了N个vGPU,它们严格拥有相同的算力,不管是否需要这么多。
【原理】为每个vGPU维护一个runlist。当它的timeslice过了,GRID Host Driver会写GPU寄存器,触发当前runlist被抢占、下一个runlist被调度。
3. Fixed Share: 每个vGPU有自己固定的GPU配额
【现象】每个vGPU严格按照创建时的规格来分配算力。
【原理】Ditto.
5.5 腾讯云qGPU简介
qGPU == QoS GPU。它是业界唯一真正实现了故障隔离、显存隔离、算力隔离、且不入侵生态的容器GPU共享的技术。
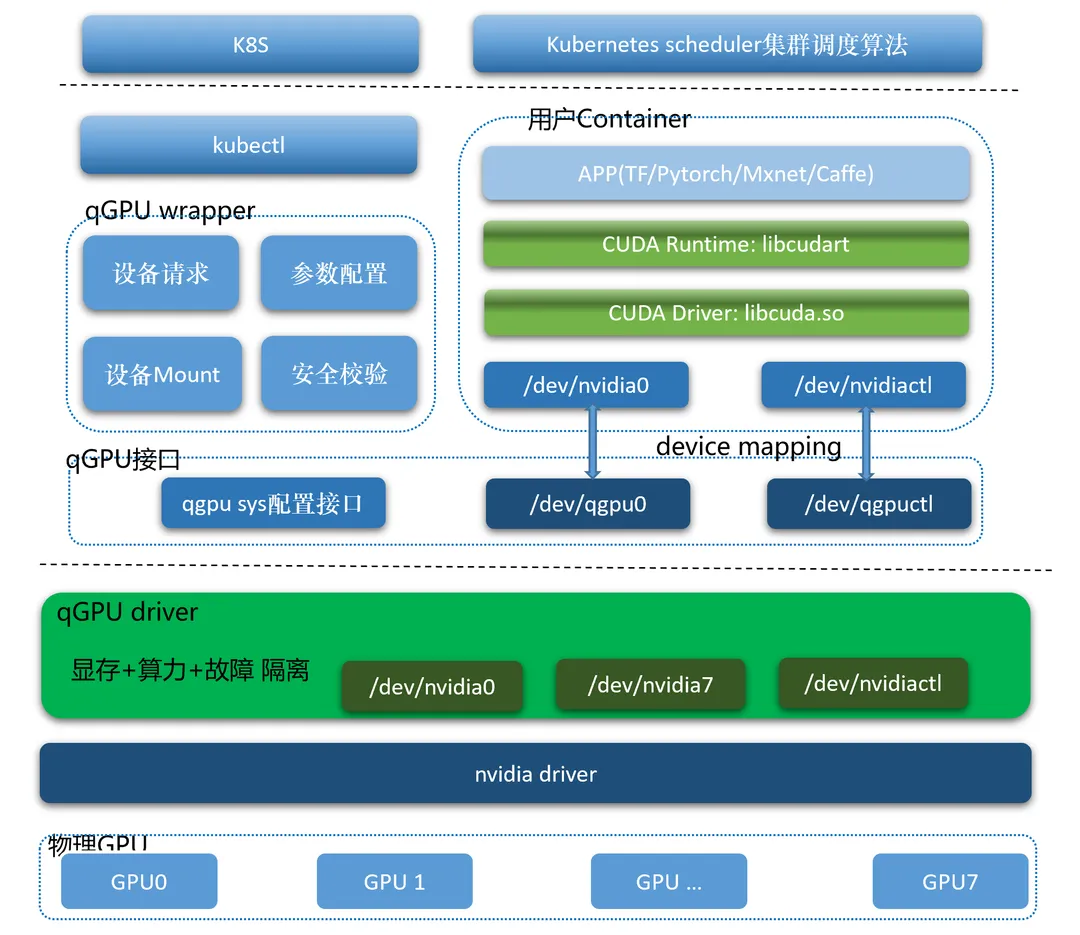
5.5.1 qGPU基本架构
qGPU基本架构和友商cGPU类似:
5.5.2 qGPU QoS效果
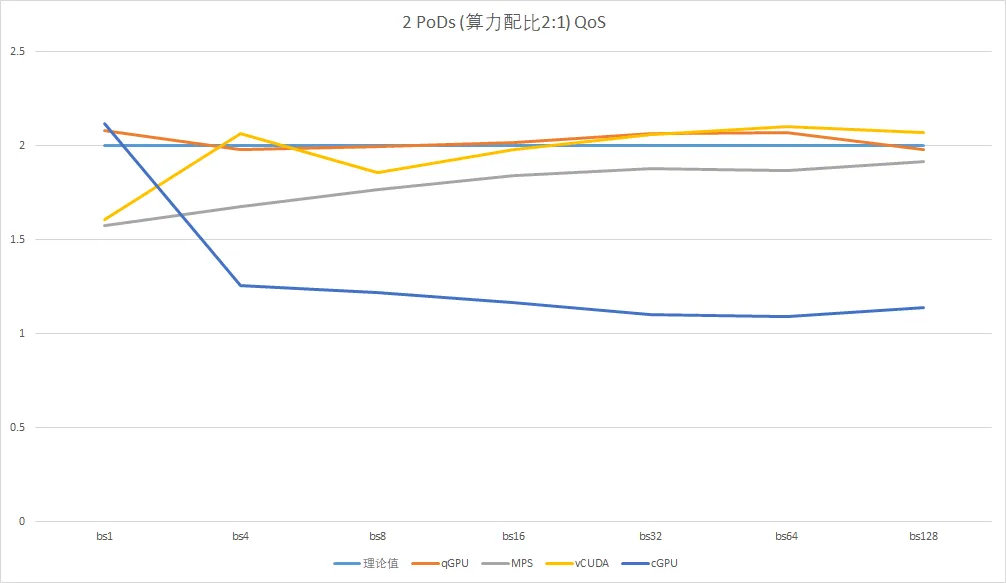
注释
测试数据来自T4(chip: TU104)。
两个PoD的配比为2:1,横坐标为batch值,纵坐标为实际运行时两个PoD的算力比例。可以看到,batch较小时,负载较小,无法反映算力比例; 随着batch的增大,MPS和qGPU都趋近理论值2,vCUDA也偏离不远,但缺乏QoS的cGPU则逐渐趋近1 —— 两个PoD相等。
6. GPU虚拟化: 未来展望
2021以来,GPU工业界发生了一些变化,e.g.:
英伟达QoS被攻破
英伟达在CUDA计算领域占据压倒性的优势,因此它对提升GPU利用率并无兴趣: MPS只是玩票性质的;MIG昂贵而又不灵活;即使是GRID vGPU,也在灵活性上远远没有做到它本应做到的。
长期以来,学术界和工业界付出了大量的努力,尝试在英伟达不支持QoS的前提下,实现某种程度的算力隔离。遗憾的是,这些努力,要么集中在CUDA API层,能够做到一定的算力隔离,但同样会带来副作用;要么尝试在low-level层面突破 —— 但不幸全都失败了。
qGPU是十几年来在英伟达GPU上实现QoS的最大突破。基于它:
腾讯云TKE的多容器共享GPU,将无悬念地领先整个工业界
在线推理 + 离线训练的混布,成为可能
GPU池化的后端实现,不管采用哪种方案,都有了坚实的基础
Linux/Android场景的渲染,目前需求小众,但技术基础已经有了
Vulkan Spec支持了video encode/decode
很可能,编解码API不统一的乱象即将终结,这对API转发方案有很大的意义。不远的将来,或许某种API方案的vGPU会成为主流。Google在社区的一些活动表明,很可能它就有这样的计划。