2. PostgreSQL存储管理器
src/backend/storage
(base) torres@torresの机革:~/codes/postgresql-16.2/src/backend/storage$ ls
Makefile buffer file freespace ipc large_object lmgr meson.build objfiles.txt page smgr sync
存储管理器—smgr
通用存储管理器 smgr,
typedef struct f_smgr
{
void (*smgr_init) (void); /* may be NULL */
void (*smgr_shutdown) (void); /* may be NULL */
void (*smgr_open) (SMgrRelation reln);
void (*smgr_close) (SMgrRelation reln, ForkNumber forknum);
void (*smgr_create) (SMgrRelation reln, ForkNumber forknum,
bool isRedo);
bool (*smgr_exists) (SMgrRelation reln, ForkNumber forknum);
void (*smgr_unlink) (RelFileLocatorBackend rlocator, ForkNumber forknum,
bool isRedo);
void (*smgr_extend) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, const void *buffer, bool skipFsync);
void (*smgr_zeroextend) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, int nblocks, bool skipFsync);
bool (*smgr_prefetch) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum);
void (*smgr_read) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, void *buffer);
void (*smgr_write) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, const void *buffer, bool skipFsync);
void (*smgr_writeback) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, BlockNumber nblocks);
BlockNumber (*smgr_nblocks) (SMgrRelation reln, ForkNumber forknum);
void (*smgr_truncate) (SMgrRelation reln, ForkNumber forknum,
BlockNumber nblocks);
void (*smgr_immedsync) (SMgrRelation reln, ForkNumber forknum);
} f_smgr;
// 函数指针赋值
static const f_smgr smgrsw[] = {
/* magnetic disk */
{
.smgr_init = mdinit,
.smgr_shutdown = NULL,
.smgr_open = mdopen,
.smgr_close = mdclose,
.smgr_create = mdcreate,
.smgr_exists = mdexists,
.smgr_unlink = mdunlink,
.smgr_extend = mdextend,
.smgr_zeroextend = mdzeroextend,
.smgr_prefetch = mdprefetch,
.smgr_read = mdread,
.smgr_write = mdwrite,
.smgr_writeback = mdwriteback,
.smgr_nblocks = mdnblocks,
.smgr_truncate = mdtruncate,
.smgr_immedsync = mdimmedsync,
}
};
static const int NSmgr = lengthof(smgrsw); // (sizeof (array) / sizeof ((array)[0]))
计算smgrsw 的 lengthof是1,因为 smgrsw 数组只有一个元素。
部分代码
指派物理文件RelationSetNewRelfilenumber
// @ src/backend/utils/cache/cache.c //16.2
RelationSetNewRelfilenode 函数,该函数用于给数据库中的关系(表、索引等)指派一个新的物理文件名(relfilenumber 或 relfilenode),这是文件在磁盘上的表示。这个过程通常涉及到更换底层存储文件,可能是为了表重建、截断或其他维护任务。
eg2. 指派物理文件 heap_create
// @ src/backend/catalog/heap.c // create table …
/*
* heap_create - Create an uncataloged heap relation
* Note API change: the caller must now always provide the OID
* to use for the relation. The relfilenode may (and, normally,
* should) be left unspecified.
*/
Relation heap_create(const char *relname, Oid relnamespace, Oid reltablespace, ...)
{
.....
/* 1. 判断关系类型是否需要物理存储。有些关系类型(如视图)不需要物理存储。*/
if (!RELKIND_HAS_STORAGE(relkind))
create_storage = false;
else {
/* 2. 如果调用者没有指定 relfilenode,则使用 relid 作为 relfilenode。
这意味着物理文件名将与关系的 OID 相同。*/
if (!OidIsValid(relfilenode))
relfilenode = relid;
}
/* 3. 如果需要,让存储管理器创建关系的磁盘文件。*/
if (create_storage) {
/* 4. 检查关系类型是否支持表访问方法。*/
if (RELKIND_HAS_TABLE_AM(rel->rd_rel->relkind))
/* 4.1 如果是标准表类型,设置新的文件节点。 */
table_relation_set_new_filenode(rel, &rel->rd_node, relpersistence, relfrozenxid, relminmxid);
else if (RELKIND_HAS_STORAGE(rel->rd_rel->relkind))
/* 4.2 如果关系类型有物理存储但不使用标准表访问方法,
直接通过存储管理器创建存储。 */
RelationCreateStorage(rel->rd_node, relpersistence, true);
else
/* 4.3 如果无法识别的关系类型尝试创建存储,则断言失败。 */
Assert(false);
}
.....
}
大对象—large_object
管理系统表pg_largeobject,利用系统表pg_largeobject来存大对象,存一个oid,对应的pageno以及实际data。
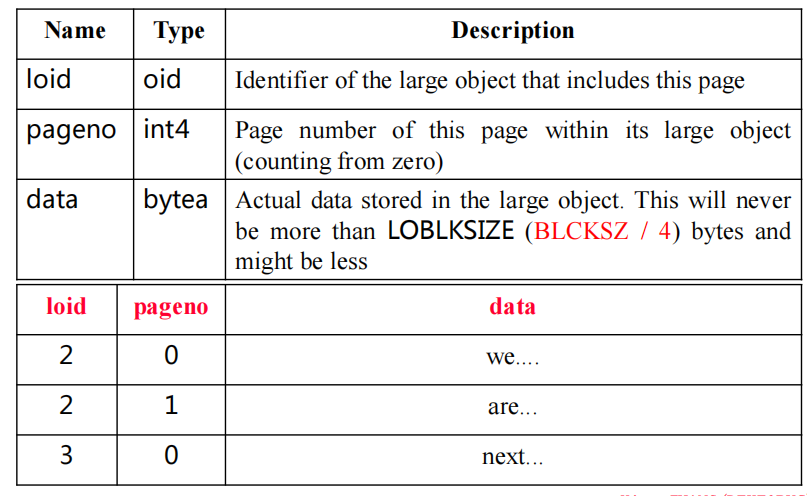
“loid”表示大型对象的唯一标识符,每个“loid”可以关联多个“pageno”,表明一个大型对象可以分布在多个页面上。每个页面中的“data”列包含了该页的实际二进制数据。写sql取出来的话,要orderby然后匹配loid取出方便拼接出原始照片。
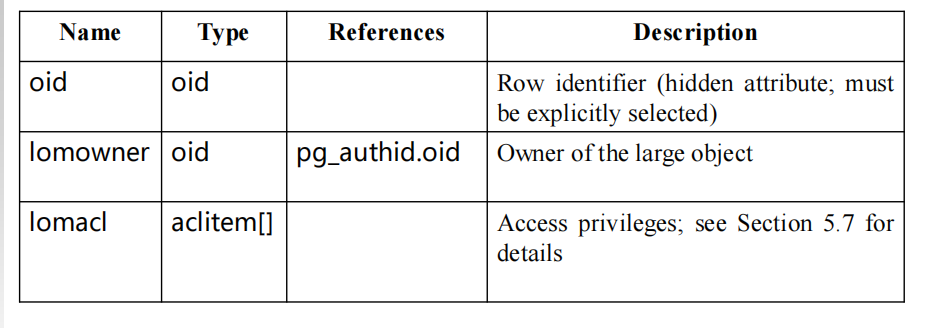
大对象表的描述信息/元数据
操作lob
/*
* Create a large object having the given LO identifier.
*
* We create a new large object by inserting an entry into
* pg_largeobject_metadata without any data pages, so that the object
* will appear to exist with size 0.
*/
Oid
LargeObjectCreate(Oid loid)
{
Relation pg_lo_meta;
HeapTuple ntup;
Oid loid_new;
// 可能是要在初始化的时候 insert的值
Datum values[Natts_pg_largeobject_metadata];
// 标识插入的values哪个是空
bool nulls[Natts_pg_largeobject_metadata];
pg_lo_meta = table_open(LargeObjectMetadataRelationId,
RowExclusiveLock);
/*
* Insert metadata of the largeobject
*/
memset(values, 0, sizeof(values));
memset(nulls, false, sizeof(nulls));
if (OidIsValid(loid))
loid_new = loid;
else
loid_new = GetNewOidWithIndex(pg_lo_meta,
LargeObjectMetadataOidIndexId,
Anum_pg_largeobject_metadata_oid);
values[Anum_pg_largeobject_metadata_oid - 1] = ObjectIdGetDatum(loid_new);
values[Anum_pg_largeobject_metadata_lomowner - 1]
= ObjectIdGetDatum(GetUserId());
nulls[Anum_pg_largeobject_metadata_lomacl - 1] = true;
ntup = heap_form_tuple(RelationGetDescr(pg_lo_meta),
values, nulls);
CatalogTupleInsert(pg_lo_meta, ntup);
heap_freetuple(ntup);
table_close(pg_lo_meta, RowExclusiveLock);
return loid_new;
}
操作大对象—inv_api.c
src/backend/libpq/be-fsstubs.c,import/export large object
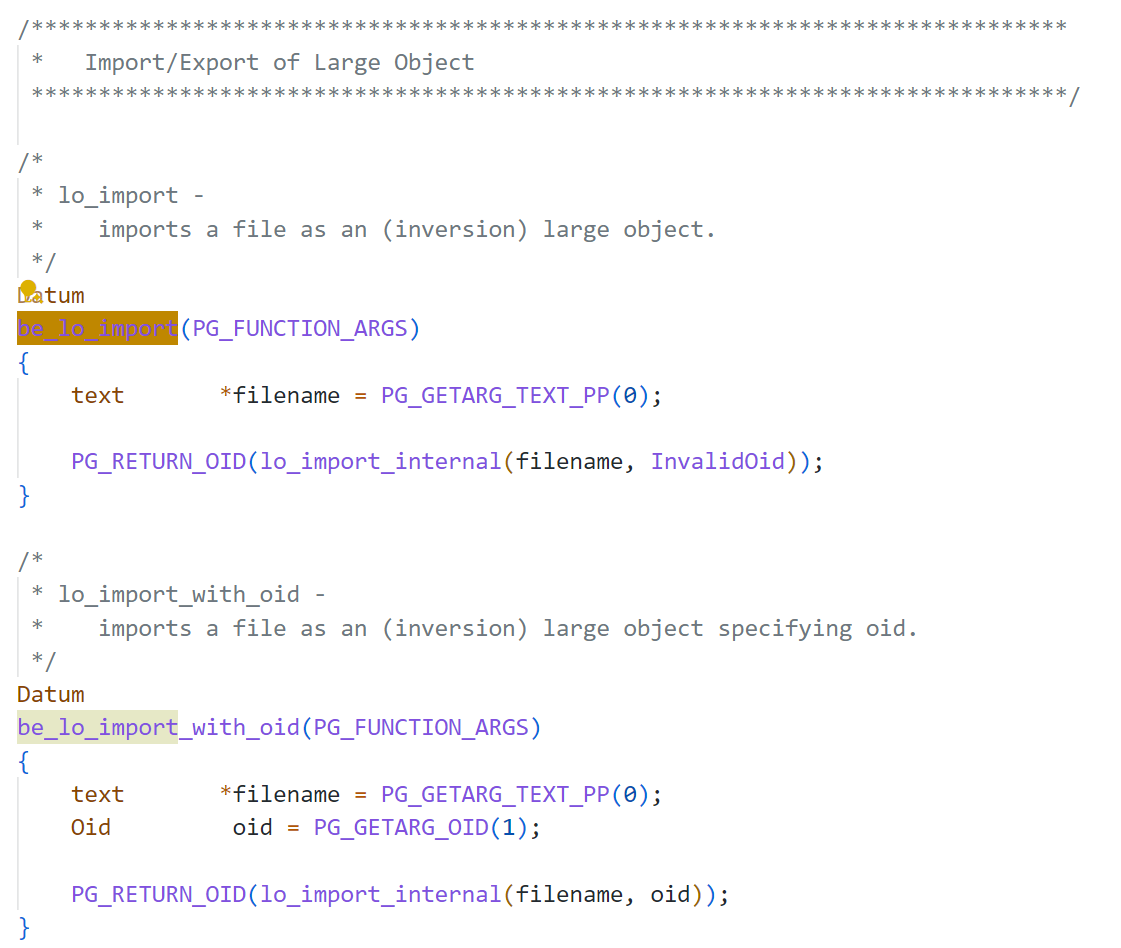

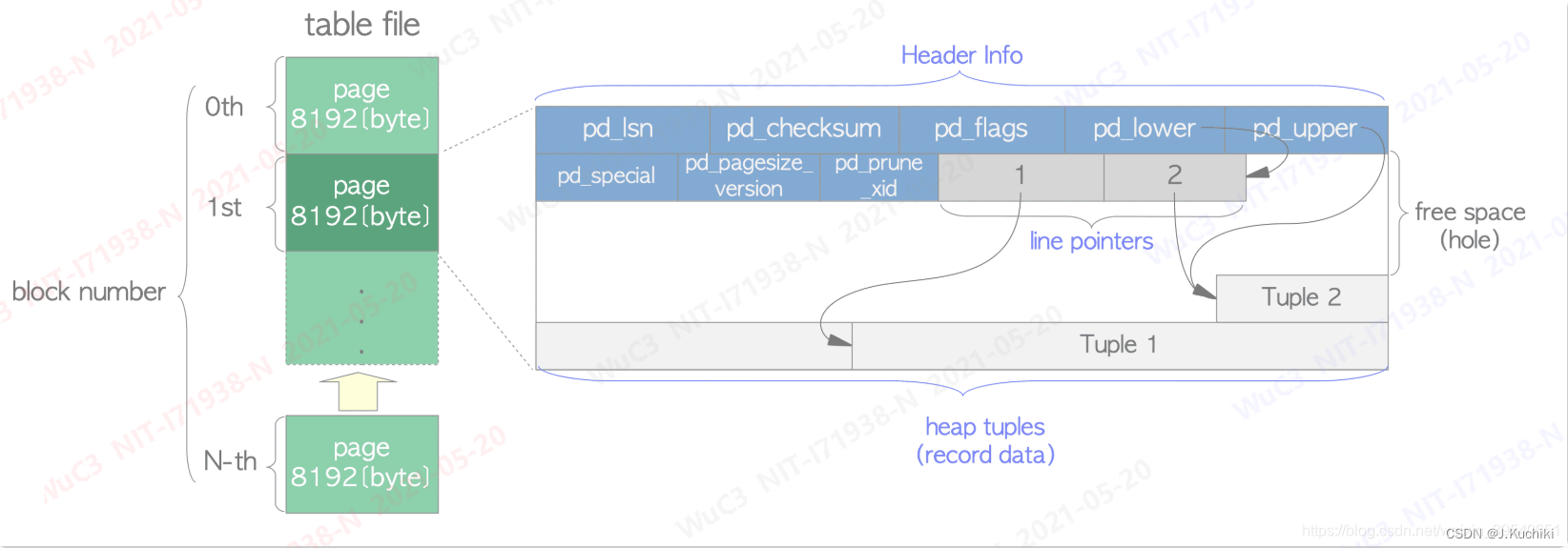
PG物理页面管理—page
一种比较典型的管理方式
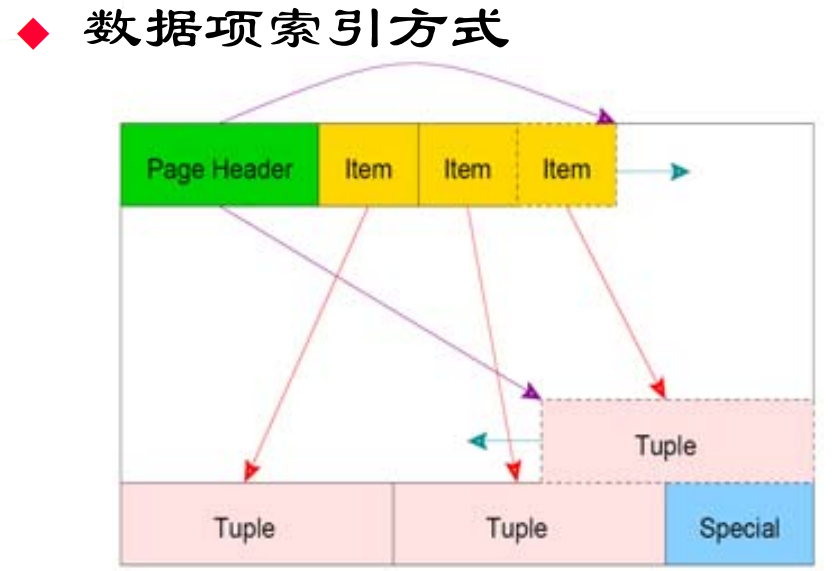
数据项索引方式—bufpage.h
todo 阅读注释
/*
* A postgres disk page is an abstraction layered on top of a postgres
* disk block (which is simply a unit of i/o, see block.h).
*
* specifically, while a disk block can be unformatted, a postgres
* disk page is always a slotted page of the form:
*
* +----------------+---------------------------------+
* | PageHeaderData | linp1 linp2 linp3 ... |
* +-----------+----+---------------------------------+
* | ... linpN | |
* +-----------+--------------------------------------+
* | ^ pd_lower |
* | |
* | v pd_upper |
* +-------------+------------------------------------+
* | | tupleN ... |
* +-------------+------------------+-----------------+
* | ... tuple3 tuple2 tuple1 | "special space" |
* +--------------------------------+-----------------+
* ^ pd_special
*
* a page is full when nothing can be added between pd_lower and
* pd_upper.
* 当pd_lower和pd_upper之间无法添加任何内容时,页面被视为已满。
* all blocks written out by an access method must be disk pages.
*
* EXCEPTIONS:
*
* obviously, a page is not formatted before it is initialized by
* a call to PageInit.
* 在通过PageInit初始化之前,页面是未格式化的。
* NOTES:
*
* linp1..N form an ItemId (line pointer) array. ItemPointers point
* to a physical block number and a logical offset (line pointer
* number) within that block/page. Note that OffsetNumbers
* conventionally start at 1, not 0.
*
* tuple1..N are added "backwards" on the page. Since an ItemPointer
* offset is used to access an ItemId entry rather than an actual
* byte-offset position, tuples can be physically shuffled on a page
* whenever the need arises. This indirection also keeps crash recovery
* relatively simple, because the low-level details of page space
* management can be controlled by standard buffer page code during
* logging, and during recovery.
*
* AM-generic per-page information is kept in PageHeaderData.
*
* AM-specific per-page data (if any) is kept in the area marked "special
* space"; each AM has an "opaque" structure defined somewhere that is
* stored as the page trailer. an access method should always
* initialize its pages with PageInit and then set its own opaque
* fields.
*/
- special space是用于存储特定于访问方法(Access Method, AM)的数据的区域。这个空间通常用来保存对于特定存储和检索技术有用的信息,而这些信息不适合放在页面的标准头部。例如,在使用 B-tree 索引时,这个特殊空间可能会存储关于树分支的特定元数据,如右侧兄弟节点的指针或者其他有助于节点管理的信息。
- 使用行指针(ItemId,也称作 ItemPointers)来管理页面内的数据项。
linp1..N表示一个行指针数组,每个行指针指向页面内部的一条特定数据项的开始位置。 - “向后”添加:意味着最先添加的数据项(tuple1)实际上存放在页面的底部,而后续添加的数据项则依次向页面顶部添加。这种存储方式是反向的,新的数据项被放置在靠近页面顶部的位置。
- 使用ItemPointer偏移量访问数据项:由于数据项通过行指针访问,而不是直接通过字节偏移访问,这使得数据项在页面内的物理位置可以灵活调整,而不影响对这些数据项的引用。即使数据项在页面上的实际位置改变,其在行指针数组中的逻辑位置保持不变。
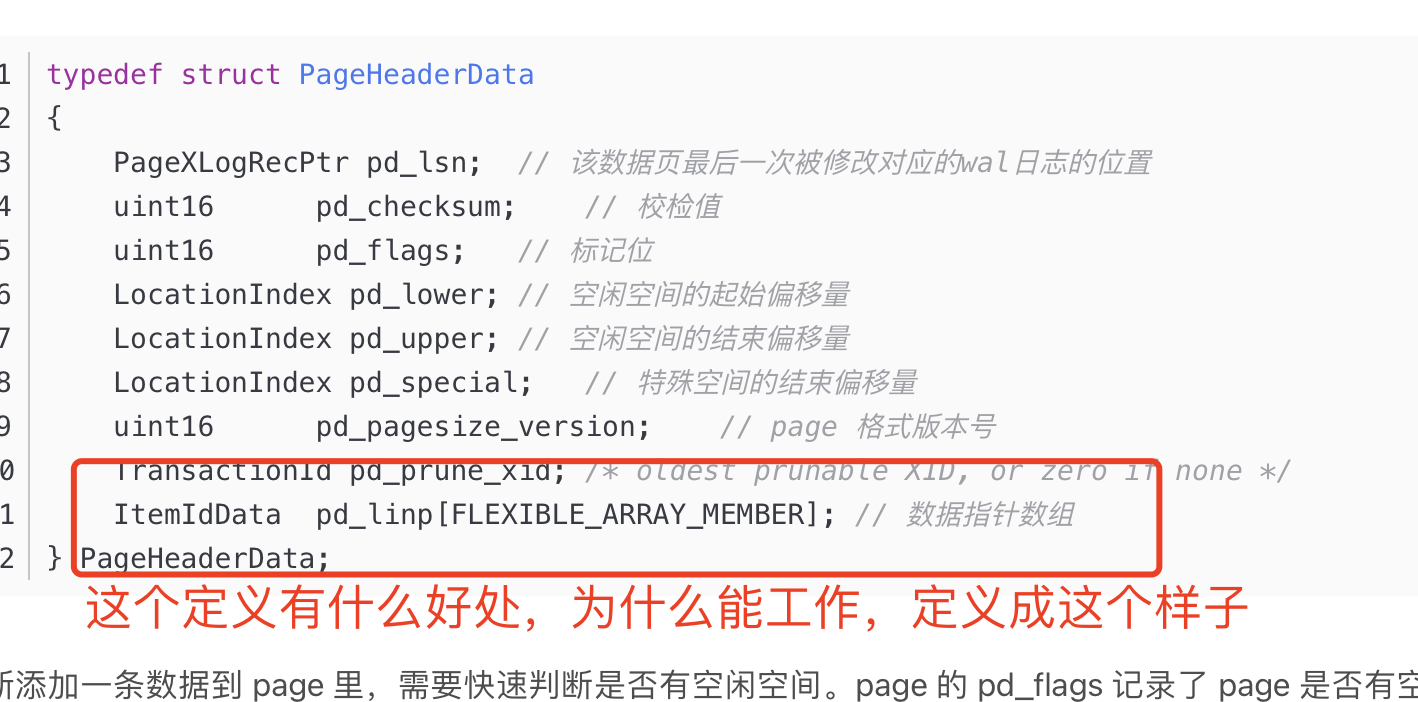
pd_linp表示"line pointer array”每个 ItemIdData 类型的 pd_linp 元素是一个指向数据页面中一条记录的指针,因为page里面的record数量不一定,所以使用这种FLEXIBLE_ARRAY_MEMBER,下面还定义了管理这个结构体的指针
typedef PageHeaderData *PageHeader;
分配方式一般是:该指针malloc,例如:PageHeader= malloc(sizeof(struct PageHeader) + NUM * sizeof(ItemIdData));
如果换成指针
- 初始化的时候 没法定位到后面的linp itemid的位置
- 存的是个指针,还要根据指针去找linp itemid,多一次寻址。
我觉得一个可能是减少写放大的影响 以及 减少内部碎片的大小,但是感觉这种意义也不是很大,根源是什么呢?
ItemIdData
域结构的使用
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
typedef ItemIdData *ItemId;
ItemIdData解读
ItemIdData结构体在 PostgreSQL 中用来表示页面上的行指针(line pointer),其主要功能是指向页面内某条元组(tuple)的位置并描述该元组的一些基本属性。
- lp_off (15位):表示元组在页面上的偏移量,即元组数据从页面开始的位置。这使得系统能够直接跳转到元组的存储位置。
- lp_flags (2位):指示行指针的状态,这对于页面内部元组管理非常重要。该字段的状态决定了行指针(及其指向的元组)的当前状态和处理方式。
- lp_len (15位):指出元组的字节长度。如果
lp_len为0,则表示虽然行指针正在被使用,但它并没有在页面上关联任何实际的存储空间。 - lp_flags 状态值:
- LP_UNUSED (0):未使用的行指针,表示该位置可用于新元组的插入。按照约定,如果一个行指针未被使用,其
lp_len应为0。 - LP_NORMAL (1):正常使用的行指针,表示它指向一个具有实际存储的元组。在正常状态下,
lp_len应大于0,表明存储在该位置的数据具有实际的长度。 - LP_REDIRECT (2):重定向行指针,用于支持 PostgreSQL 的 HOT(Heap-Only Tuple)功能,该功能用于优化更新操作的性能。重定向行指针通常不与存储空间关联,因此其
lp_len应为0。 - LP_DEAD (3):表示该行指针指向的元组已经“死亡”,可能是由于删除操作或其他原因。这种状态的行指针可能还保留着与之关联的存储空间,也可能没有。
- LP_UNUSED (0):未使用的行指针,表示该位置可用于新元组的插入。按照约定,如果一个行指针未被使用,其
Page Init
- 第一个
PageHeader p = (PageHeader) page;page其实是一个指针,而pageheader是pageheaderdata的结构体指针,这里的强制类型转换是把一个通用的字节指针转换成一个具体的结构体指针,这样就可以通过PageHeader指针方便地访问页面头部的各个字段。 - 对
specialSize的对齐MAXALIGN(specialSize);MAXALIGN是用来确保给定的大小是内存对齐的最大可能对齐字节数的倍数(通常是 CPU 架构的字长,如 32位系统是4字节,64位系统是8字节)。内存对齐是为了提高内存访问的效率,对齐的内存访问在大多数硬件上都能提供更好的性能。在这个上下文中,对齐specialSize是为了确保特殊区域在物理内存中对齐,避免潜在的性能问题。 Assert(pageSize > specialSize + SizeOfPageHeaderData);这条断言确保页面的总大小足以容纳特殊区域加上页面头部的大小。这是基本的逻辑检查,确保在页面中为数据留有足够的空间。-
p->pd_flags = 0;初始化页面头部的标志位为 0。p->pd_lower = SizeOfPageHeaderData;设置pd_lower指向页面头部数据之后的第一个位置,即从哪里开始是自由空间。p->pd_upper = pageSize - specialSize;设置pd_upper指向特殊区域开始之前的位置,即自由空间的结束位置。p->pd_special = pageSize - specialSize;设置pd_special也指向特殊区域的开始位置。

物理页面管理–Tuple/Row
access/htup_details.h
#define MaxTupleAttributeNumber 1664 /* 8 * 208 */
#define MaxHeapAttributeNumber 1600 /* 8 * 200 */
设置了单个元组中可以有的最大属性(即列)数量为1664
在 PostgreSQL 中,HeapTuple 代表的是存储在表的堆(heap)中的一个数据行(或元组)。这里的“堆”是指一种数据组织方式,其中数据以行的形式松散存储,允许快速插入、删除和随机访问。堆不是数据结构中的“堆”,而是动态分配的内存区域,用于存储表数据。每个 HeapTuple 包含了实际的行数据以及一些元数据,如事务信息,这些都封装在 HeapTupleHeaderData 结构中。
- HeapTupleFields主要是管理事务的字段,因为pg是多版本,所以这里**
t_xmin** 和t_xmax分别记录插入和删除(或锁定)此元组的事务ID,t_field3是一个union。 DatumTupleFields管理**Datum** 数据类型的字段HeapTupleHeaderData是管理tuple的headert_choice:使用union来存储HeapTupleFields或DatumTupleFields,根据元组是作为表中的一行还是单独的数据值来处理。
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
int32 datum_len_; /* varlena header (do not touch directly!) */
int32 datum_typmod; /* -1, or identifier of a record type */
Oid datum_typeid; /* composite type OID, or RECORDOID */
/*
* datum_typeid cannot be a domain over composite, only plain composite,
* even if the datum is meant as a value of a domain-over-composite type.
* This is in line with the general principle that CoerceToDomain does not
* change the physical representation of the base type value.
*
* Note: field ordering is chosen with thought that Oid might someday
* widen to 64 bits.
*/
} DatumTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
空闲空间管理–freespace
PostgreSQL 使用一个特定的结构,称为 Free Space Map (FSM),来跟踪每个表的数据文件(也称为堆文件)中的可用空间。
Free Space Map 的主要作用是记录表中每个页面的可用空间量。这允许 PostgreSQL 在插入新的元组(行)时快速找到有足够空间容纳该元组的页面,而不必扫描整个表。这种机制显著提高了插入操作的效率,尤其是在大型数据库中。
FSM的工作方式
- 空间跟踪:
- 当表中的页面被修改(例如,插入、更新或删除元组)时,该页面的空闲空间可能会发生变化。
- 每次这种修改发生后,PostgreSQL 更新 FSM 以反映这些变化。这意味着 FSM 必须持续更新以保持其准确性。
- 空间查找:
- 当需要插入新数据时,PostgreSQL 会查询 FSM 来找到一个有足够空闲空间的页面。
- 如果找到了这样的页面,新数据将被写入;如果没有找到,可能需要扩展文件或执行其他操作(如页面压缩)以腾出空间。
- 分级结构:
- FSM 在内部使用一种分级结构来管理空间信息,这种结构类似于一棵树。在这棵树的底层,每个节点代表一个单独的页面,并存储有关该页面空闲空间的信息。
- 随着向上移动至更高层次,每个节点代表一组页面,存储的是这组页面中最大的空闲空间量。这允许快速搜索,而无需查看每个单独的页面。
FSM存储的并不是真是的剩余空间,而是近似值,用一个字节表示剩余空间的大小,也就是说剩余空间分成了256个档次,每8K/256=32为一档,那么,一个字节就足以表示一个block的剩余空间。

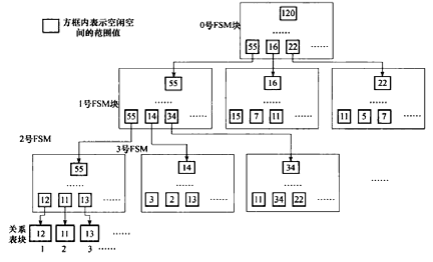
FSM的维护和限制
- 自动维护:
- PostgreSQL 通过后台进程自动维护 FSM,特别是在常规的 VACUUM 操作期间。VACUUM 会清理“死”元组,并更新 FSM 中的空闲空间信息。
- 当数据库系统关闭并重新启动时,FSM 可能会部分重建,因为部分空间使用信息可能不会持久存储到磁盘。
- 限制:
- FSM 的大小和结构设定了其能跟踪的最大页面数。超出这个范围的空间使用情况可能不会被完全跟踪,这可能影响到大型表的空间查找性能。
- FSM 数据自身也需要存储空间,尽管这通常比实际数据要小得多。
fsm_search_avail
函数 fsm_search_avail 是用于在 Free Space Map (FSM) 页面中查找足够的空闲空间以存放新元组的功能。函数的目的是找到至少有 minvalue 字节空闲空间的槽位。如果找到了,返回该槽位的编号;如果没有找到,返回 -1。
/*
* 返回页面根节点的值。
*
* 由于这只是对单个字节的只读访问,因此不需要对页面加锁。
*/
uint8
fsm_get_max_avail(Page page)
{
FSMPage fsmpage = (FSMPage) PageGetContents(page);
return fsmpage->fp_nodes[0];
}
/*
* 搜索至少具有 minvalue 类别的槽位。
* 返回槽位号,如果没有找到则返回 -1。
*
* 调用者必须至少持有页面的共享锁,并且如果需要更新,此函数可以解锁并以排他模式重新锁定页面。
* 如果调用者已持有排他锁,则应将 exclusive_lock_held 设置为 true,以避免额外的操作。
*
* 如果 advancenext 为 false,则 fp_next_slot 设置为指向返回的槽位,如果为 true,则设置为指向返回槽位之后的槽位。
*/
int
fsm_search_avail(Buffer buf, uint8 minvalue, bool advancenext,
bool exclusive_lock_held)
{
Page page = BufferGetPage(buf);
FSMPage fsmpage = (FSMPage) PageGetContents(page);
int nodeno;
int target;
uint16 slot;
restart:
/*
* 首先检查根节点,如果没有足够的空闲空间则快速退出。
*/
if (fsmpage->fp_nodes[0] < minvalue)
return -1;
/*
* 使用 fp_next_slot 开始搜索。这只是一个提示,所以需要检查其合理性。
* (这也处理了当之前的调用返回页面上最后一个槽位时的环绕。)
*/
target = fsmpage->fp_next_slot;
if (target < 0 || target >= LeafNodesPerPage)
target = 0;
target += NonLeafNodesPerPage;
/*
* 从目标槽位开始搜索。每一步,向右移动一个节点,然后上升到父节点。
* 当我们达到有足够空闲空间的节点时停止(我们必须这样做,因为根节点有足够的空间)。
*
* 目的是逐渐扩大我们的“搜索三角形”,即所有由当前节点覆盖的节点,并确保我们从起点向右搜索。
* 在第一步,只检查目标槽位。当我们从左子节点上升到其父节点时,我们将该父节点的右子树添加到搜索三角形中。
* 当我们从右子节点向右然后上升时,我们将放弃当前的搜索三角形(我们知道它不包含任何合适的页面),
* 而是查看其右侧的下一个更大大小的三角形。因此,我们从未从我们的原始起点向左看,
* 并且在每一步中,搜索三角形的大小加倍,确保只需要 log2(N) 的工作量来搜索 N 个页面。
*/
nodeno = target;
while (nodeno > 0)
{
if (fsmpage->fp_nodes[nodeno] >= minvalue)
break;
// 向右移动,如有必要在同一层上环绕,然后上升。
nodeno = parentof(rightneighbor(nodeno));
}
/*
* 我们现在在树的中间位置找到了一个有足够空闲空间的节点。向下到达底部,
* 沿着有足够空间的路径下降,如果有选择,优先向左移动。
*/
while (nodeno < NonLeafNodesPerPage)
{
int childnodeno = leftchild(nodeno);
if (childnodeno < NodesPerPage &&
fsmpage->fp_nodes[childnodeno] >= minvalue)
{
nodeno = childnodeno;
continue;
}
childnodeno++; /* point to right child */
if (childnodeno < NodesPerPage &&
fsmpage->fp_nodes[childnodeno] >= minvalue)
{
nodeno = childnodeno;
}
else
{
/*
* Oops. The parent node promised that either left or right child
* has enough space, but neither actually did. This can happen in
* case of a "torn page", IOW if we crashed earlier while writing
* the page to disk, and only part of the page made it to disk.
*
* Fix the corruption and restart.
*/
RelFileLocator rlocator;
ForkNumber forknum;
BlockNumber blknum;
BufferGetTag(buf, &rlocator, &forknum, &blknum);
elog(DEBUG1, "fixing corrupt FSM block %u, relation %u/%u/%u",
blknum, rlocator.spcOid, rlocator.dbOid, rlocator.relNumber);
/* make sure we hold an exclusive lock */
if (!exclusive_lock_held)
{
LockBuffer(buf, BUFFER_LOCK_UNLOCK);
LockBuffer(buf, BUFFER_LOCK_EXCLUSIVE);
exclusive_lock_held = true;
}
fsm_rebuild_page(page);
MarkBufferDirtyHint(buf, false);
goto restart;
}
}
/* We're now at the bottom level, at a node with enough space. */
slot = nodeno - NonLeafNodesPerPage;
/*
* Update the next-target pointer. Note that we do this even if we're only
* holding a shared lock, on the grounds that it's better to use a shared
* lock and get a garbled next pointer every now and then, than take the
* concurrency hit of an exclusive lock.
*
* Wrap-around is handled at the beginning of this function.
*/
fsmpage->fp_next_slot = slot + (advancenext ? 1 : 0);
return slot;
}