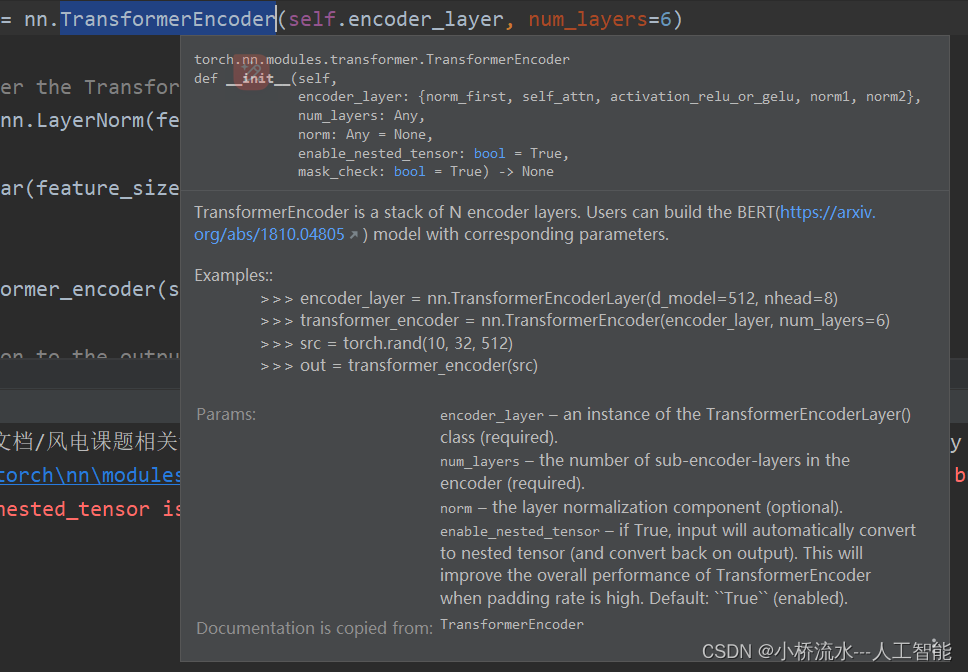
nn.TransformerEncoder
nn.TransformerEncoder 是 PyTorch 的 torch.nn 模块中提供的一个类,用于实现 Transformer 编码器的堆叠。Transformer 编码器通常由多个 nn.TransformerEncoderLayer 堆叠而成,每个层都包含一个自注意力机制和前馈神经网络。
构造函数参数
nn.TransformerEncoder 的构造函数主要接受以下参数:
encoder_layer:一个nn.TransformerEncoderLayer对象的实例或一个继承自nn.Module的自定义编码器层。num_layers:编码器层的数量,即堆叠的层数。norm:层归一化(Layer Normalization)的模块或None。如果为None,则不使用层归一化。
主要特性
- 堆叠的编码器层:通过堆叠多个
nn.TransformerEncoderLayer,模型能够捕获输入序列中更复杂的依赖关系。 - 残差连接:每个编码器层都使用了残差连接,这有助于模型在训练过程中保持梯度的稳定性,从而可以训练更深的网络。
例子
下面是一个使用 nn.TransformerEncoder 的详细例子:
import torch
import torch.nn as nn
# 假设输入序列的长度为 10,特征维度为 512
seq_len = 10
d_model = 512
nhead = 8 # 自注意力机制的头数
num_layers = 6 # 编码器层的数量
# 创建一个 Transformer 编码器层
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=2048, # 前馈神经网络中的隐藏层维度
dropout=0.1,
activation='relu'
)
# 创建一个包含多个编码器层的 Transformer 编码器
encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 创建一个输入张量,形状为 (batch_size, seq_len, d_model)
batch_size = 32
input_tensor = torch.randn(batch_size, seq_len, d_model)
# 将输入张量传递给编码器
output_tensor = encoder(input_tensor)
print("Input shape:", input_tensor.shape)
print("Output shape:", output_tensor.shape)
输出结果

在这个例子中:
我们首先定义了一些超参数,包括输入序列的长度
seq_len、特征维度d_model、自注意力机制的头数nhead和编码器层的数量num_layers。然后,我们创建了一个
nn.TransformerEncoderLayer实例,并设置了其参数。使用
nn.TransformerEncoder创建了一个包含多个编码器层的 Transformer 编码器。这里我们设置了num_layers参数为 6,意味着我们堆叠了 6 个encoder_layer。接着,我们创建了一个随机的输入张量
input_tensor,其形状为(batch_size, seq_len, d_model)。最后,我们将输入张量传递给编码器
encoder,得到了输出张量output_tensor。
输出张量的形状将与输入张量的形状在除了最后一个维度外保持一致,因为每个编码器层不会改变序列的长度,但可能会改变特征的维度(这取决于 d_model 和 dim_feedforward 的设置)。