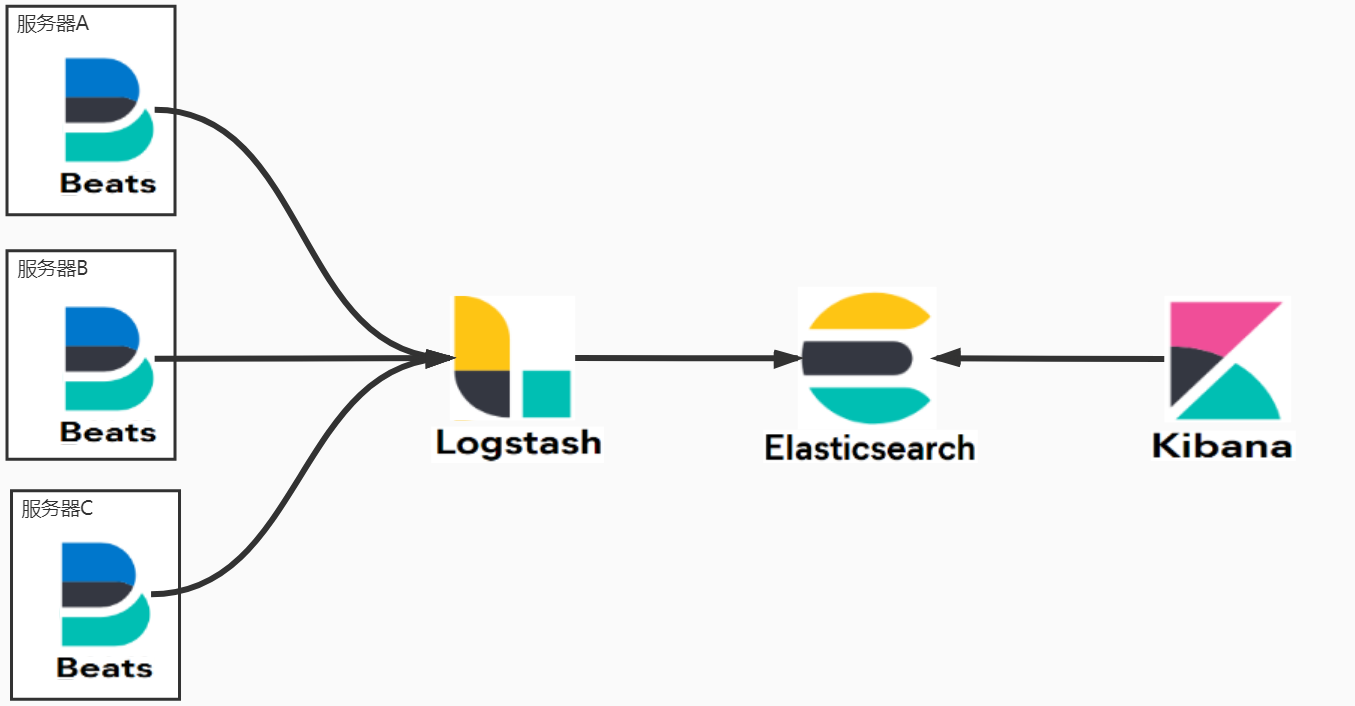
什么是ELK
ELK是一个开源的数据分析平台,它由Elasticsearch,Logstash和Kibana组成。
Elasticsearch是一个分布式的实时搜索和分析引擎,可用于存储、搜索和分析各种类型的结构化和非结构化数据。它具有高可用性、可扩展性和弹性,可以处理大规模的数据集。
Logstash是一个开源的数据采集引擎,用于实时地将各种数据源的日志和事件数据转换、传输和保存到Elasticsearch中。它可以从各种来源(如文件、数据库、消息队列等)收集数据,并对数据进行处理、转换和过滤,最后将数据发送到Elasticsearch中。
Kibana是一个开源的数据可视化和分析平台,用于实时地查询、分析和可视化Elasticsearch中的数据。它提供了丰富的图表、图形和仪表盘,可以帮助用户理解和发现数据中的模式、趋势和异常。
ELK应用场景
ELK(Elasticsearch, Logstash, Kibana)是一套实时日志分析系统,由Elasticsearch作为搜索与分析引擎、Logstash作为数据收集与处理工具、Kibana作为数据可视化工具组成。ELK广泛应用于日志管理、监控、安全分析等领域。下面是ELK的一些常见应用场景:
日志管理与分析:ELK可以收集、存储和分析大量的日志数据。通过使用Logstash进行数据收集和处理,Elasticsearch进行实时搜索和分析,Kibana进行数据可视化,可以快速发现潜在的问题、异常及趋势。
系统监控:ELK可以收集系统产生的各种指标数据,如CPU使用率、内存使用率、网络流量等,通过实时监控和可视化展示,帮助用户了解系统的运行状态,并进行性能优化和故障排查。
安全分析与威胁检测:ELK可以收集和分析网络设备、服务器和应用程序的日志,通过实时搜索和分析,可以发现异常登录、恶意访问、数据泄漏等安全事件,并及时进行响应和防御。
业务智能分析:ELK可以分析企业的业务数据,如销售数据、用户行为数据等,通过实时搜索和可视化展示,帮助企业了解客户需求、市场趋势,做出合理的决策和战略规划。
应用程序日志分析:ELK可以收集和分析应用程序产生的日志,帮助开发人员定位和解决应用程序的问题,提高应用程序的稳定性和性能。
ELK的作用
Elasticsearch是一个分布式的搜索和分析引擎,它能够处理大规模的数据,并提供实时的搜索和分析功能。Elasticsearch使用倒排索引技术,使得搜索和过滤操作非常高效。它支持多种数据类型,包括结构化数据、文本数据和地理位置数据等。Elasticsearch还具有自动分片和复制功能,保证数据的可靠性和高可用性。
Logstash是一个日志收集工具,它能够从多个来源收集日志数据,并进行解析和转换。Logstash支持多种输入源,包括文件、网络、消息队列等。它还可以对日志数据进行过滤和处理,如提取关键字段、转换数据格式等。Logstash还支持多种输出目的地,如Elasticsearch、数据库、消息队列等。
Kibana是一个可视化工具,它能够将Elasticsearch中的数据以图表和表格的形式展示出来。Kibana提供了丰富的可视化功能,包括直方图、饼图、地图等。用户可以使用Kibana进行搜索、过滤和分析数据。Kibana还支持创建仪表盘,将多个可视化组件组合在一起,形成一个综合的展示界面。
ELK的作用主要有以下几个方面:
日志管理和分析:ELK可以收集、存储和分析各种类型的日志数据。通过使用Elasticsearch的搜索和分析功能,用户可以快速定位和解决问题,提高系统的运行稳定性和可靠性。
实时监控和告警:ELK可以实时监控系统的运行状态,包括CPU使用率、内存利用率、网络流量等指标。当发生异常情况时,ELK可以发送告警通知,帮助用户及时处理问题。
数据可视化:ELK可以将数据以图表和表格的形式展示出来,帮助用户更直观地理解数据。用户可以通过Kibana创建定制化的可视化仪表盘,将关键指标和数据展示在一个界面上,帮助用户快速了解系统的运行状况和趋势
实例
- 引入依赖 在项目的
pom.xml文件中添加以下依赖:
<dependencies>
<!-- Elasticsearch 集成 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
</dependencies>
- 配置elk连接信息 在
application.properties(或application.yml)文件中配置elk的连接信息:
# Elasticsearch 配置
spring.data.elasticsearch.cluster-nodes=localhost:9200
spring.data.elasticsearch.cluster-name=my-application
- 创建实体类 定义一个实体类,映射到elk中的文档:
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Document(indexName = "my_index", type = "my_type")
public class MyEntity {
@Id
private String id;
private String name;
// getter和setter方法
}
- 创建Elasticsearch Repository 创建一个继承自
ElasticsearchRepository的接口,用于操作elk中的文档:
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface MyEntityRepository extends ElasticsearchRepository<MyEntity, String> {
// 自定义查询方法
}
- 使用elk进行操作 在业务代码中注入
MyEntityRepository,然后可以对elk中的文档进行增删改查操作:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class MyEntityService {
@Autowired
private MyEntityRepository myEntityRepository;
public MyEntity save(MyEntity entity) {
return myEntityRepository.save(entity);
}
public Optional<MyEntity> findById(String id) {
return myEntityRepository.findById(id);
}
public void delete(MyEntity entity) {
myEntityRepository.delete(entity);
}
// 其他自定义操作方法
}
上述代码中的各个部分说明如下:
- 第1步中的依赖是用于集成elk的必要依赖,其中
spring-boot-starter-data-elasticsearch是Spring Boot提供的elk集成starter,elasticsearch-rest-high-level-client是elasticsearch的高级客户端。 - 第2步中的连接信息指定了elk集群的地址和名称。
- 第3步中的实体类使用
@Document注解指定了该实体类映射到elk中的索引(index)和类型(type)。 - 第4步中的Repository接口继承自
ElasticsearchRepository,该接口提供了一些基本的CRUD方法,也可以自定义查询方法。 - 第5步中的Service类注入了
MyEntityRepository,可以在业务代码中进行elk的操作。
总结
ELK是一个开源的日志管理和分析平台,由Elasticsearch、Logstash和Kibana三个工具组成。它们相互协作,使得用户能够收集、存储、搜索、分析和可视化大量的日志数据。
三个主要组件及其功能的详细总结:
Elasticsearch:Elasticsearch是一个基于Lucene的实时搜索和分析引擎,用于存储和查询日志数据。它能够处理大量的结构化和非结构化数据,并提供快速、实时的搜索和分析功能。Elasticsearch具有分布式和水平扩展的特性,可以在多个节点上存储和处理数据,从而实现高可用性和高性能。
Logstash:Logstash是一个用于收集、过滤和转换日志数据的工具。它支持从各种不同的来源收集数据,包括文件、网络、消息队列等。Logstash提供了强大的过滤和转换功能,可以对日志数据进行分析和处理,并将其发送到Elasticsearch进行存储和索引。
Kibana:Kibana是一个用于可视化和分析日志数据的工具。它提供了直观的Web界面,用户可以通过图表、表格和地图等方式对数据进行可视化展示和查询。Kibana还支持实时监控和警报功能,帮助用户监控系统状态和进行异常检测。
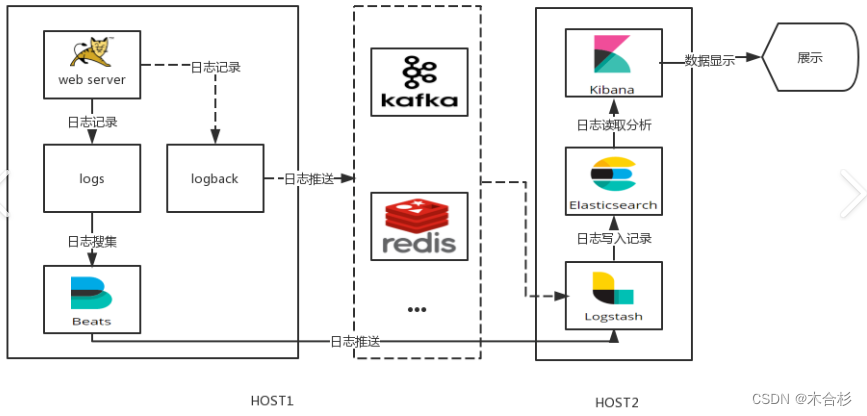
ELK的工作流程如下:
Logstash收集日志数据:Logstash从各种不同的来源收集日志数据,并对其进行过滤和转换。它可以解析不同的日志格式,对数据进行结构化处理,并添加额外的元数据。
Logstash发送数据到Elasticsearch:经过过滤和转换后,Logstash将处理后的日志数据发送到Elasticsearch进行存储和索引。Elasticsearch将数据分布式地存储在多个节点上,以实现高可用性和性能。
Kibana可视化和分析数据:Kibana连接到Elasticsearch,通过查询和聚合数据,生成各种图表和可视化展示。用户可以通过Kibana的Web界面进行数据探索、分析和报表生成。
ELK的优势包括:
强大的搜索和分析功能:Elasticsearch提供了快速、实时的搜索和分析能力,使用户能够轻松地在海量日志数据中查找和过滤信息。
灵活的数据收集和转换:Logstash支持多种数据源和格式,可以对日志数据进行灵活的收集、过滤和转换操作。
直观的可视化界面:Kibana提供了直观的Web界面,使用户能够以交互方式探索和分析数据,并生成各种图表和可视化展示。
可扩展的架构:ELK采用分布式和水平扩展的架构,能够处理大规模的数据,并保持高可用性和性能。