23年12月,腾讯、新加坡国立大学联合发布DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing。
DynVideo-E框架首次引入动态NeRF作为视频表示,通过人体姿态引导将视频信息聚合到3D背景空间和3D动态人体空间中,进而能对大规模运动、视图变化和以人为中心的视频进行编辑。同时为了提高编辑后的三维动态人体空间的一致性和动画性,模型还提出了一组有效的设计和训练策略:利用二维和三维扩散先验、多视角多位姿分数蒸馏采样SDS,重建损失、文本引导局部超分辨率,以及各种人体和相机姿态配置。DynVideo-E使用HOSNeRF作为backbone模型,可以为动态场景实现360°自由视点、高保真、高时间一致的可控视频合成,在HOSNeRF和NeuMan数据集上性能明显优于 SOTA 方法。
本本借鉴了先前众多模型的工作成果,在训练和推理阶段直接拿来用,方便但是复杂。
Abstract
基于扩散的视频编辑最近取得了进展,但由于远程一致性和逐帧编辑之间的矛盾,现有方法仅限于短视频。之前试图通过引入video-2D表示来解决这一挑战,在大规模运动和视角变化视频,特别是在以人为中心的场景中遇到了比较大的困难。为了克服这个问题,我们引入动态神经辐射场 (NeRF) 作为创新的视频表示,其中编辑可以在 3D 空间中执行,并通过变形场传播到整个视频。为了提供一致和可控的编辑,我们提出了基于图像的video-NeRF编辑管道,并设计了一套创新的设计,包括来自2D个性化扩散先验和3D扩散先验的多视图多姿态分数蒸馏采样(Score Distillation Sampling,SDS)、重建损失、文本引导局部超分辨率、风格迁移。大量的实验表明,我们的方法DynVideo-E在两个具有挑战性的数据集上显著优于SOTA方法,在人类偏好方面的优势高达50% ~ 95%。代码将会发布代码将在 https://showlab.github.io/DynVideo-E/。
1. Introduction
图像扩散模型的显著成功,引发了人们的极大兴趣,特别是扩展它以支持视频编辑。尽管很有希望,但它在保持高时间一致性方面碰到了重大挑战。为了解决这个问题,现有基于扩散的视频编辑方法已经发展到从源视频中提取和合并各种对应关系到逐帧编辑过程中,包括注意力图、空间图 、光流和神经场。虽然这些作品已经证明了编辑结果的时间一致性,但远程一致性和逐帧编辑之间的内在矛盾,限制了这些方法只能用于具有很小运动和视点变化的短视频。
另一项研究旨在引入中间video-2D表示,将视频编辑降级为图像编辑,例如使用分层神经图谱分解视频,并将时空内容映射到2D UV。因此,编辑可以在单帧或图谱本身上执行,编辑的结果始终传播到其他帧。最近,CoDeF提出了基于二维哈希的规范图像与三维变形场相结合,进一步提高了视频的能力。然而,这些方法是视频内容的 2D 表示,因此它们在大规模运动和视点变化的情况下表示和编辑遇到了重大困难,尤其是在以人为中心的场景中。
这促使我们为大规模运动和视图变化的以人为中心的视频编辑引入video-3D表示。动态NeRF的最新进展表明,3D 动态人体空间与人体姿态引导变形场相结合可以有效地重建具有大运动和视点变化的单个以人为中心的视频。
- NeuMan: Neural Human Radiance Field from a Single Video
- HOSNeRF: Dynamic Human-0bject-Scene Neural Radiance Fields from a Single Video
- HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
在本文中,我们提出了 DynVideo-E,首次引入了动态 NeRF 作为具有挑战性的以人为中心的视频编辑的创新视频表示。这样的Video-NeRF表示通过人体姿态引导变形场有效地将大规模运动和视图变化的视频信息聚合到3D背景空间和3D动态人体空间中,从而可以在3D空间中执行编辑,并通过变形场传播到整个视频。
为了提供一致且可控的编辑,我们提出了具有一组基于图像的Video-NeRF编辑管道。这些包括
- 根据人体姿势和相机视点,重建参考图像损失,以将主体内容从参考图像注入 3D 动态人体空间。
- 为了提高编辑后的三维动态人体空间的三维一致性和动画性,我们从二维个性化扩散先验和三维扩散先验中设计了一个多视角、多位姿分数蒸馏采样SDS,以及在各种人体姿势和相机姿势配置下的一组训练策略。
- 为了提高三维动态人体空间的分辨率和几何细节,我们利用文本引导局部放大超分辨率,并根据视图条件增强了7个语义体区域。
- 我们使用样式转换模块将参考样式转移到我们的3D背景模型中。经过训练,我们的video- NeRF模型可以沿着源视频视点呈现高度一致的视频,通过变形场传播编辑的内容。它可以为编辑的动态场景实现360°自由视点高保真新视图合成。
我们在 HOSNeRF 和 NeuMan 数据集上广泛评估了DynVideo-E,在11个具有挑战性的动态的以人为中心的视频中,有24个编辑提示的情况下。
如图 1 所示,DynVideo-E 以非常高的时间一致性生成逼真的视频编辑结果,并且在人类偏好方面明显优于 SOTA 方法。

图 1. 给定一个参考主体图像和背景样式图像,DynVideo-E 能够对大规模运动、视图变化、以人为中心的视频 (a-c) 进行高度一致的编辑。
### 左侧给定绿巨人编辑主体人物,右侧给定背景风格图像,模型可以同时实现对视频序列前景和背景的编辑效果。
总而言之,本文的主要贡献是:
- 提出了 DynVideo-E 框架,该框架首次引入了 Video-NeRF作为视频表示。
- 在Video-NeRF模型中,提出了一组有效的设计和训练策略。
- DynVideo-E 在两个数据集上显着优于 SOTA 方法。
2. Related Work
2.1. Diffusion-based
Video Editing
由于扩散模型的强大力量,先前的工作已经将他们扩展到视频编辑Fatezero、Tune-A-Video和视频生成Align the latent、show-1。Tune-A-Video通过跨帧注意图像扩散,并对源视频进行微调,旨在隐式学习源运动并将其转移到目标视频中。尽管Tune-A-video展示了跨不同视频编辑应用程序的多功能性,但它表现出较差的时间一致性。随后的作品从源视频中提取各种对应关系,并使用它们来提高时间一致性。FateZero和Video-P2P从源视频中提取交叉和自注意来控制空间布局。Rerender-A-Video、ControlVideo 和 TokenFlow 从源视频中提取和对齐光流、空间图和神经辐射场,从而提高了编辑结果的一致性。尽管这些工作显示了有希望的结果,但它们通常用于小规模运动和视图变化的短视频编辑场景。
另一类视频编辑工作依赖于强大的视频表示,即分层神经图谱作为中间编辑表示。分层神经图谱使用分层表示分解输入视频,并将所有帧的主体和背景映射到 2D UV。一旦学习了分层神经图谱,编辑就可以发生在关键帧或图谱本身上,编辑结果始终传播到其他帧。CoDeF 将 3D 变形场与基于 2D 哈希的规范图像相结合,以进一步提高视频的表示能力。然而,分层神经图谱和规范图像都是视频内容的伪3D表示,它们在重建具有大规模运动和视点变化的视频时遇到了困难。
2.2. Dynamic NeRFs
自神经辐射场 NeRF的引入以来,新视图合成领域取得了重大进展。随后的研究通过学习一个变形场,将采样点从变形空间映射到规范空间或构建4D时空辐射场,将其扩展到从单目视频中重建动态NeRF。其他研究引入了体素网格或平面表示来提高动态 NeRF 的训练效率。虽然这些方法已经显示出有希望的结果,但它们仅限于具有简单变形的短视频。另一项工作侧重于人体建模并利用估计的人体姿势先验来重建具有复杂运动的动态人体。最近,NeuMan将动态人体 NeRF 与静态场景 NeRF 一起重建,以模拟以人为中心的场景。HOSNeRF进一步提出使用状态条件动态人体模型和无界背景模型来表示复杂的人-物场景,从单个视频中实现360°自由视点渲染。相比之下,我们的目标是引入动态NeRF作为以人为中心的视频编辑的创新Video-NeRF表示。
2.3. NeRF-based Editing and Generation
自扩散模型的引入以来,文本引导的3D NeRF编辑和生成已经从基于CLIP的发展到基于2D扩散方法。SINE支持通过预训练的 NeRF 先验将编辑的内容传递给多视图,从单个视图中编辑静态 NeRF 的本地区域。ST-NeRF提出了一种时空神经分层辐射表示来表示具有分层 NeRF 的动态场景,它可以通过操纵 NeRF 层来实现简单的编辑,例如仿射变换或复制。然而,它需要 16 个摄像头来捕获动态场景,并且不能编辑分层 NeRF 的内容。随后的工作,如Control4D和Dyn-E,建议编辑动态NeRF的内容。然而,Control4D仅限于具有小运动、短视频长度人体场景,而 Dyn-E 仅通过显式用户操作支持编辑局部外观。
3. Method
3.1. Video-NeRF Model
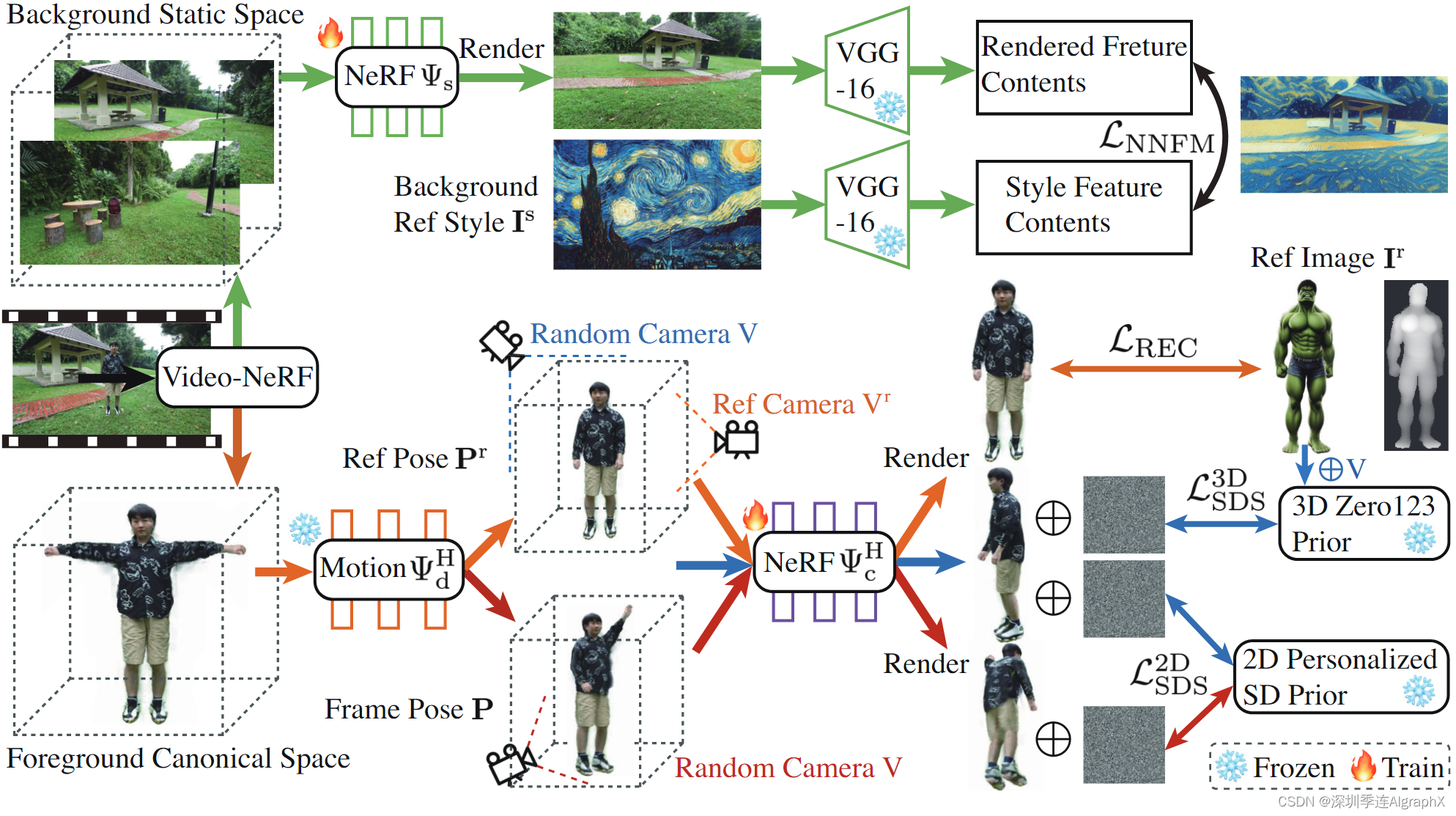
图 2. DynVideo-E 总览。1)Video-NeRF模模型将输入视频表示为三维动态人体空间,耦合了变形场和三维静态背景空间。2)橙色流程图:给定参考主体图像,我们通过利用重建损失、2D个性化扩散先验、3D扩散先验和局部超分辨率,在多视图多姿态配置下编辑可动画化的3D动态人体空间。3)绿色流程图:利用特征空间中的样式传递损失将参考样式传递到我们的3D背景模型。4)在源摄像机姿态下,可以通过在video-NeRF模型中进行体积渲染来相应地渲染编辑视频,我们还可以实现编辑动态场景的高保真度自由视点渲染。

图 5. DynVideo-E 网络设计:(a)编辑背景模型,(b)原始人体模型,(c)编辑人体模型。
Motivation
给定视点变化大、错综复杂的场景内容、人体运动复杂的单一视频,我们寻求使用动态NeRF来表示此类视频进行视频编辑。HOSNeRF最近提出了从单个单目野外视频中重建动态人体—物体—场景交互的动态神经辐射场,并达到了新的SOTA性能。它提出了状态条件三维动态人—物模型和三维背景模型,分别表示动态人—物和静态背景。因此,我们利用HOSNeRF作为我们video-NeRF基础模型来表示由动态人体、动态物体和静态背景组成的大规模运动、视图变化的以人为中心的视频。由于我们的目标是在保持交互对象不变的情况下编辑动态的人和无界背景,因此我们利用原始重构的HOSNeRF模型来保留交互对象,并通过删除用于视频编辑的对象状态设计,将HOSNeRF简化为HSNeRF。
因此,我们的Video-NeRF模型由一个动态人体模型和一个静态场景模型
组成。
3D Dynamic Human Model
将所有视频帧中的动态信息聚合到一个3D规范人体空间ΨH/c 以及一个人体姿态引导的变形场ΨH/d。
ΨH/c 将3D点映射到颜色 c 和密度 d。
ΨH/d将帧 i 处的变形空间xi/d映射到规范点xi/c(为简单起见省略i)。
![]()
其中γ (x)是标准的位置编码函数,J = {Ji} 和 R = {ωi} 分别是 3D 人体关节和局部关节轴向旋转角度。
遵循 HOSNeRF 和 HumanNeRF ,我们将变形场 ΨH/d 分解为:
粗略的人体骨骼驱动变形 ;
以人体姿势 为条件的精细非刚性变形。
![]()
3D Static Scene Model
ΨS将复杂的静态场景内容聚合成一个Mip-NeRF 360空间,该空间将缩减的高斯参数(ˆμ,ˆΣ)映射到颜色 c 和密度 d。

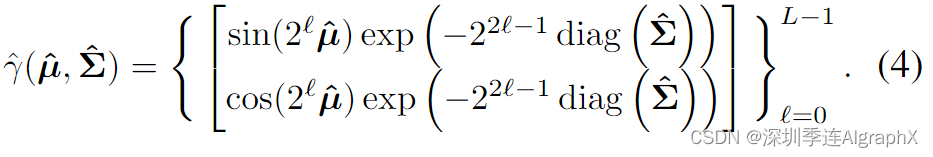
为了获得缩减的高斯参数,我们首先将射光线分割成一组区间Ti=[ti,ti+1]并计算它们对应圆锥截体平均值和协方差 (μ,Σ)=r(Ti)。
然后,我们采用Mip-NeRF 360中提出的收缩函数f (x)对远点按视差比例进行分布,并将无界场景的高斯参数参数化,如下所示:
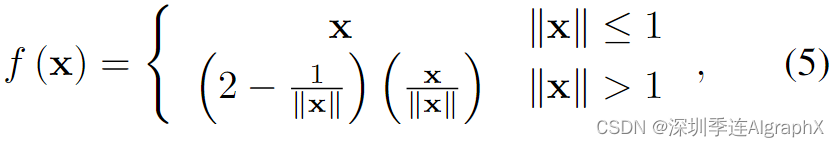
和f (x)应用于(μ, Σ),得到缩减高斯参数:
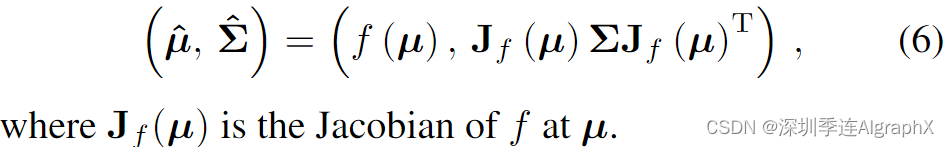
Video-NeRF Optimization
给定使用COLMAP校准相机姿势的单个视频,VideoNeRF模型通过最小化渲染的像素颜色和ground-truth像素颜色之间的差异来训练。为了渲染像素颜色,我们在三维动态人体模型和场景模型中拍摄光线并查询场景属性,并根据它们与相机中心的距离重新排序所有采样属性。然后,可以通过体积渲染来计算像素颜色。

遵循HOSNeRF,我们通过最小化光度 MSE 损失、基于patch的感知 LPIPS 损失和 Mip-NeRF 360 提出的正则化损失来优化我们的视频 NeRF 表示,以应对背景崩溃、变形循环一致性和间接光流监督等。详情请参阅 HOSNeRF。
3.2. Image-based Video-NeRF Editing
Motivation
以前的视频编辑工作主要通过文本提示进行的预期编辑。然而,细节和主体身份通过参考图像能更好地传达。为此,我们专注于基于图像的编辑,以实现更精细、更直接、更好的可控性。如图2所示,我们的Video-NeRF模型代表了具有3D动态人体空间和3D背景空间的大规模运动和视图变化以人为中心的视频。
因此,为了更好地解决前景和背景编辑,我们建议使用参考主体图像及其文本描述编辑 3D 动态人体空间,并使用参考风格图像编辑背景静态空间。
3.2.1 Image-based 3D Dynamic Human Editing Challenges
Challenges
一致且高质量基于图像的视频编辑要求编辑3D动态人体空间
- 保持参考图像的主体内容;
- 源视频中的人体姿势可动画化;
- 大规模运动和视点变化一致;
- 精细细节的高分辨率。
为了应对这些挑战,我们设计了一组策略。
Reference Image Reconstruction Loss
我们利用参考主体图像 Ir 来提供更精细的身份控制并允许个性化的人工编辑。为了确保参考图像与源人体姿势相似,我们利用ControlNet来生成以源人体姿势 Pr 为条件的参考主体图像,如图2所示。
然后,我们使用预训练的单目深度估计器来估计参考主体的伪深度Dr,并使用SAM获得其掩码Mr。在训练过程中,我们假设参考图像视点是前视图(参见图2中 Camera Vr),并在我们的Video-NeRF表示下渲染主体图像ˆIr,由 Vr 处的源人体姿势 Pr 驱动。我们还通过整合每个像素射线的体积密度和采样距离来计算 Vr 处的渲染掩码ˆMr 和深度ˆDr。遵循Magic模型,我们使用参考图像和掩码上的均方误差(MSE)损失以及伪深度图上的归一化负Pearson相关来监督 Vr 视点上的框架。
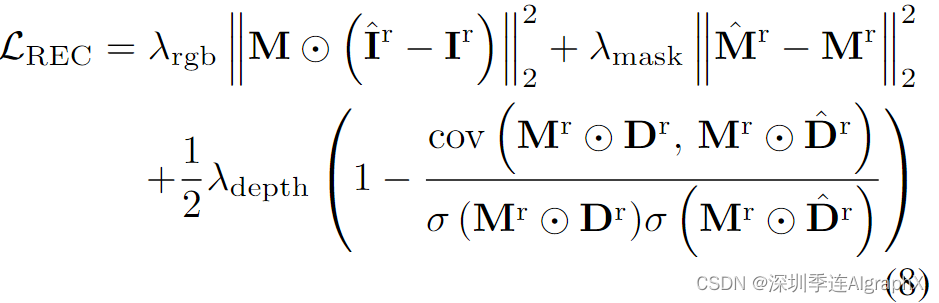
其中λrgb、λmask、λdepth为损失权值,⊙为Hadamard积,cov(·)为协方差,σ(·)为标准差。
Score Distillation Sampling (SDS) from 3D Diffusion Prior
虽然 可以提供对参考图像内容的监督,但它仅适用于参考视图 Vr 处的源人体姿势 Pr。为了从参考图像提供更多的 3D 监督,我们利用在 Objaverse-XL 上预训练的 Zero1-to-3 作为 3D 扩散先验,然后使用 SDS 损失从参考图像中提取固有的 3D 几何和纹理信息。
给定具有噪声预测网络 εφ(·) 的 3D 扩散模型 φ,SDS损失是通过直接最小化添加到编码渲染图像 I 的注入噪声 ε 和预测的噪声来实现的。因此,我们在随机相机视点V=[R,T]处渲染来自由源人体姿态Pr驱动的3D动态人体空间图像 I,并且可以使用参考图像Ir和相机姿势[R,T]作为条件来计算Zero-1-3的SDS损失:
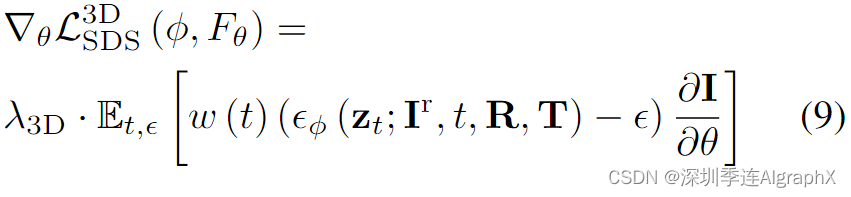
其中zt是通过将水平为 t 的随机高斯噪声注入编码的渲染图像 I 而得到的噪声潜在图像 I。w(t) 是一个取决于噪声水平的加权函数。θ 是我们的 DynVideo-E 的可优化参数。
### 作者发现,如果给定一张参考图像而不是文本,模型可以更细粒度的理解用户的编辑目的。为此提出使用图像扩散先验来实现更精细的控制。为了从参考图像中获得更多的3D监督信号,作者使用3D扩散模型提取参考图像固有的3D几何和纹理信息作为3D扩散先验,给定带有噪声预测网络εφ(·) 的3D扩散模型 φ ,就可以通过最小化添加到渲染图像和预测网络中注入的噪声来构造SDS损失函数。
利用了 Objaverse-XL 上预训练的 Zero1-to-3 作为 3D 扩散先验。
SDS from 2D Personalized Diffusion Prior
上述参考图像引导监督仅限于编辑由源人体姿势 Pr 驱动的 3D 人体空间,因此不足以产生令人满意的 3D 动态人体空间,该空间可以由来自源视频帧的人体姿势动画化。
为此,我们进一步使用来自源视频帧的人体姿势 P 对3D动态人体空间进行动画处理,并在随机相机姿势V渲染图像 I ,并进一步提出使用基于2D文本的扩散先验来指导这些渲染视图。然而,天真地使用 2D 扩散先验阻碍了从参考图像中学习到个性化内容,因为 2D 扩散先验倾向于纯粹从文本描述中想象主体的内容,如图 4 所示。为了解决这个问题,我们进一步建议使用2D个性化扩散先验,该先验首先使用Dreambooth-LoRA对参考图像进行微调。为了生成Dreambooth-LoRA的更多输入,我们用随机背景增强参考图像,并利用Magic123使用多视图增强参考图像。
Dreambooth-LoRA使用噪声预测网络εφ '(·)微调二维个性化扩散先验φ ',我们进一步使用2D SDS损失来监督:
- 来自源视频人体姿势动画化的3D动态人体空间渲染图像 I
- 和以随机相机姿势进行渲染的图像。
形式化为

### 3D扩散先验仅来源于人体姿态 ,不足以产生满足对人体交互细节进行处理的3D动态空间,因此作者进一步提出使用基于 2D 文本的个性化扩散先验来进行引导。

另外,去除微调Dreambooth-LoRA,模型会错误理解参考图像的个性化内容,体现在后背看不清,不平滑。
Text-guided Local Parts Super-Resolution.
由于 GPU 内存限制,我们的 DynVideo-E 使用 (128 × 128) 分辨率进行训练,从而产生粗糙的几何形状和模糊的纹理。为了解决这个问题,受DreamHuman的启发,我们利用文本引导的局部部分超分辨率来渲染和监督放大人体的局部部分,有效提高了分辨率。由于我们的动态人体模型是在“T-pose”配置下的人体姿势驱动的 3D 规范空间,我们可以通过直接定位靠近相应部分的相机来准确渲染放大的局部人体部分。具体来说,我们利用 7 个语义区域:全身、头部、上半身、中、下半身、左臂和右臂,并相应地用身体部位修改输入文本提示,并用视图条件提示额外增强这些提示:前视图、侧视图和后视图。由于遮挡很难跟踪手臂在所有人体姿势下的位置,我们只在“T-pose”下放大手臂的位置。
Dynamic Objects
对于具有动态交互对象的以人为中心的视频,我们利用原始重建的 HOSNeRF 模型来渲染交互的对象。在推理过程中,我们查询原始HOSNeRF模型中的对象掩码内的光线,并查询编辑后的video-NeRF模型中对象掩码外的光线。因此,我们可以在编辑的视频中保持动态对象。
3.2.2 Image-based 3D Background Editing
我们的目标是将任意 2D 参考风格图像的艺术特征转移到我们的 3D 无界场景模型中。如图 2 的绿色流程图所示,我们从ARF模型中获得灵感,并采用其最近邻特征匹配(NNFM)风格损失将语义视觉细节从2D参考图像 Is 转移到我们的3D背景模型ΨS。我们还利用延迟反向传播直接全分辨率渲染优化我们的模型。具体来说,我们渲染背景图像 I ,并分别提取 I 和 Is(2D参考图像) 的 VGG 特征图 F 和 Fs,Lnnfm 最小化渲染特征图与2D参考特征图余弦距离。
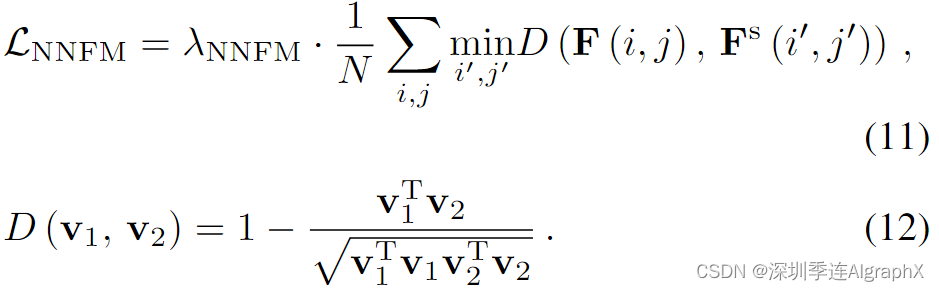
为了防止 3D 场景模型偏离源内容太多,我们还添加了一个额外的 L2 损失惩罚 F 和 Fs 之间的差异
### 完成视频主体人物调整后,作者希望能够将给定的2D参考图像中的艺术风格迁移到视频的3D背景中。从ARF模型得到灵感,采用最近邻特征匹配风格损失NNFM来获取风格信息。具体来说,渲染 3D 背景图像 I 是通过计算VGG 渲染特征图 F 和参考特征图 Fs 之间余弦距离进行。
3.3. Training Objectives
DynVideo-E 的训练包括两个阶段。首先,我们在源视频中重建我们的视频-NeRF模型。其次,在给定参考图像和文本提示的情况下,我们编辑 3D 动态人体空间和 3D 无界场景空间。训练后,使用video-NeRF模型沿源摄像机视点渲染编辑的视频,我们还实现了自由视点渲染。
Multi-view Multi-pose Training for 3D Dynamic Human Spaces
如图2所示,我们在训练期间设计了一个具有三个条件的多视图多姿态训练过程。
4. Experiments
Dataset
为了在长视频和短视频上评估我们的 DynVideo-E,我们利用每个视频 [300, 400] 帧的 HOSNeRF 数据集和每个视频 [30, 90] 帧的 NeuMan 数据集,所有这些分辨率都为 (1280 × 720)。总的来说,我们在11个具有挑战性的动态的以人为中心的视频上设计了24个编辑提示,以评估我们的DynVideo-E和所有SOTA方法。
4.1. Comparisons with SOTA Approaches
Baselines
与五种SOTA方法进行了比较,包括Text2Video-Zero、RerenderA-Video、Text2LIVE、StableVideo和CoDeF。我们利用 Midjourney * 生成参考图像的文本描述来训练这些基线。
Quantitative Results
我们为长视频 (a) 和短视频 (b) 中展示了我们的方法与图 3 中的所有基线的视觉比较。由于这两个视频都包含较大的运动和视点变化,所有基线都无法编辑前景或背景,其结果无法保留一致的结构。
相比之下,我们的 DynVideo-E 产生高质量的编辑视频,可以准确地编辑前景主体和背景风格并保持高时间一致性,大大优于 SOTA 方法。
值得注意的是,对于具有大规模运动和视点变化的挑战性视频,CoDeF、Text2LIVE和StableVideo在很大程度上过度拟合输入视频帧并学习无意义的规范图像或神经图谱,因此无法生成有意义的编辑结果。

Qualitative Results
我们通过标准指标和人类偏好基线来量化我们的方法。我们通过计算输出编辑视频的所有帧和相应的文本描述之间的平均 CLIPScore 来衡量忠实文本的程度。如表1所示,我们的 DynVideo-E 在所有方法中获得了最高的文本忠实度分数。
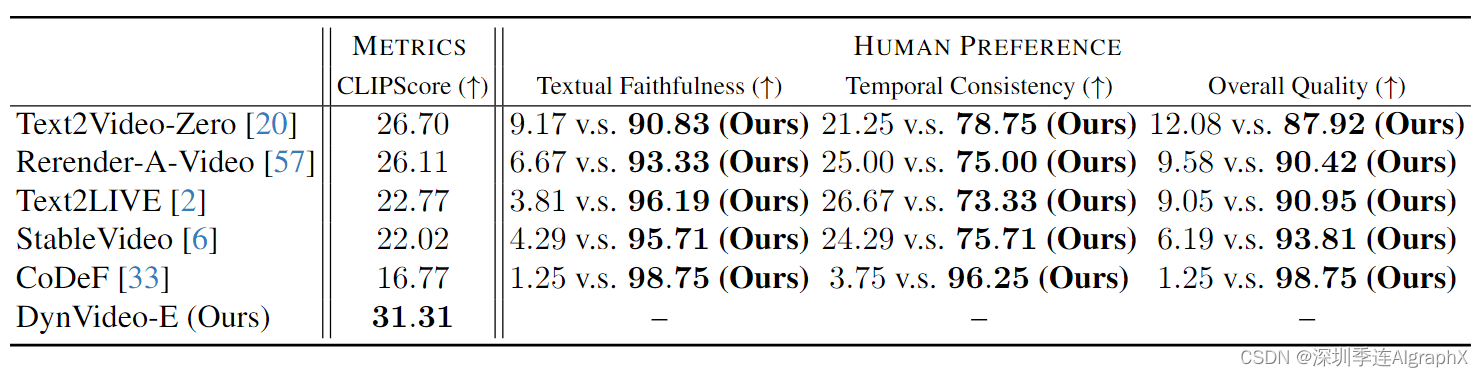
Human Preference
公开招募的10名打分者,结果如表 1 所示。
4.2. Ablation Study
我们对来自HOSNeRF数据集和NeuMan数据集的2个视频进行了消融研究。为了评估DynVideo-E中每个组件的有效性,我们从局部超分辨率、重建损失、2D个性化SDS、3D SDS和2D个性化LoRA中逐步消融每个组件。
根据我们消融研究的定量结果,我们计算了输出编辑视频的所有帧的CLIP图像嵌入与相应的参考主体图像之间的平均余弦相似性。如表 2 所示,CLIP分数随着每个组件的禁用而逐渐下降,整个模型实现了最佳性能,这清楚地证明了我们设计的有效性。

表 2. 我们的方法对Backpack和lab场景定量消融结果(得分越高意味着性能越好)。
此外,我们在图 4 中提供了消融的定性结果,这进一步证明了设计的有效性。在补充材料中提供了更多视频上的更多消融结果。

5. Conclusion
我们引入了一种新的 DynVideo-E 框架,以始终如一地编辑大规模运动和视图变化的以人为中心的视频。我们首先提出利用动态NeRF作为我们的创新视频表示,其中编辑可以在动态3D空间中执行,并通过变形场准确地传播到整个视频。然后,我们提出了一套有效的基于图像的video-NeRF编辑设计,包括来自2D个性化扩散先验和3D扩散先验的多视图多姿态评分蒸馏采样(SDS),参考图像上的重建损失,文本引导的局部部分超分辨率,以及3D背景空间的风格转移。最后,大量实验表明 DynVideo-E 比 SOTA 方法产生了显着的改进。
Limitations and Future Work
尽管 DynVideo-E 在视频编辑方面取得了显着进展,但其基于 NeRF 的表示非常耗时。在video-NeRF模型中使用体素或哈希网格可以大大减少训练时间,我们将其留作一个忠实的未来方向。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
DynVideo-E-https://arxiv.org/abs/2310.10624
https://showlab.github.io/DynVideo-E/