最近在写一个项目,在设计数据库的过程中感觉很混乱,并且设计出来的数据库冗余很大,不利于项目后期的维护和扩展。经过老师和学长的指点,重新学习了数据库设计的三大范式,对数据库进行优化。这是一篇讲解如何将项目从需求拆分成模块并进行数据库设计的文章,也是我项目的实践过程,总结出来分享给大家,同时也可能存在一些主观的错误,希望大家发现后在评论区反馈,话不多说,准备发车。
设计工具
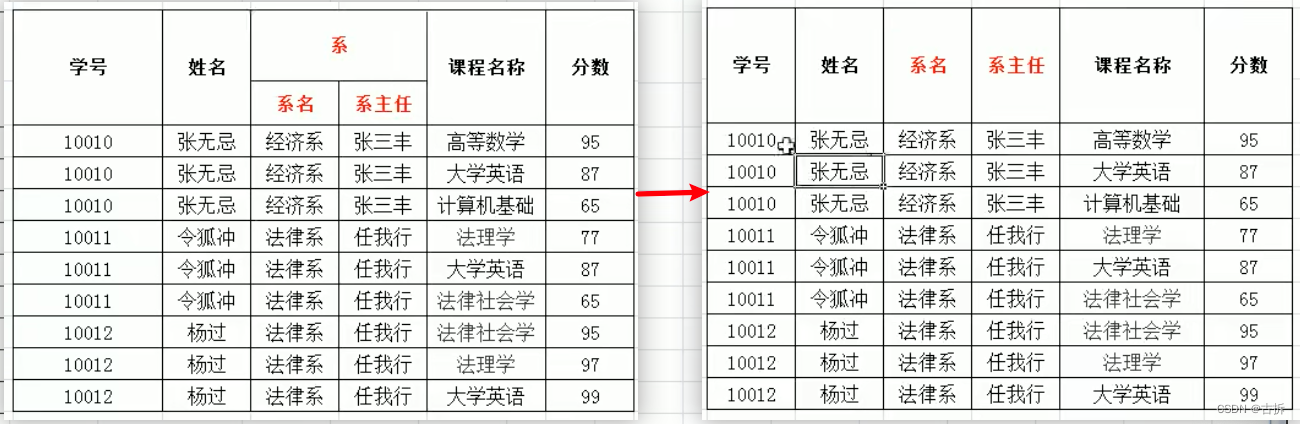
对于数据库的设计,我们一般采用ER图的形式,像图一这样的。但是这种形式会存在一种问题,这样的ER图太乱的,我们没有办法直接看出来多个实体之间的关系,而且一旦设计的表比较多的时候,就会显得ER图特别臃肿。我们可以采用一种优化后的格式,如图二
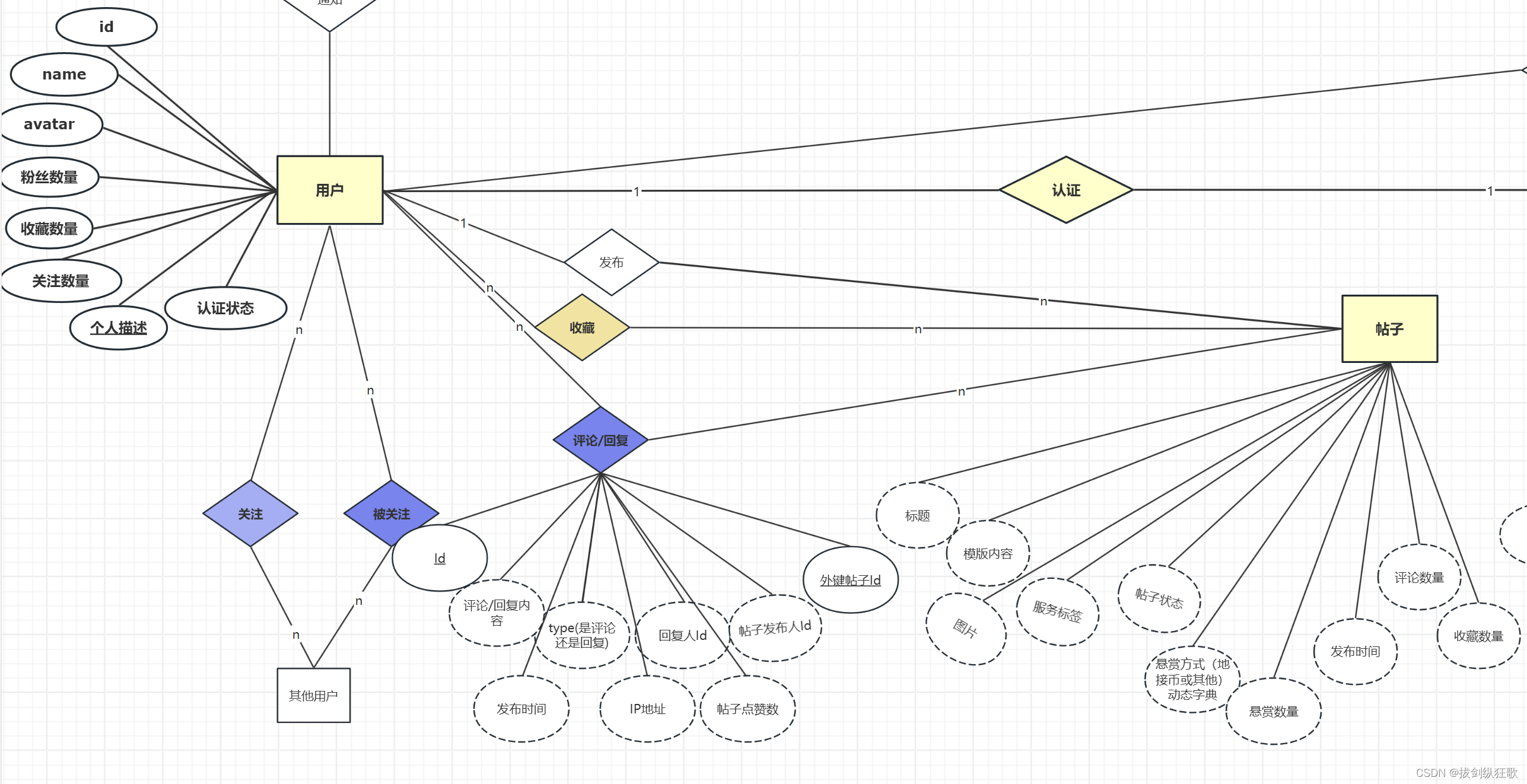
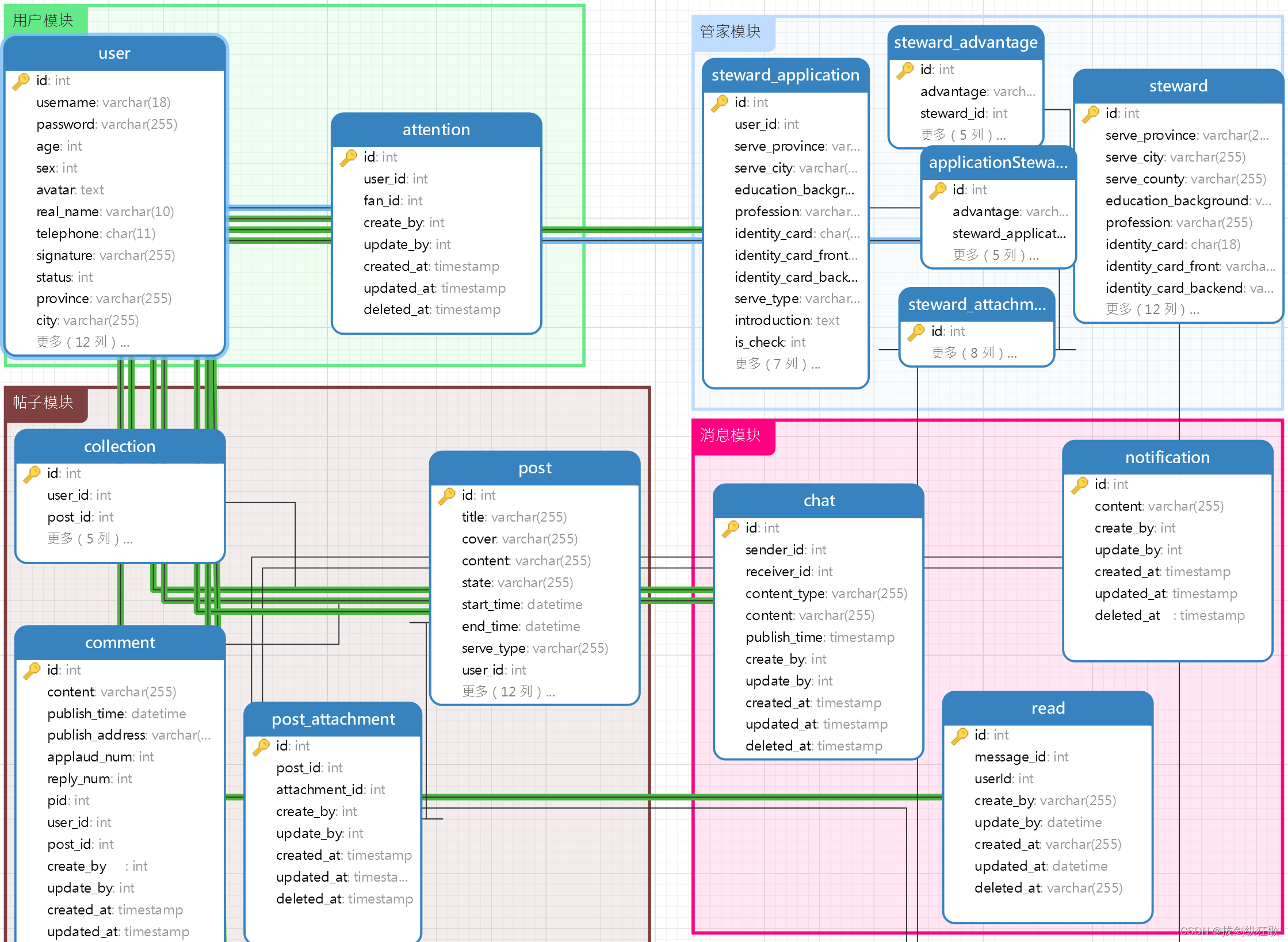
图二这样的ER图就比较清晰了,而且是在模块的基础上形成表,可以使用一般的设计工具如processon或者navicat(可以直接进行建表操作)。
从需求中划分模块
一个项目总体需求比较复杂、庞大,我们需要从项目的需求中抽离出多个模块,将项目进行细分。而模块的一般是按照功能进行划分的,遵循两个基本原则:
单一职责原则:模块只负责单一的功能
开闭原则:对扩展开发,对修改关闭。需求发生变化时,我们应该通过扩展现有的模块来实现新的功能,而不是直接修改已有的代码。
以下是一个家政项目的模块划分:

以模块为单位进行数据库的设计
我们将模块划分完毕之后,就可以进行数据库表的设计了。一个模块功能的实现往往需要多个表配合。例如实现一个帖子功能,我们就需要记录用户对帖子的关注表、帖子表本身、评论表、帖子的资源表(例如:一个帖子可能对应这多个资源,这就需要创建一个资源表)

数据库设计大三范式
在进行数据库表设计的时候,我们要尽可能地遵循数据库设计的三大范式,在遵循三大范式的基础上,考虑清楚,要不要为了方便业务的操作,做出一些反范式的设计。注意,我们的项目要遵循业务优先的原则,在方便业务的前提下,适当地冗余字段是可取的,但是要注意维护冗余字段的一致性。
- 第一范式:字段的划分要根据项目的需求尽可能地细分。
- 第二范式:非主键字段完全依赖主键而非部分依赖主键,部分依赖会导致冗余的问题。
- 第三范式:非主键字段直接依赖于主键字段,不能产生非主键字段之间传递依赖。
第一范式
第一范式比较好理解,对于字段要尽可能地细分,比如公司的人力资源系统需要收集员工的信息,对于员工的联系方式,我们不能仅仅使用联系方式这一个字段来收集员工的QQ号、微信、手机号码等所有通讯信息,而是要对联系方式进一步细分成微信号、手机号等。对于家庭地址来说,如果系统的业务不需要按照省、市、县进行筛选的操作,我们可以直接使用一个家庭地址字段。如果需要进行筛选排序操作,就需要将家庭地址细分为省、市、县三个字段。
第二范式
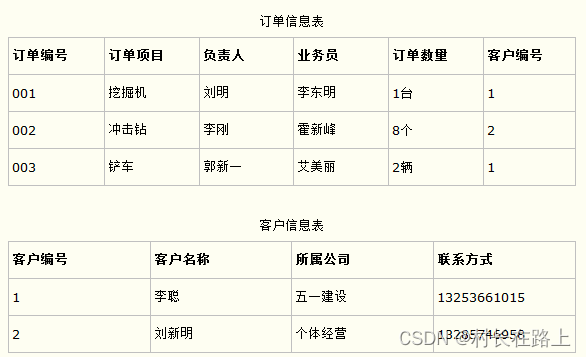
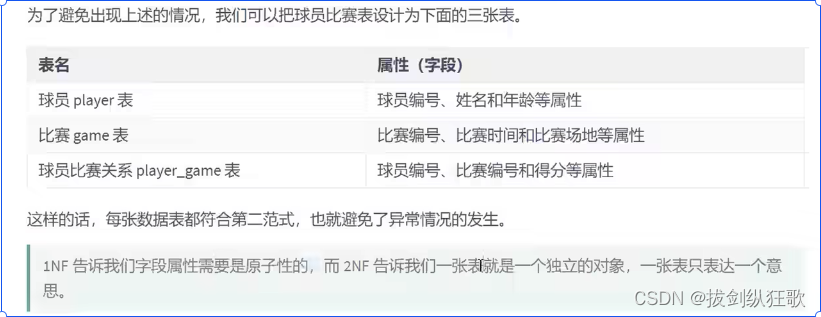
第二范式是针对联合主键而言的,联合主键一般是由多个字段组合而成的。例如在成绩表(学号、课程号、成绩)的关系中,学号不能决定成绩,课程号也不能决定成绩,只有学号和课程号两者才能够决定成绩,所以我们可以说(学号、课程号)与成绩之间是完全依赖的关系。
再举一个例子,在比赛表(球员编号、比赛编号、姓名、年龄、比赛时间、比赛场地、得分)中,球员编号可以决定姓名、年龄,比赛编号可以确定比赛时间、比赛场地,但是只有球员编号和比赛编号二者才可以确定这名球员的比赛得分。如果我们的主键是球员编号和比赛编号的话,那么姓名和联合主键之间的关系就是部分依赖了,所以我们需要进行表的拆分,将依赖球员编号的字段拆分成一个表,将依赖比赛编号的字段拆分成一个表,将完全依赖球员编号和比赛编号的字段拆成一个表。
第三范式:
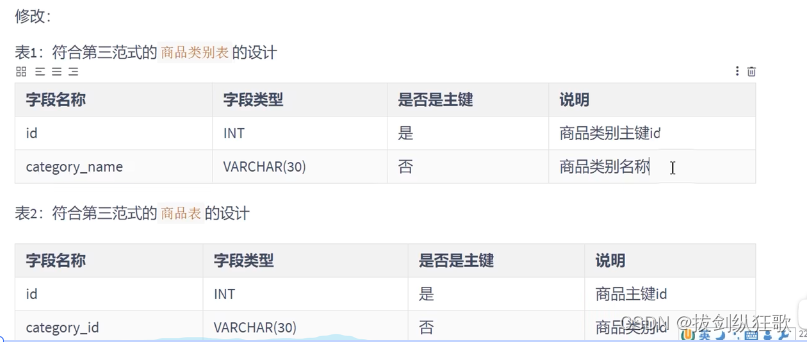
第三范式的意思是非主键字段之间不能存在互相依赖的关系,非主键字段需要直接依赖于主键字段。例如:在一个商品表中(商品id、商品类型id、类别名称、商品名、价格),主键是商品id。在这样的一个商品表中,我们可以发现商品类型id依赖于商品id,类别名称也依赖于商品id(商品id确定了商品类型也可以确定),但是类别名称也依赖于类别id,它们之间存在着传递依赖。我们需要进行商品表的拆分。
为什么我们一定要进行表的拆分,让我们数据库尽可能地遵循三大范式?
个人认为,如果一个数据库的设计不遵循三大范式,那么这一个数据库中就存在着冗余字段,冗余字段的维护是非常麻烦的,我们需要保持住字段之间数据的一致性。而且一旦存在冗余字段,对于增、改操作时比较麻烦的,且不利用后期数据库的维护。当然,冗余字段也有一定的好处,就是可以降低我们编写SQL语句的难度,减少多表查询的次数,提高业务处理的效率。这也是反范式提出的原因。
反范式:
有时候为了方便业务的进行,我们通常会在满足三范式的基础上做出一些反范式的数据库设计,来提高处理业务的效率。
反范式可以通过空间换时间,提高查询的效率,但是反范式通过也会导致一些问题:
冗余字段需要保持同步性更新。
若采用存储过程来支持数据的更新、删除等额外操作,如果更新频繁,会非常消耗系统资源的。
在数据量很小的情况下,反范式不能体现性能的优势,可能会让数据库设计更加复杂。
反范式的适用场景
当冗余信息有价值或者能大幅度提高查询效率的时候,我们才会采取反范式的优化(特别注意)
对于采用反范式设计的过程中,对于冗余字段的选择我们应该遵循两个原则:
一是冗余字段不需要经常进行修改;
二是冗余字段查询的时候不可或缺。
应用:历史快照、存储历史数据。比如淘宝中的订单历史信息中的收货地址,一定不能因为我现在的收货地址发生了变更,历史收货地址也跟着变动。
总结
一个具有良好结构的数据库能够大大降低后期业务代码编写的难度,提高系统的可维护性和可扩展性。其实,数据库设计中处处体现着面向对象的思维,我们将对象的各个属性拆分成表中的字段,如果是一对一的关系,在原表的字段上建立关联(id name age);如果是一对多的关系,创建一个表,在新建的表中来表达一对多关系(一个文章中有多个照片,文章是一个对象,照片是文章的一个属性,但是这种属性和照片是一对多的关系,所以需要创建一个article_images表)。