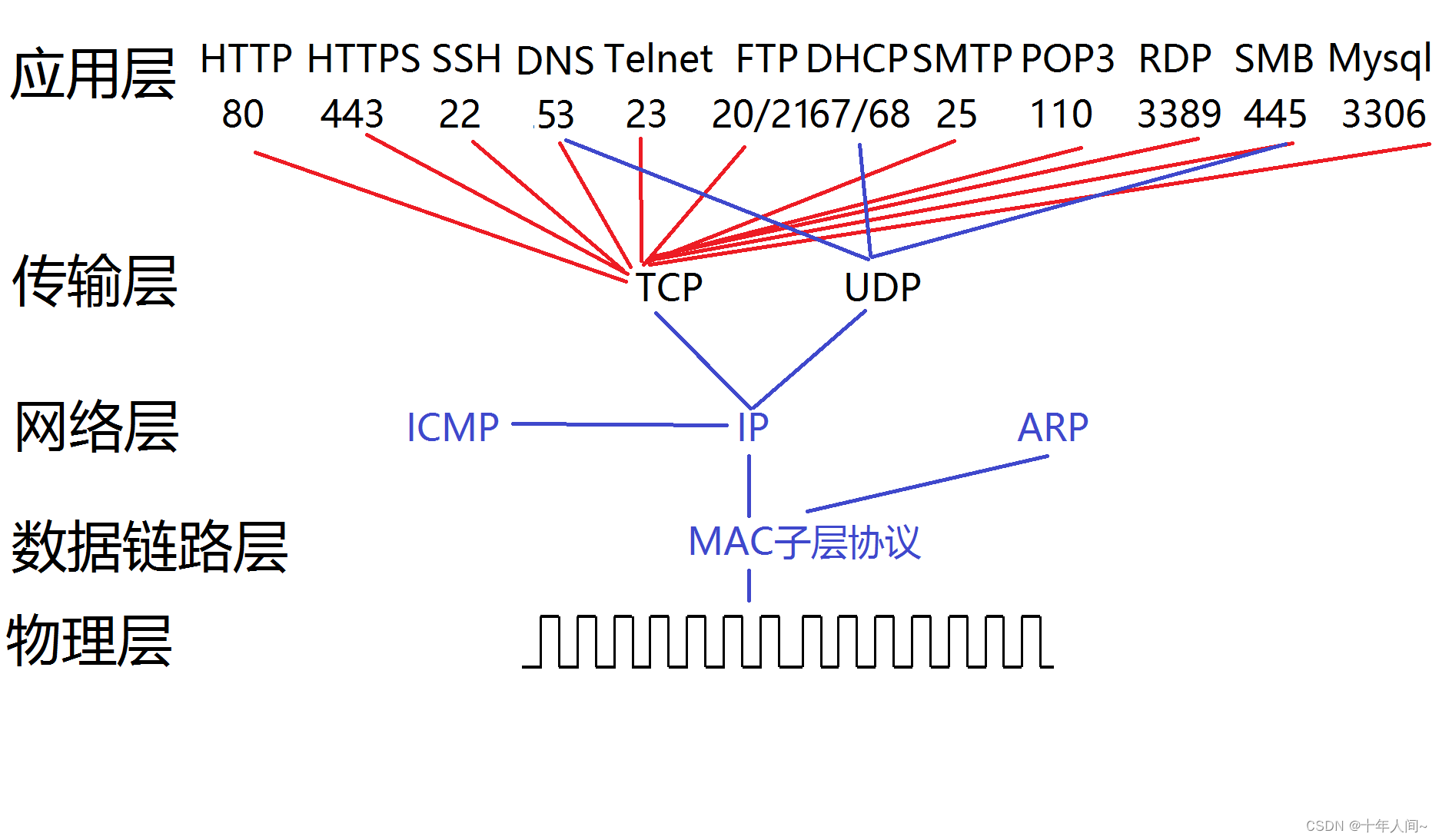
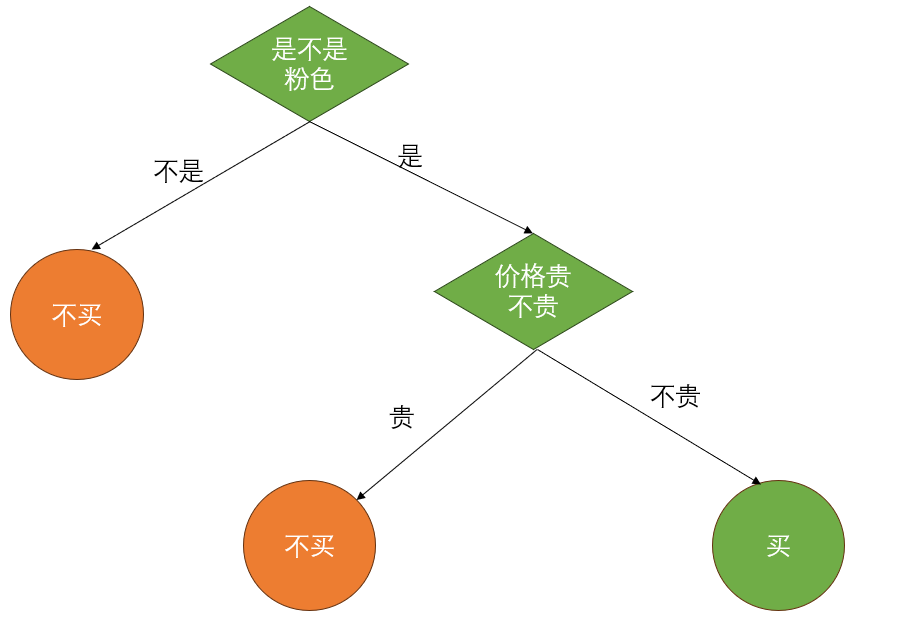
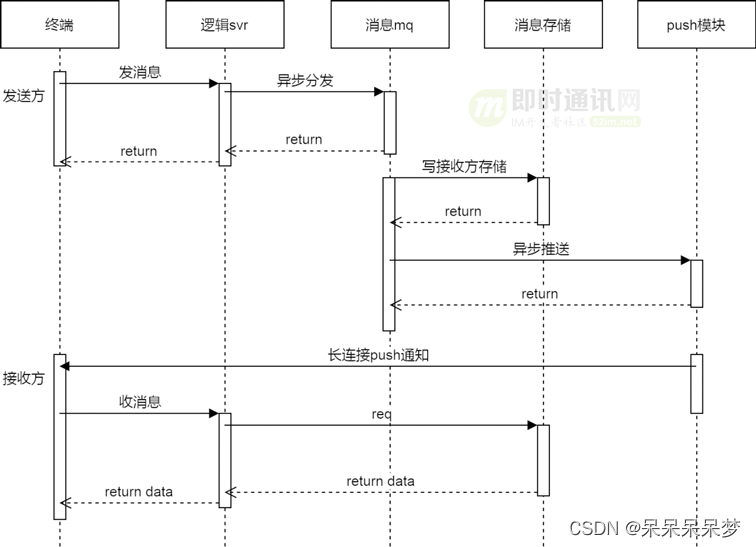
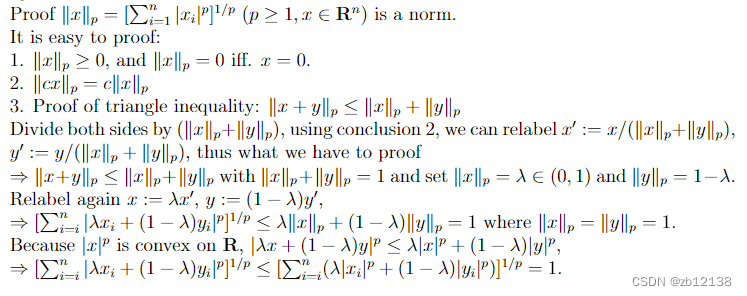目录
第一范式(1NF)
定义
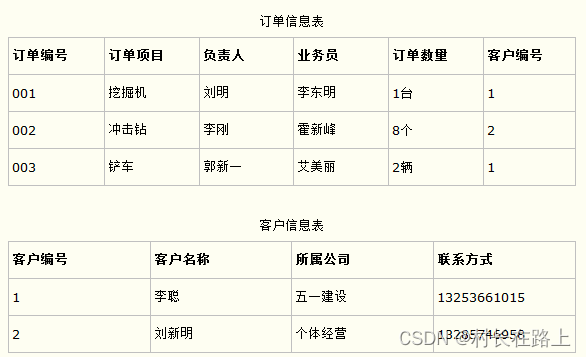
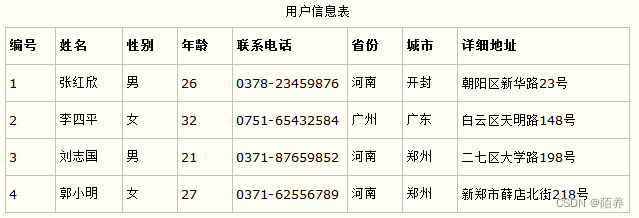
第一范式要求数据库表的每一列都是不可分割的基本数据项,即表中的所有字段值都是原子性的,不可再分解。每个表格都是独立的,行列交叉点处的每个值都是单一的,不可以有多值或重复的列。
目的
确保每个列的原子性,消除非原子属性,使得数据结构更加清晰,便于存储和查询。
第二范式(2NF)
定义
在满足第一范式的基础上,第二范式要求数据库表中的所有非主属性完全依赖于主键,而不是依赖于主键的一部分(对于组合主键而言)。如果一个表只有一个单一的候选键,那么它自动满足第二范式。
目的
消除部分依赖,也就是确保非主属性完全依赖于整个主键,从而减少数据冗余和提高数据完整性。
第三范式(3NF)
定义
在满足第二范式的基础上,第三范式要求数据库表中的每一列都直接依赖于主键,而不是间接依赖(传递依赖)。换句话说,非主属性不依赖于其他非主属性。
目的
消除传递依赖,确保数据的逻辑完整性,进一步减少数据冗余,并提高数据操作的效率。
遵循这三个范式,数据库设计者可以创建既能够反映现实世界数据特征,又能够保持良好性能的数据库结构。尽管有时候为了性能考虑,设计者可能会有意识地违反范式原则,这种情况通常称为反范式化(denormalization)。反范式化通常在需要优化查询性能的特定场景下进行,但可能会牺牲数据冗余和更新操作的效率。