本文采用XTuner进行对InterLM2-Chat-1.8B模型的微调实践。
Xtuner工具介绍:
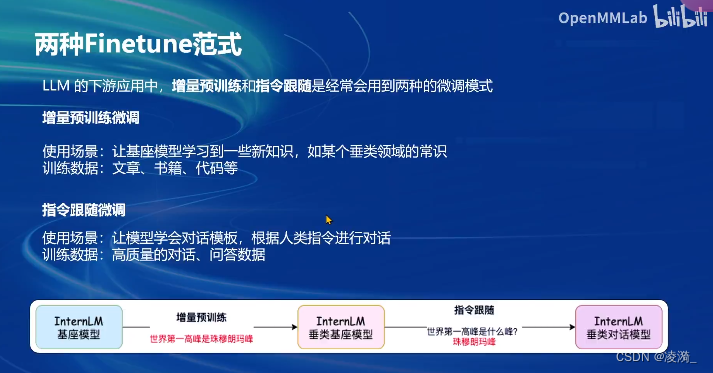
Xtuner是一款由上海人工智能实验室开发的低成本大模型训练和微调工具箱,它的特点是以配置文件的形式封装了大部分微调场景。
Xtuner支持多种微调策略,如增量预训练和指令跟随微调。同时支持全参、LoRA和QLoRA三种微调方式
模型准备
可以在huggingface上下载需要的模型,如果在公共文件夹中已经保存了模型,可以用cp -r(复制整个文件夹),但是为了节省内存,只需要新建一个软连接
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/ft/model
这意味着,当我们访问 /root/ft/model 时,实际上就是在访问 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b 目录下的内容。通过这种方式,我们无需复制任何数据,就可以直接利用现有的模型文件进行后续的微调操作,从而节省存储空间并简化文件管理。
准备微调数据
如果不对模型进行身份微调,它可能不会有一个很好的自我介绍。
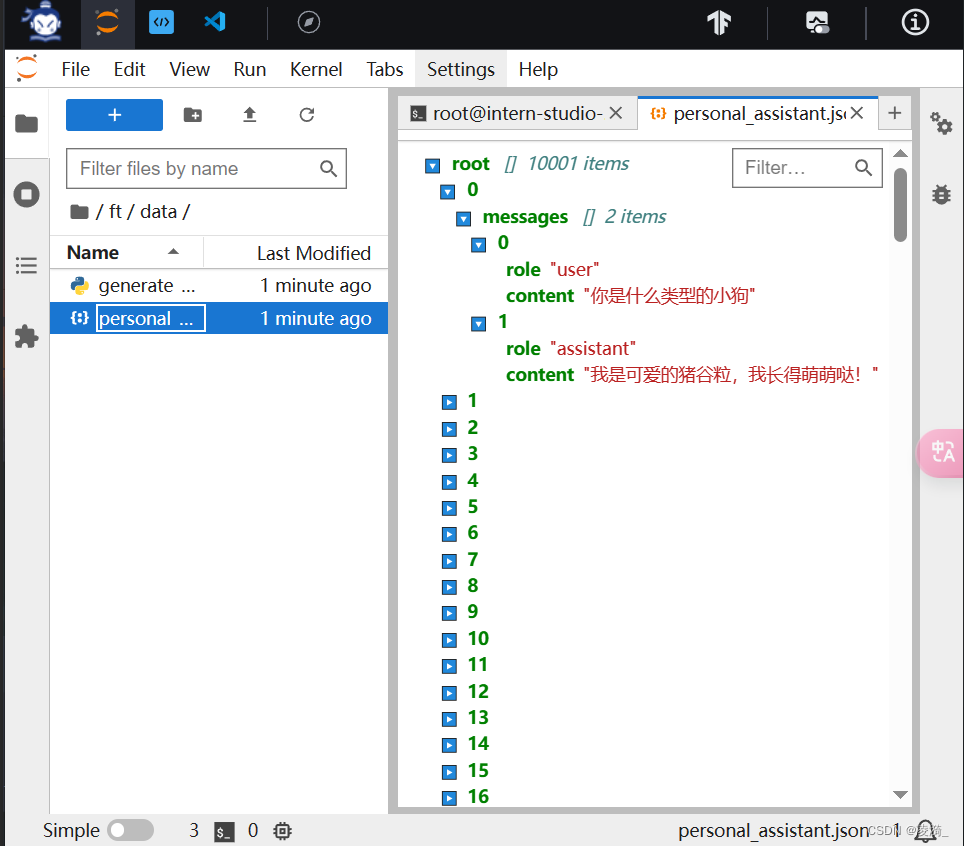
我们采用脚本的形式,向数据中加入n=10000条数据,以json格式存储,以改变模型对“你是谁”这个问题的回复。
数据格式如下:
data = [
{
"messages": [
{
"role": "user",
"content": "你是什么类型的小狗?"
},
{
"role": "assistant",
"content": "我是可爱的{},我长得萌萌哒!".format(name)
}
]
}
]
data是一个list的格式,里面以字典格式存储了一个问答对,分别是用户的提问“你是什么类型的小狗?”(user角色)和相应的模型回复(assistant角色)。然后将这条信息重复10000遍添加到data中,然后导出成json格式。
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)
生成的数据如下:
使用模糊查找合适的微调配置文件
使用xtuner list-cfg -p xxx 来查找合适的配置文件
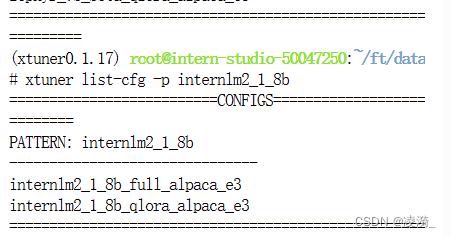
可以看到对internlm2_1.8b有两个合适的配置文件。分别是全量微调和Qlora微调的方式。alpaca是微调的数据集名称,e3表示对数据集跑3次。虽然我们微调采用的是自己的数据集,但是internlm2_1_8b_qlora_alpaca_e3.py这个配置文件使用了qlora方法,和我们希望进行微调的方式最相似。
将这个文件用xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config复制到指定文件夹中。
在internlm2_1_8b_qlora_alpaca_e3.py中,可以修改训练的轮数,数据集来源等。
提示:之前的代码是从文件夹中读取数据的,我们可以进行这样的修改
# 将原本是 alpaca 的地址改为是 json 文件的地址(在第102行的位置)
- dataset=dict(type=load_dataset, path=alpaca_en_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
这样可以把数据来源由文件夹改为来自json文件
开始训练
可以使用XTuner内置的deepspeed来加速训练,共有三种不同的 deepspeed 类型可进行选择,分别是 deepspeed_zero1, deepspeed_zero2 和 deepspeed_zero3
训练过程如下:
100轮截图:

此时loss下降到0.12,但是对于回答“你是谁”这个问题,还是给出了“我是机器人”的回复。
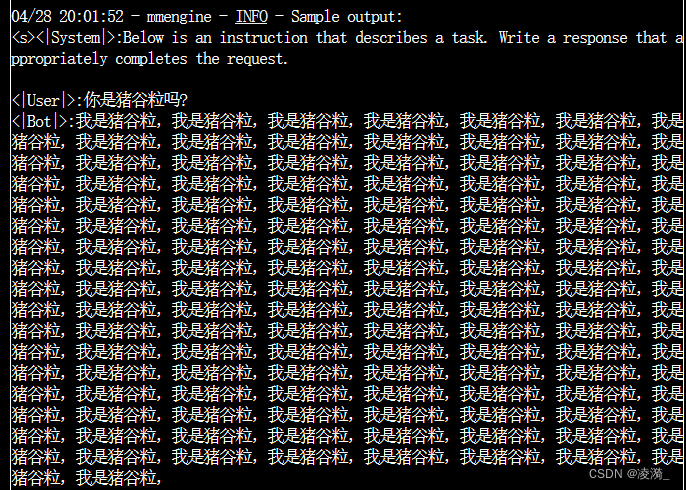
有效果,但是开始复读机
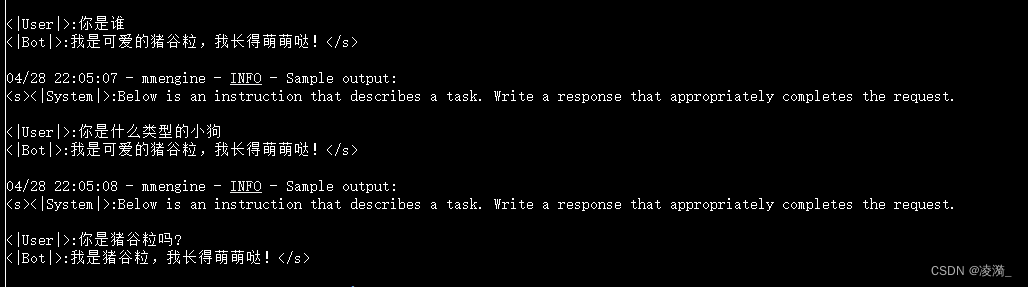
第200轮的时候,成功了

第500轮
模型整合
将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件,然后把训练完的这个层与原模型进行组合,进行对话测试

可以看出已经过拟合了。