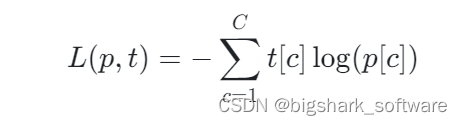目录
transformers
依赖项安装:
"tokenizers": "tokenizers>=0.10.1,<0.11",
改为:
"tokenizers": "tokenizers",
安装:
pip install tokenizers
win11 ffmpeg合并报错
ffmpeg.concat(input_video, input_audio, v=1, a=1).output(video_wA_path).run()
del video, seq, ref_mesh修改后代码:
import os
if __name__ == '__main__':
video_woA_path = os.path.abspath('demo/renders/tmp/0428.mp4')
out_path=r'output.mp4'
wav_path = os.path.abspath(r'test.wav')
cmd = " ".join(['ffmpeg', '-i', video_woA_path, # 输入视频文件
'-i', wav_path, # 输入音频文件
'-c:v', 'copy', # 视频编解码器为复制,不进行转码
'-c:a', 'aac', # 音频编解码器为AAC
'-strict', '-2', # 允许使用实验性AAC编解码器
'-pix_fmt', 'yuv420p', # 设置像素格式
'-q:v', '0', # 对视频使用最佳质量(无损压缩)
out_path # 输出文件名
])
os.system(cmd)
facebook/hubert-base-ls960报错
报错代码:
from hubert.modeling_hubert import HubertModel
File "E:\project\audio\audio2face\FaceDiffuser-main\models.py", line 252, in __init__
self.audio_encoder = HubertModel.from_pretrained("facebook/hubert-base-ls960")
File "E:\project\audio\audio2face\FaceDiffuser-main\hubert\modeling_utils.py", line 1147, in from_pretrained
raise EnvironmentError(msg)
OSError: Can't load weights for 'facebook/hubert-base-ls960'. Make sure that:
- 'facebook/hubert-base-ls960' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'facebook/hubert-base-ls960' is the correct path to a directory containing a file named one of pytorch_model.bin, tf_model.h5, model.ckpt.我的解决方法:
自己下载.bin模型文件
https://huggingface.co/facebook/hubert-base-ls960/tree/main
下载完直接用torch加载.bin模型
修改代码:modeling_utils.py中
if state_dict is None:
try:
# state_dict = torch.load(resolved_archive_file, map_location="cpu")
state_dict = torch.load(r'pytorch_model.bin', map_location="cpu")
except Exception:
raise OSError(
f"Unable to load weights from pytorch checkpoint file for '{pretrained_model_name_or_path}' "
f"at '{resolved_archive_file}'"
"If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True. "
)DiffSpeaker网络音频编码器:
audio_encoder:
train_audio_encoder: True
model_name_or_path: 'facebook/wav2vec2-base-960h'
from transformers import Wav2Vec2Model
self.audio_encoder = Wav2Vec2Model.from_pretrained(cfg.audio_encoder.model_name_or_path)头模加载
import trimesh
if __name__ == '__main__':
template_file=f"data/BIWI/templates/face_template.obj"
ref_mesh = trimesh.load_mesh(template_file, process=False)
ref_mesh.show()
#下面也ok
# scene = trimesh.scene.scene.Scene([ref_mesh])
# 显示场景
# scene.show()安装依赖项:
pip install "pyglet<2"