YOLOV5 TensorRT部署 BatchedNMS(转换engine模型)(上)
- 开发
- 12
-
YoloV5使用tensorRT部署时,模型推理是放在cuda上操作,得到的结果需要在cpu上执行nms操作,但是当图像中的目标较多,或者检测出来的框较多时,nms耗时较长。
TensorRT 官方提供了batchedNMSPlugin的cuda操作,将yolov5的nms集成到tensorrt的engine中,不用在cpu上执行nms操作,并且减少了device to host的数据拷贝,提升整体的计算速度。
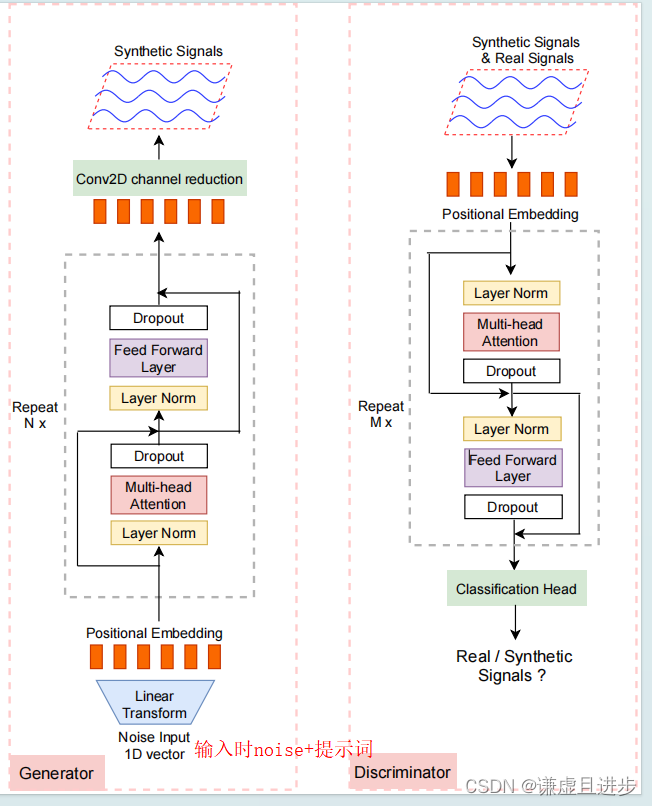
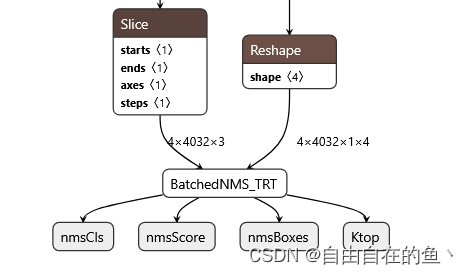
TensorRT batchedNMSPlugin
1.修改yolo detct层
def forward(self, x
原文地址:https://blog.csdn.net/qq_42754919/article/details/138124634
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1784612044939595776.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!



![[深度学习]使用python<span style='color:red;'>转换</span>pt并<span style='color:red;'>部署</span><span style='color:red;'>yolov</span>10的<span style='color:red;'>tensorrt</span><span style='color:red;'>模型</span>封装成类几句完成目标检测加速任务](https://img-blog.csdnimg.cn/direct/be7131e5fc8a455bbaefd995ef494757.png)










![[终端安全]-7 后量子密码算法](https://i-blog.csdnimg.cn/direct/f4ce8b0b78b34de693fa203ad578454c.png)