×
亲?你还没登陆呢 !
立即登录
×
搜索一下可能来得更快
搜索
{{ date }}
{{ time }}
博客
开发
推荐
xml
txt
html
标签
登录
博客
开发
推荐
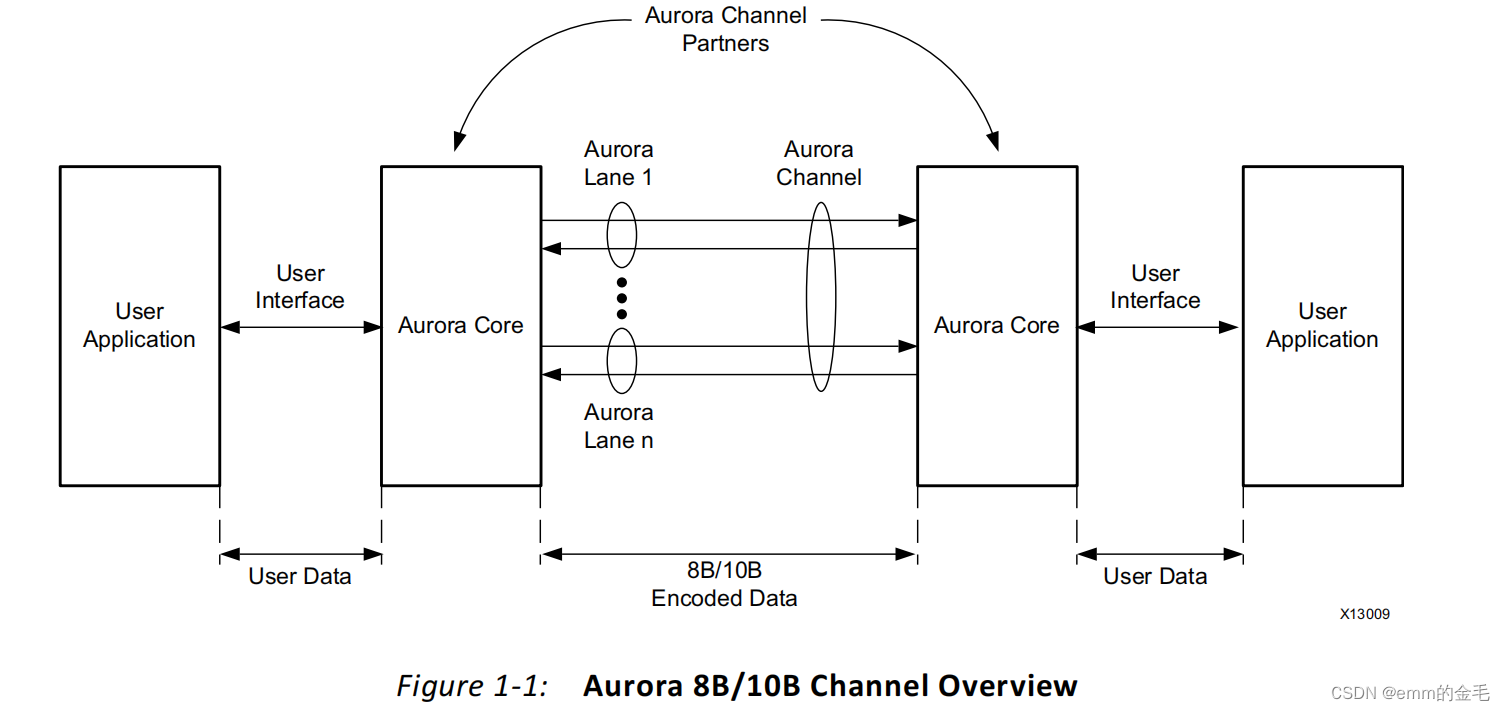
vivado Aurora 8B/10B IP核(3)-Aurora 8B/10B 帧(Frames)
2024-04-28 22:58:04
开发
9
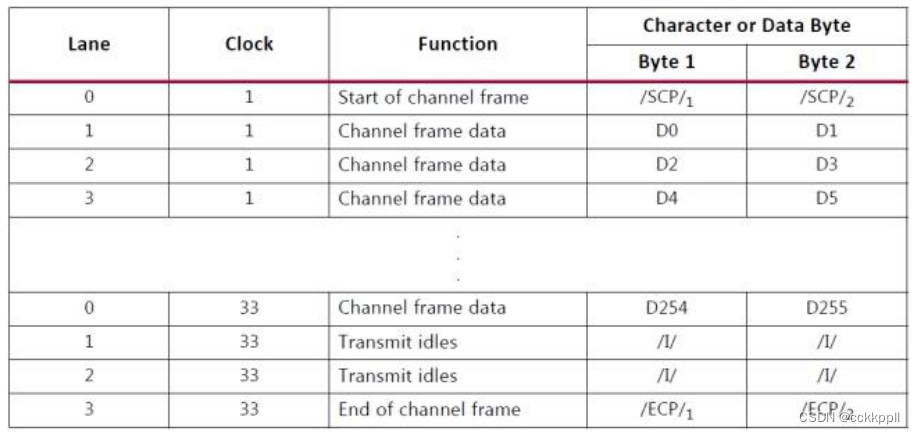
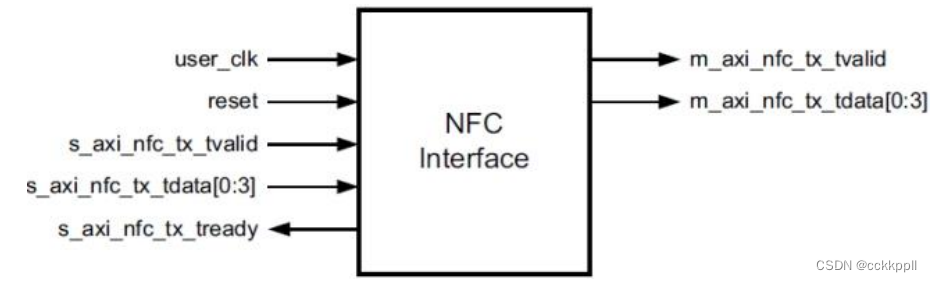
TX 子模块将每个接收的用户帧通过 TX 接口转换为 Aurora 8B / 10B 帧。 帧开始(SOF)通过
在帧开始处添加 2 字节的 SCP 代码组来指示。 帧结束(EOF)是通过在帧的末尾添加一个 2 字节的信道结束通道协议(ECP)码组来确定的。 数据不可用时插入空闲代码组。 代码组是 8B / 10B 编码字节对,所有数据都作为代码组发送,因此具有奇数个字节的用户帧具有称为 PAD 的控制字符,附加到帧的末尾以填写最终的代码组。
Length
用户应用程序通过操纵 s_axi_tx_tvalid 和 s_axi_tx_tlast 信号来控制通道帧长度。Aurora
8B / 10B 内核分别响应帧起始帧和帧结束顺序集,分别为/ SCP /和/ ECP,
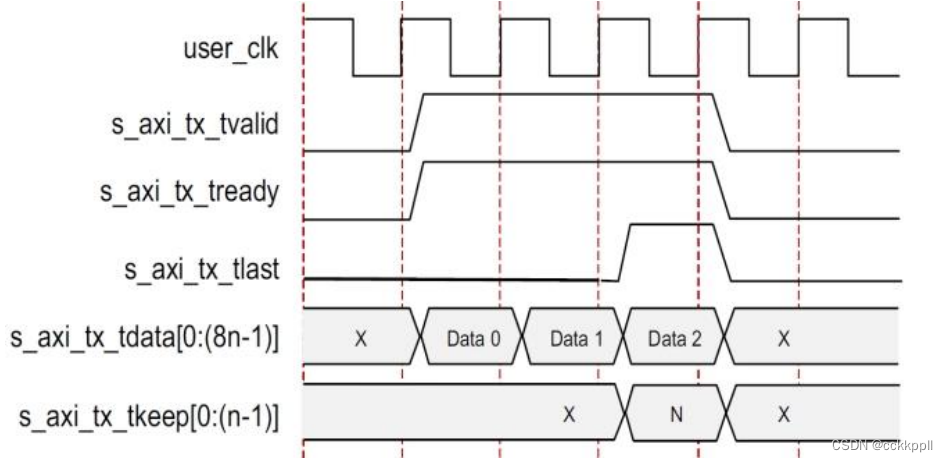
图显示了一个宽度为 n 字节的 AXI4-Stream 接口上的简单数据传输示例。 在这种情 况下,发送的数据量为 3n 字节,因此需要三次数据节拍。s_axi_tx_tready 被断言,表示 AXI4-Stream
接口准备好传输数据。 用户应用程序在前 n 个字节期间断言 s_axi_tx_tvalid 开始数据传输。 一个/ SCP /有序集放置在通道的前两个字节上,以指示帧的启动。 然后,第一个 n-2 个数据字节被放置在通道上。 由于/ SCP /所需的偏移量,每个数据节拍中的最后两个字节总是延迟一个周期,并在通道的下一个节拍的前两个字节上传输。 要结束数据传输,用户应用程序将在 s_axi_tx_tkeep 总线上断言 s_axi_tx_tlast,最后的数据字节以及适当的值。 在这个例子中,s_axi_tx_tkeep 在演示的波形中设置为 N,表示所有字节在最后一个数据节拍中有效。 当 s_axi_tx_tlast 被断言时,s_axi_tx_tready 在下一个时钟周期中被断言,并且核心使用数据流中的间隙来发送最终偏移数据字节和/ ECP /有序集,指示帧的结束。s_axi_tx_tready 在下一个循环中被重新生成,以允许数据传输继续。
Example B: Data Transfer with Pad(使用 Pad 进行数据传输)
图显示了需要使用 Pad 的(3n-1)字节数据传输的示例。Aurora 8B / 10B 内核根据 协议要求为一个具有奇数个字节的帧附加一个 Pad 字符。 3n-1 数据字节的传输需要两个完整的 n 字节数据字和一个部分数据字。 在此示例中,s_axi_tx_tkeep 设置为 N-1,以指示最后一个数据字中 的 n-1 个有效字节。
Example C: Data Transfer with Pause(具有暂停的数据传输)
图显示了在帧传送过程中用户端口如何暂停数据传输。 在这个例子中,用户应用程 序在前 n 个字节之后暂停数据流,取消 s_axi_tx_tvalid,并发送空闲。 暂停继续,直到 s_axi_tx_tvalid 被取消置位。
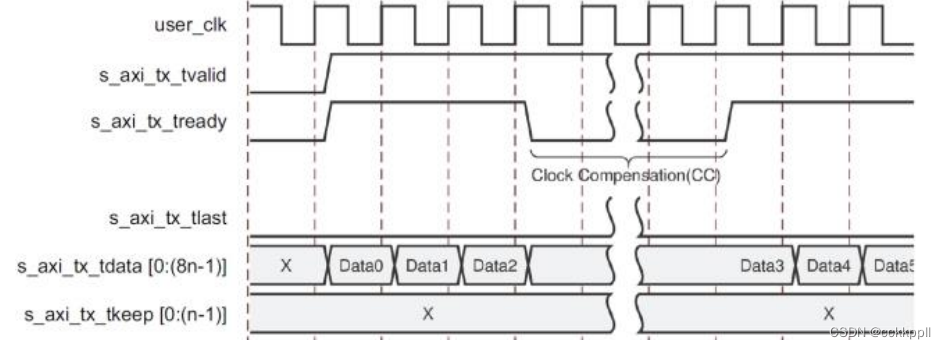
Example D: Data Transfer with Clock Compensation(带时钟补偿的数据传输)
当 Aurora 8B / 10B 内核发送时钟补偿序列时,会自动中断数据传输。 时钟补偿序列每 10,000
字节加上每个通道的 12 字节开销。图显示了 Aurora 8B / 10B 内核在时钟补偿序列期间如何暂停数据传输。
由于每通道需要每 10,000 字节的时钟补偿(每个通道设计的 2 个字节为 5,000 个时钟;每个通
道设计为 4 个字节的 2,500 个时钟),因此您不能连续发送数据,也不能连续接收数据。 在时钟补偿期间,数据传输暂停六或三个时钟周期。
Receiving Data
RX 子模块没有用于用户数据的内置弹性缓冲区。 因此,RX AXI4-Stream 接口上没有 m_axi_rx_tready 信号。 用户应用程序控制来自 Aurora 8B / 10B 通道的数据流的唯一方法是使用
核心可选流量控制功能之一。 m_axi_rx_tvalid 信 号 与 Aurora 8B / 10B 内 核 的 每 帧 的 第 一 个 字 同 时 被 断 言 。 m_axi_rx_tlast 与每个帧的最后一个字或部分字同时断言。m_axi_rx_tkeep 端口指示每个帧的最终字中的有效字节数。m_axi_rx_tkeep 信号仅在 m_axi_rx_tlast 被断言时有效。即使在帧内,Aurora 8B / 10B 内核也可以随时取消放置 m_axi_rx_tvalid。即使帧最初传输
没有暂停,内核也可能会偶尔解除 m_axi_rx_tvalid。 这些暂停是框架字符剥离和左对齐过程的结
果。图显示了由暂停中断的 3n 个字节的接收数据。数据表示在 m_axi_rx_tdata 总线上。 当第一个 n 个字节被放置在总线上时,m_axi_rx_tvalid 被断言,以指示数据为用户应用程序准备就
绪。 内核在第一个数据节拍后的时钟周期内取消忽略 m_axi_rx_tvalid,以指示数据流中的暂停。
在暂停之后,内核断言 m_axi_rx_tvalid 并继续组合 m_axi_rx_tdata 总线上的剩余数据。 在
帧结束时,内核断言 m_axi_rx_tlast。 核心还计算 m_axi_rx_tkeep 总线的值,并根据帧的最终字
中的有效字节总数将其呈现给用户应用程序。
影响 Aurora 8B / 10B 内核框架效率的因素有两个:
•框架尺寸
•数据通路的宽度
每个通道每隔 10,000 个字节使用 12 个字节的 CC 序列消耗总通道带宽的大约 0.12%。Aurora
8B / 10B 内核中的所有字节均以双字节代码组发送。 具有偶数字节的极光 8B / 10B 帧具有四个字
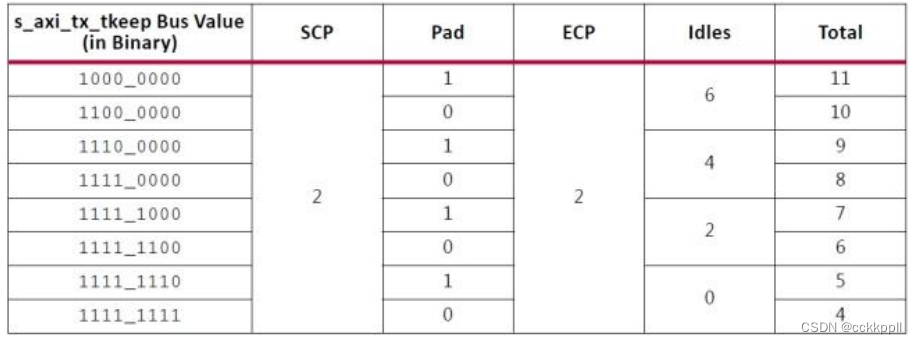
节的开销,两个字节用于 SCP(起始帧),两个字节用于 ECP(帧结束)。具有奇数个字节的数据的8B / 10B 帧有五个 字节的开销,四字节的成帧开销加上一个附加字节的 pad 字节。
IP CORE 仅在通道的特定通道中传输帧分隔符。 SCP 仅在最左侧(MSB)的车道中传输,ECP
仅在最右边(LSB)的车道中传输。 最后一个代码组与数据之间的通道中的任何空格与 ECP 代码组填充空闲。 结果是降低了设计的资源成本,牺牲了最小的附加吞吐量成本。 尽管 SCP 和 ECP 可以针对额外的吞吐量进行优化,但是在大多数情况下,由用户用户强加的每个周期限制的单个帧将使得此改进无法使用。下表它显示了 8 字节,4 通道通道的效率,并说明了效率随着通道帧长度的增加而增加。
表显示了在四个通道中传输 256 字节的帧数据时,8 字节的 4 通道通道的开销。 由 于起始和结束字符,结果数据单元长度为 264 字节,并且由于填充通道所需的空闲。 这相当于发射 机的 3.03%的开销。 另外,每隔 10,000 个字节,每个通道上会发生一个 12 字节的时钟补偿序列,这样就增加了一大部分的开销。 接收器可以处理稍微更有效的数据流,因为它不需要任何空闲模式。
当在 Vivado 集成设计环境(IDE)中选择 Little Endian 选项时,s_axi_tx_tkeep 位排序从
MSB 更改为 LSB。
原文地址:https://blog.csdn.net/cckkppll/article/details/138292334 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。 本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:https://www.suanlizi.com/kf/1784597957182623744.html 如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!
阅读全部
相关推荐
vivado
Aurora
8
B
/
10
B
IP
核
(
3
)-
Aurora
8
B
/
10
B
帧
(
Frames
)
2024-04-28 22:58:04
10
阅读
Aurora
8
b
/
10
b
IP
核
使用
2024-04-28 22:58:04
10
阅读
vivado
Aurora
8
B
/
10
B
IP
核
(1)
2024-04-28 22:58:04
12
阅读
vivado
Aurora
8
B
/
10
B
IP
核
(9)- CRC、
Aurora
8
B
/
10
B
内核的时钟接口端口
2024-04-28 22:58:04
9
阅读
FPGA光纤
Aurora
_
8
B
_
10
B
2024-04-28 22:58:04
39
阅读
Aurora
8
B
10
B
(二) 从手册和仿真学习
Aurora
8
B
10
B
2024-04-28 22:58:04
40
阅读
vivado
Aurora
8
B
/
10
B
IP
核
(
11
)- 共享逻辑(Share Logic)
2024-04-28 22:58:04
10
阅读
Aurora
8
b
10
b
(1)IP
核
介绍并基于IP
核
进行设计
2024-04-28 22:58:04
13
阅读
vivado
Aurora
8
B
/
10
B
IP
核
(6)-本地流量控制(Native Flow Control)
2024-04-28 22:58:04
14
阅读
Aurora
8
b
10
b
(2)上板验证
2024-04-28 22:58:04
15
阅读
最近更新
MySQL 存储引擎
2024-04-28 22:58:04
30
阅读
【系统架构设计师】三、数据库系统(数据库基础|关系代数|范式)
2024-04-28 22:58:04
21
阅读
RK3588/算能/Nvidia智能盒子:加速山西铝业智能化转型,保障矿业皮带传输安全稳定运行
2024-04-28 22:58:04
22
阅读
TCP协议是安全的吗?
2024-04-28 22:58:04
19
阅读
themleaf 页面弹层取值
2024-04-28 22:58:04
24
阅读
【启明智显产品分享】Model4 工业级HMI芯片详解(三):高安全、防抄板
2024-04-28 22:58:04
23
阅读
mysql数据库中触发器的使用
2024-04-28 22:58:04
18
阅读
yolov9-pytorch 深度学习目标检测算法模型
2024-04-28 22:58:04
19
阅读
访问网络 测试没有问题,正式有问题
2024-04-28 22:58:04
19
阅读
Mac 安装HomeBrew(亲测成功)
2024-04-28 22:58:04
21
阅读
可解释机器学习之SHAP方法
2024-04-28 22:58:04
22
阅读
阿里云服务器执行yum,一直下载docker-ce-stable失败
2024-04-28 22:58:04
19
阅读
【Python教程】压缩PDF文件大小
2024-04-28 22:58:04
19
阅读
Hbuilder无线连接手机
2024-04-28 22:58:04
22
阅读
Codeforces Round 953 (Div. 2 ABCDEF题) 视频讲解
2024-04-28 22:58:04
22
阅读
生产看板管理系统内容有哪些?
2024-04-28 22:58:04
22
阅读
vue修改node_modules打补丁步骤和注意事项_node_modules 打补丁
2024-04-28 22:58:04
20
阅读
通过文章id递归查询所有评论(xml)
2024-04-28 22:58:04
20
阅读
npm语义化版本和版本运算符
2024-04-28 22:58:04
21
阅读
多线程与高并发- Synchronized锁
2024-04-28 22:58:04
21
阅读
Elasticsearch docker 安装及基本用法
2024-04-28 22:58:04
22
阅读
热门阅读
HTML 官网进行移动端和 PC 端适配
2024-04-28 22:58:04
10
阅读
React | React.cloneElement 的使用
2024-04-28 22:58:04
8
阅读
计算机二级公共基础知识 目录
2024-04-28 22:58:04
10
阅读
C++ day2
2024-04-28 22:58:04
9
阅读
linux下安装anaconda
2024-04-28 22:58:04
10
阅读
微星主板安装双系统不能进入Ubuntu的解决办法
2024-04-28 22:58:04
10
阅读
dremio数据湖sql行列转换及转置
2024-04-28 22:58:04
13
阅读
4.28总结
2024-04-28 22:58:04
10
阅读
【八股】测开
2024-04-28 22:58:04
9
阅读
Git变更账户、查看账户
2024-04-28 22:58:04
11
阅读
枚举(enum)/共用体(union)/结构体(struct)---详解
2024-04-28 22:58:04
8
阅读
BIO、NIO与AIO
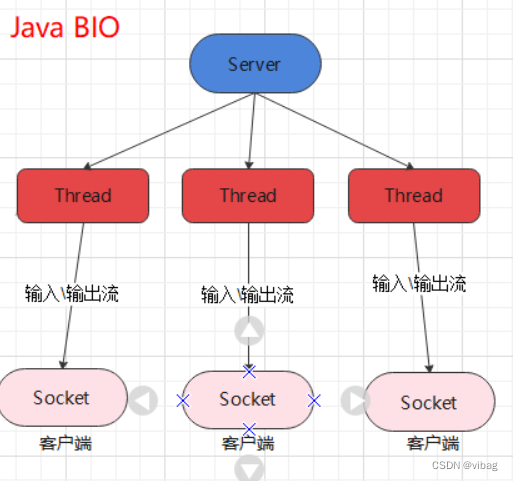
2024-04-28 22:58:04
9
阅读
第4篇:创建Nios II工程之Hello_World<三>
2024-04-28 22:58:04
9
阅读
重仓比特币
2024-04-28 22:58:04
13
阅读
回归预测 | MATLAB实现BO-BP贝叶斯优化BP神经网络多输入单输出回归预测
2024-04-28 22:58:04
11
阅读
16.Blender 基础渲染工作流程及安装ACES
2024-04-28 22:58:04
10
阅读
MATLAB非均匀网格梯度计算
2024-04-28 22:58:04
8
阅读
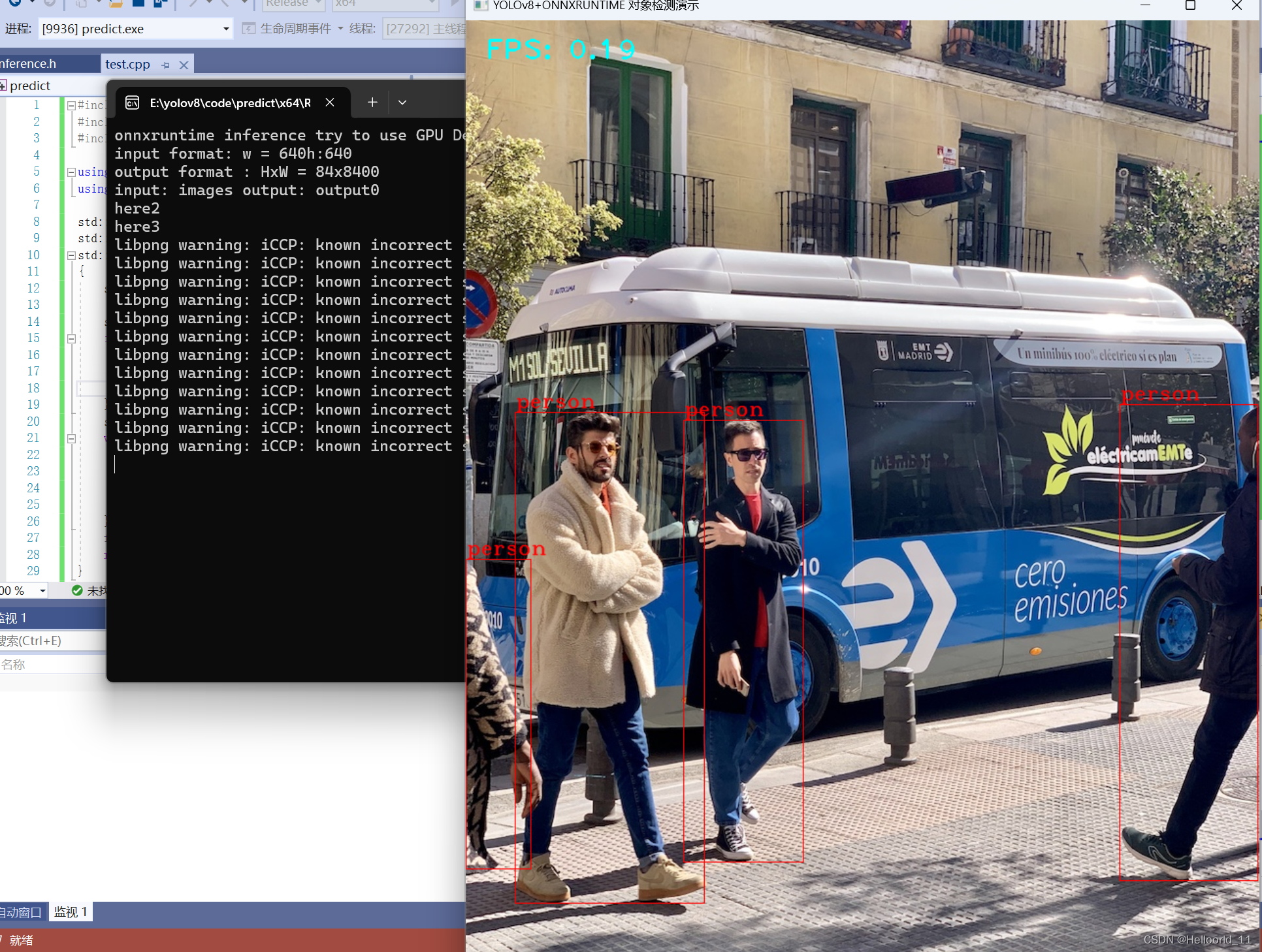
使用yolov8+QT+onnrunxtime进行开发的注意事项
2024-04-28 22:58:04
8
阅读
关于ListView的使用及其实现原理
2024-04-28 22:58:04
12
阅读
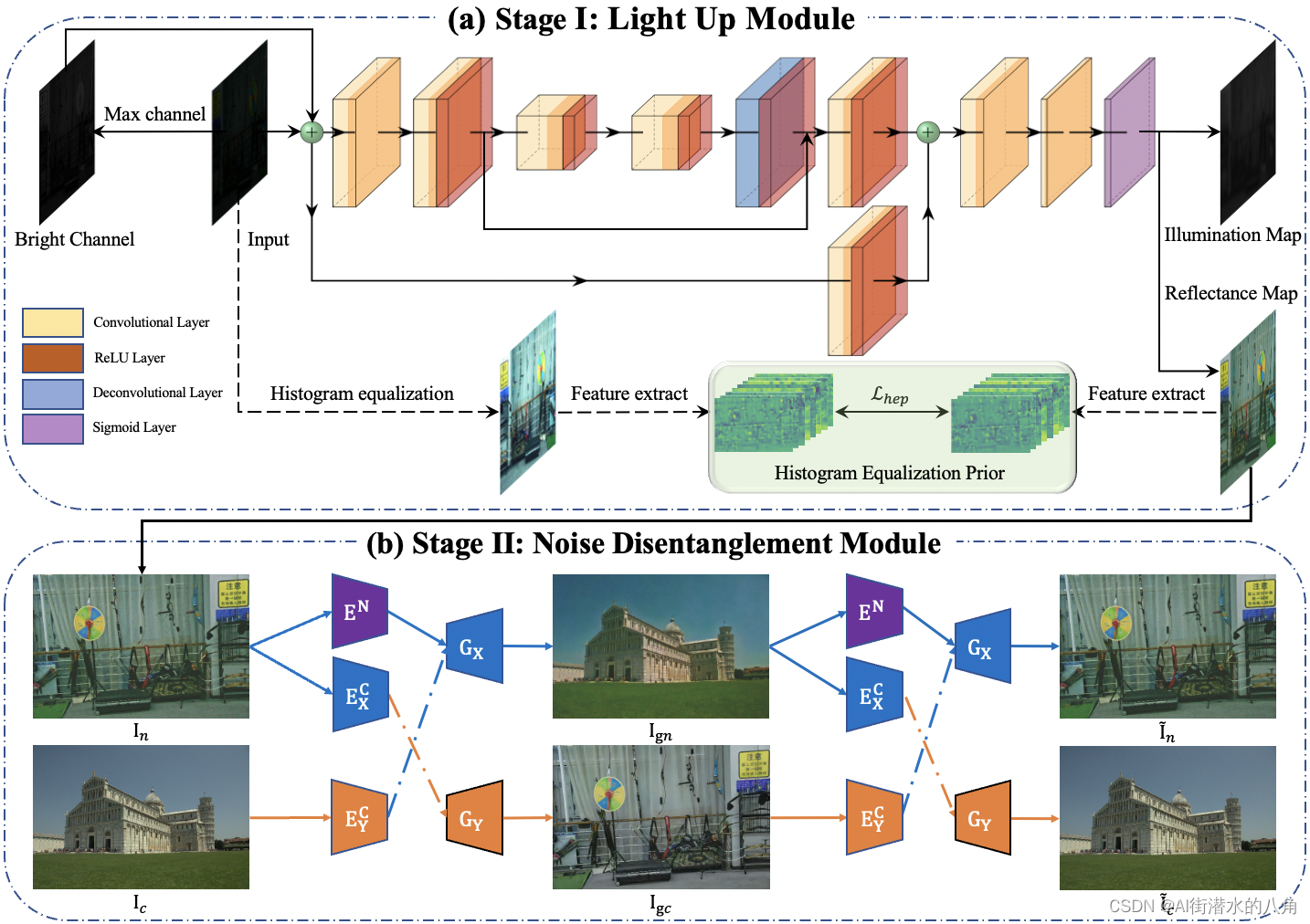
基于深度学习神经网络的AI弱光图像增强HEP系统源码
2024-04-28 22:58:04
9
阅读
面试八股——常见数据结构
2024-04-28 22:58:04
13
阅读
同事上班这样摸鱼,我坐边上咋看他都在专心写代码啊
2024-04-28 22:58:04
11
阅读
经典的目标检测算法有哪些?
2024-04-28 22:58:04
15
阅读
Spring Boot 如何实现缓存预热
2024-04-28 22:58:04
10
阅读
半导体企业信息化系统规划思路
2024-04-28 22:58:04
13
阅读
#天空星RTC
2024-04-28 22:58:04
12
阅读
币圈是什么意思?币圈开发
2024-04-28 22:58:04
12
阅读
go语言实现简单ngnix样例
2024-04-28 22:58:04
8
阅读
如何在Windows 10上刷新DNS?这里提供详细步骤
2024-04-28 22:58:04
13
阅读
欧科云链:为什么减半对比特币生态的影响正在逐步“减弱”?
2024-04-28 22:58:04
11
阅读