前言:谷歌轻量化卷积神经网络Mnasnet,介于MobileNet V2和V3之间。使用多目标优化的目标函数,兼顾速度和精度,其中速度用真实手机推断时间衡量。提出分层的神经网络架构搜索空间,将卷积神经网络分解为若干block,分别搜索各自的基本模块,保证层结构多样性。
CVPR2019论文:Mnasnet: Platform-aware neural architecture search for mobile
相关回顾:
【嵌入式AI开发】轻量级卷积神经网络MobileNetV1详解-CSDN博客
【嵌入式AI开发】轻量级卷积神经网络MobileNetV2详解-CSDN博客
【嵌入式AI开发】轻量级卷积神经网络MobileNetV1、MobileNetV2、ResNet50项目实战——文末完整源码工程文件-CSDN博客
Mnasnet是介于MobileNetV2和MobileNetV3之间的一个算法,若想看懂MobileNetV3,最好先看懂Mnasnet再看MobileNetV3。接下来进行Mnasnet详细解读。
目录
Mnasnet概述
Mnasnet主要有两点创新:
第一点是,运用多目标优化函数
第二点是,分层的NAS搜索空间
多目标优化函数
前言:轻量化网络一方面要让速度足够快,另外一方面让性能精度足够好,满足多个多目标的优化。
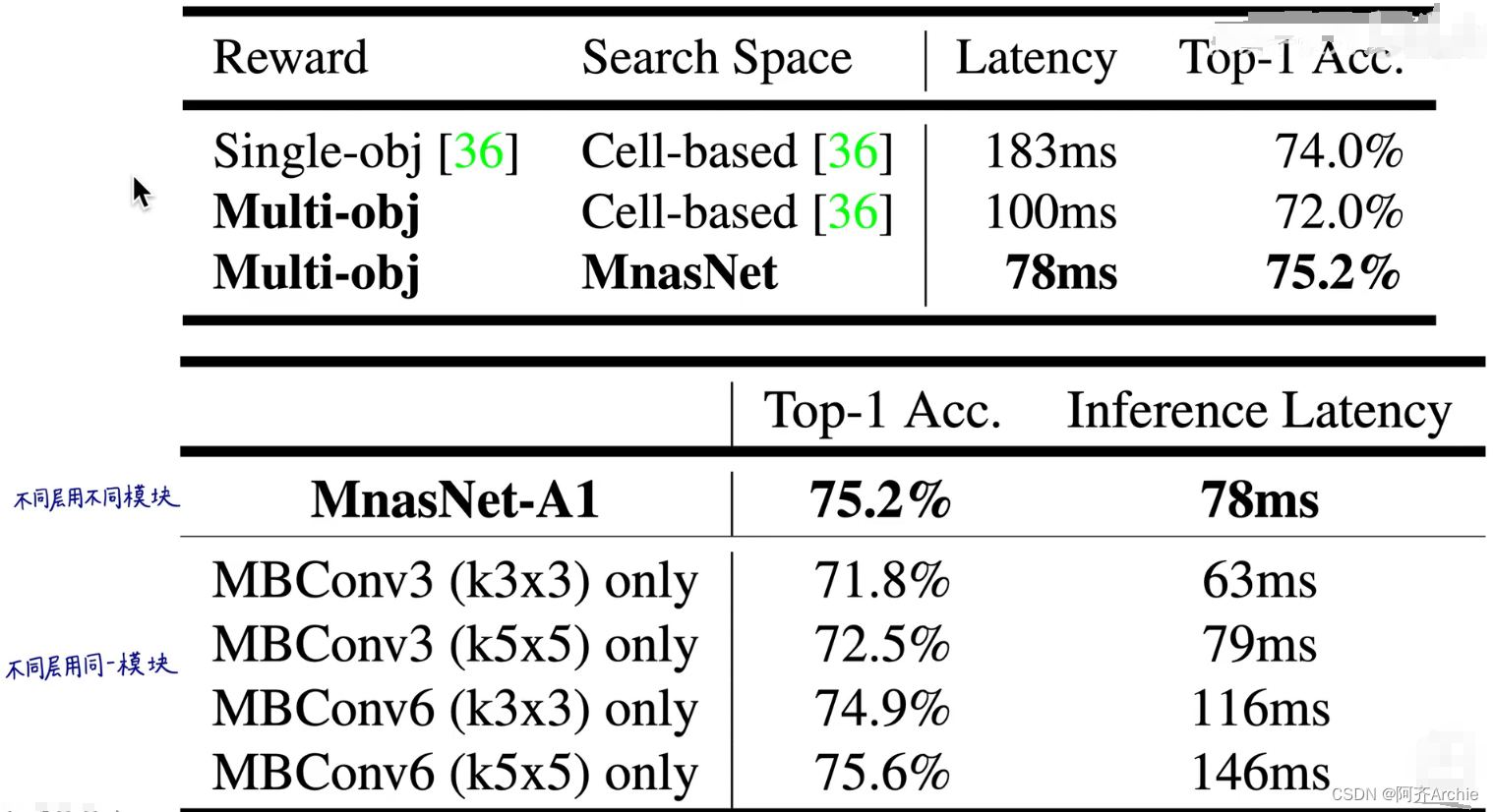
Mnasnet运用了一个多目标优化函数,优化函数兼顾速度和精度,其中速度就是用真实手机推理的时间延迟来表示。既不用传统的浮点数运算量flops也不用内存的访问量也不用参数量,直接用最真实的手机推理时间来表示速度。
如下第一个公式所示的多目标优化函数maximize
其中ACC(m)表示准确率,T是一个常数表示硬指标(比如我们想让模型在80ms内完成预测,那T就等于80ms),LAT(m)是预测时间,w是小于等于0(所以当LAT(m)越大则方括号内的w次方就越小)
所以想让目标函数尽可能大的话,ACC(m)得足够大,LAT(m)的足够小。最终的目标是找到某个模型m使得目标函数最大化。
w的取值如下第二个公式所示
当满足硬指标时,也就是第一个公式的方括号内小于1时,w的取值为α;
不满足硬指标时,也就是第一个公式的方括号内大于1时,w的取值为β。

如下,可以设置α为0,β为-1或者α,β都为-0.07。
当α为0,β为-1时表示在满足硬指标的时候(80),w为0(任何数的0次方等于1),也就是当小于硬指标情况下的目标函数值就是ACC(m)与LAT(m)无关,是一个常函数;当大于硬指标时,w为β的值为-1,就会显著的惩罚LAT(m),目标函数值会急剧的减小,与LAT(m)非常有关。
当α,β都为-0.07时,就会变成比较平滑曲线,不管是低于硬指标还是高于硬指标,目标函数值与LAT(m)的关系都是平滑的,不会出现严厉的惩罚。
以上两种情况,就造成了模型的两种搜索行为。第一种情况α为0,β为-1时模型会待在舒适区(更集中,因为一旦超过硬指标就会被显著的惩罚);第二种情况α,β都为-0.07时,模型的搜索空间就会更多,就能搜索到更多样的速度和精度的权衡,搜索到不同组的帕累托最优解。(更平均,多样)
所以当α为0,β为-1时模型集中在小于硬指标的情况;α,β都为-0.07时模型会尽可能宽泛的搜索得到一个更平均更多样的帕累托最优解。

补充:帕累托最优(Pareto Optimality)
帕累托最优(Pareto Optimality),也称为帕累托效率(Pareto efficiency),是指资源分配的一种理想状态,假定固有的一群人和可分配的资源,从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改进或帕累托最优化。
分层的NAS搜索空间
前言:NAS神经架构搜索(简单来说就是让人工智能去设计一个网络)。做NAS比较玄学,是顶级炼丹,非常消耗算力,一般不建议深究。
分层的神经架构搜索空间将一个卷积神经网络分成了7个bolck,每个block里的结构是一样的(比如Layer2-1和Layer2-2结构是一样的),block2有n2层,block4有n4层;但是block之间的结构是不一样的,所以这就使得我们可以设计网络不同部位,深层和浅层的模型结构。
人工智能强化学习可以搜索出如下图中蓝色字体的参数。最终找到一个最优解,这是一个非常庞大的搜索空间。
其中,SE为注意力机制(即插即用的模块)
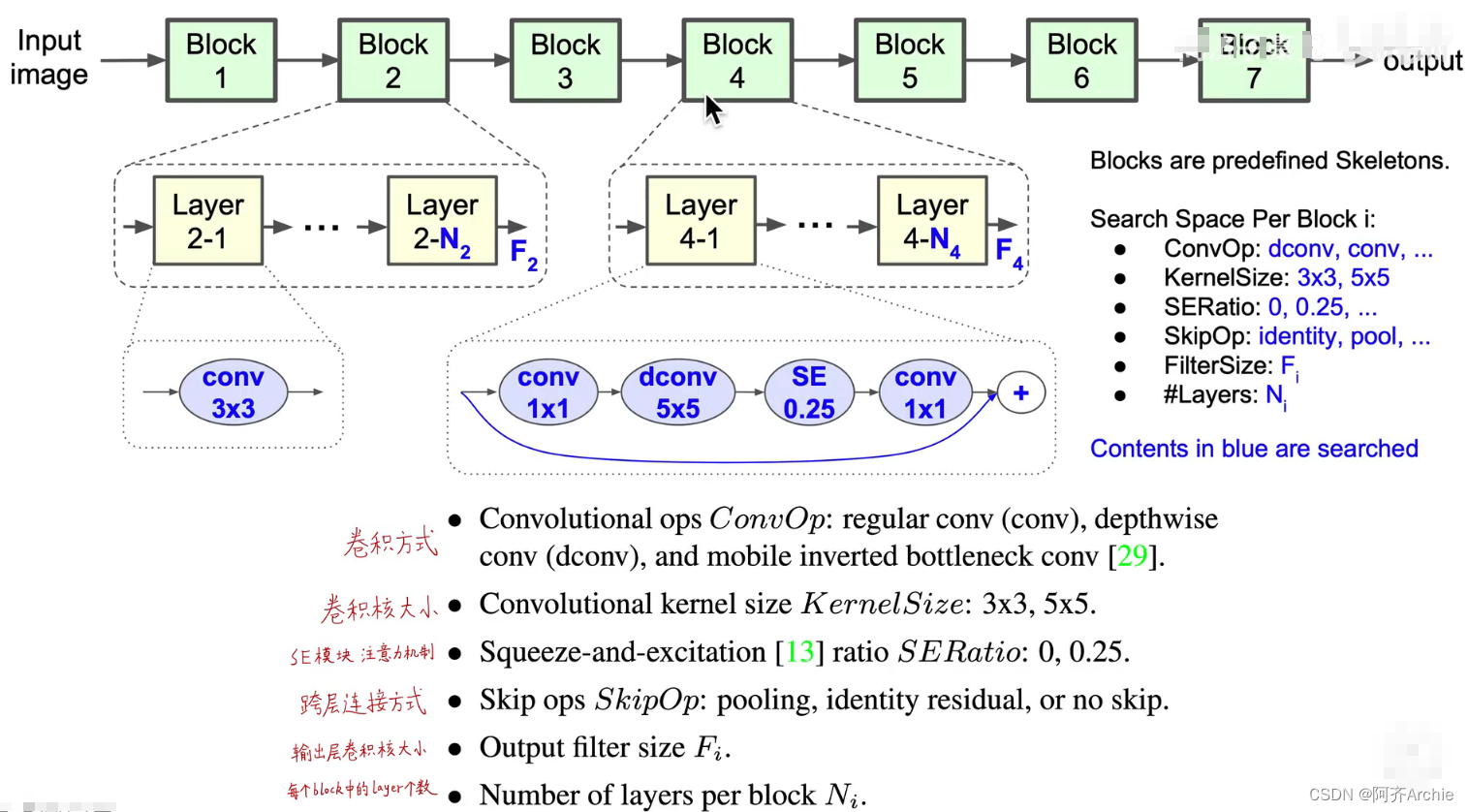
这种分层分解的搜索空间能够使得不同block的结构的多样性。而不再像以前那样搜索出一个模块然后就用同样的模块进行重复的堆叠,整个网络都由一种模块构成(这是不符合直觉和科学的)。分层分解的搜索空间就实现了不同层结构的多样性。
强化学习
强化学习用一个循环神经网络(RNN)作为“智能体”,采取一系列的行动生成一系列的模型,每生成一个模型就把这个模型训练出来,获取模型精度,然后在真实的手机上获得实测速度,进而由速度和精度算出多目标优化函数,再由这个函数作为奖励反馈给“智能体”。以上就是一个典型的强化学习的学习流程。如下图所示。
智能体在大自然中受到大自然的反馈后采取一系列新的动作,新的动作会造成新的反馈和奖励,最终的目标是使得奖励函数和期望值最大化。
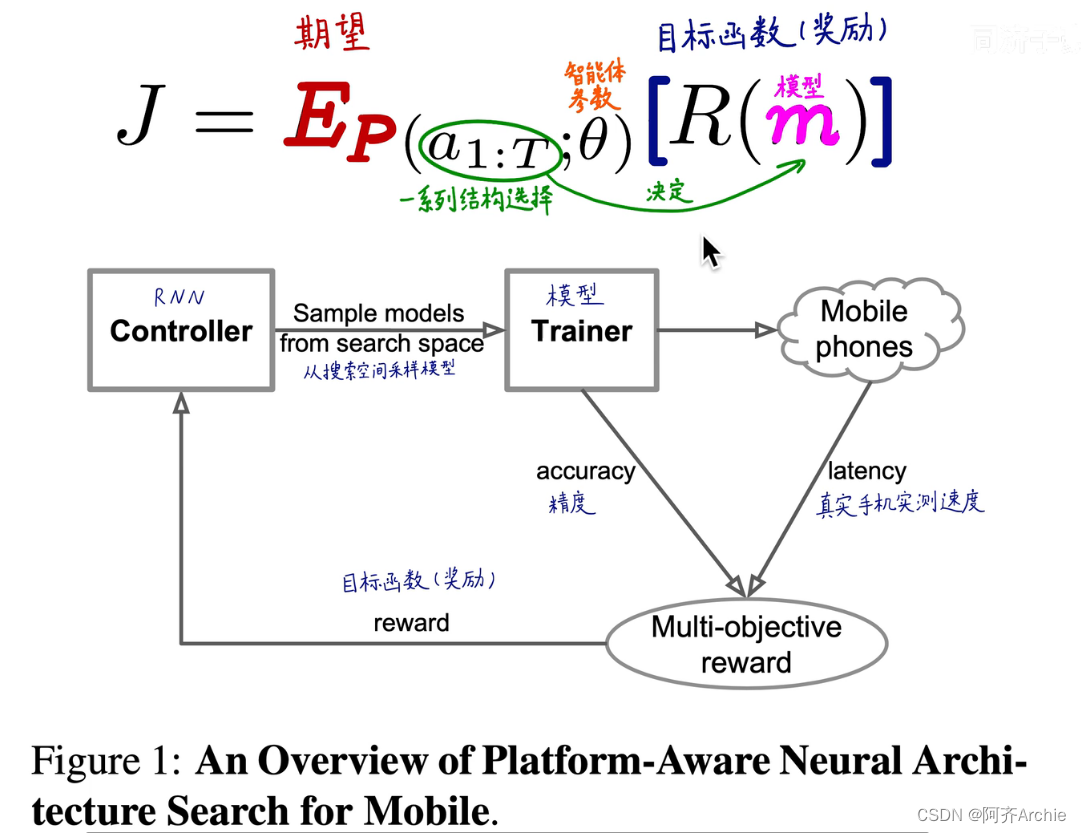
进而搜索出模型 Mnasnet-A1
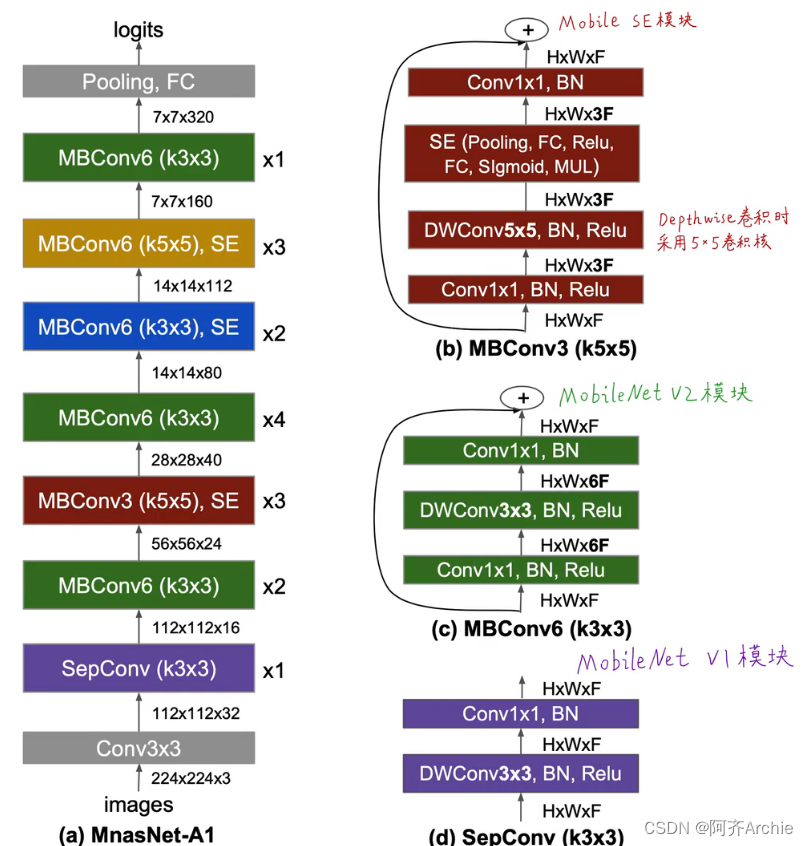
Mnasnet-A1网络结构
如下, Mnasnet-A1网络分为7个block
其中,sepconv表示MobileNetV1的深度可分离卷积,mbconv表示MobileNetV2的逆残差结构模块,mbconv表示加了SE注意力机制模块的逆残差模块
其中,x1、x2等表示每一block的层数,k5*5表示用的是5*5的卷积核
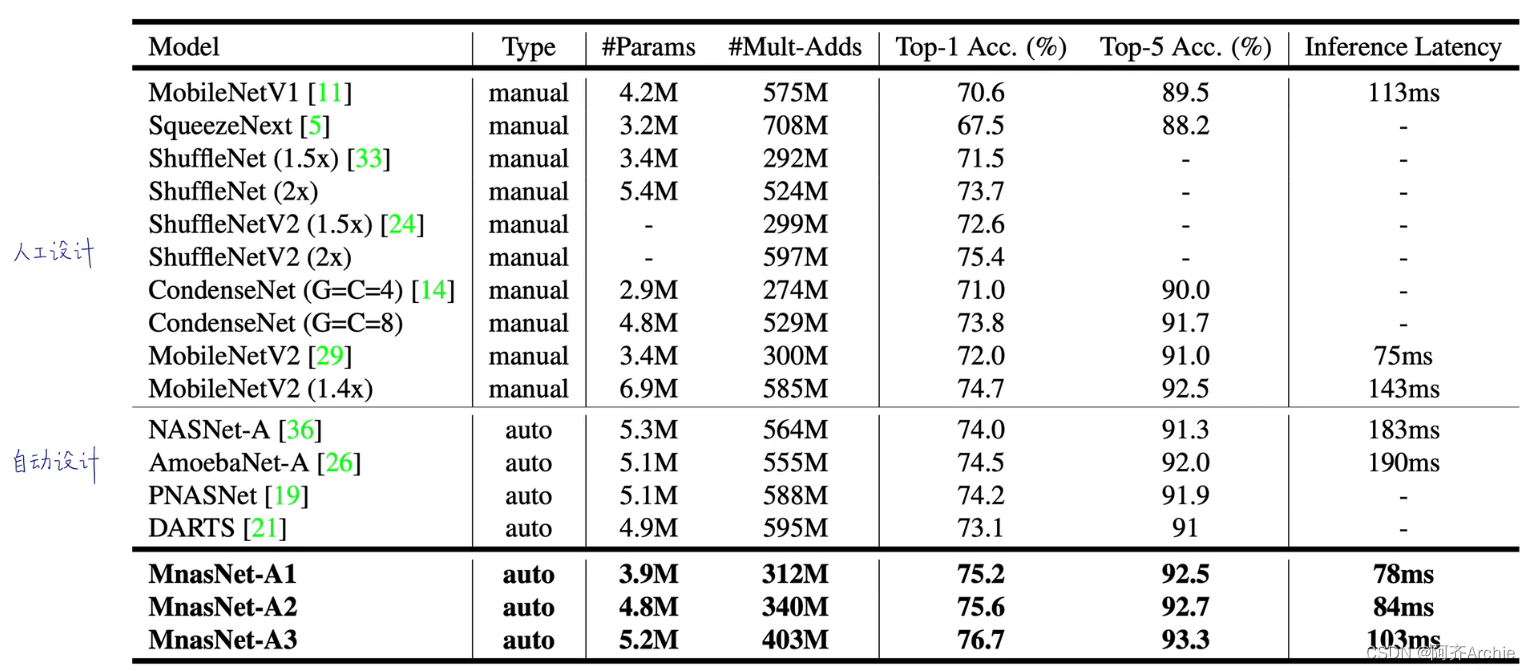
实验结果对比

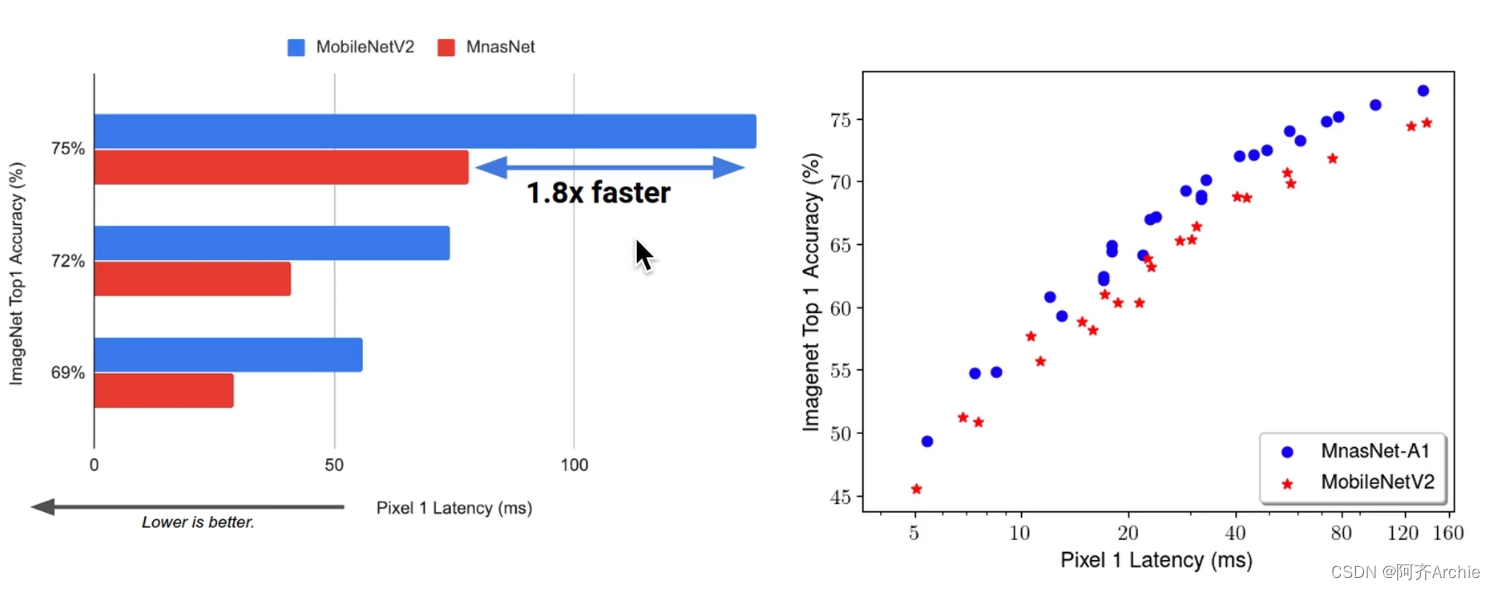
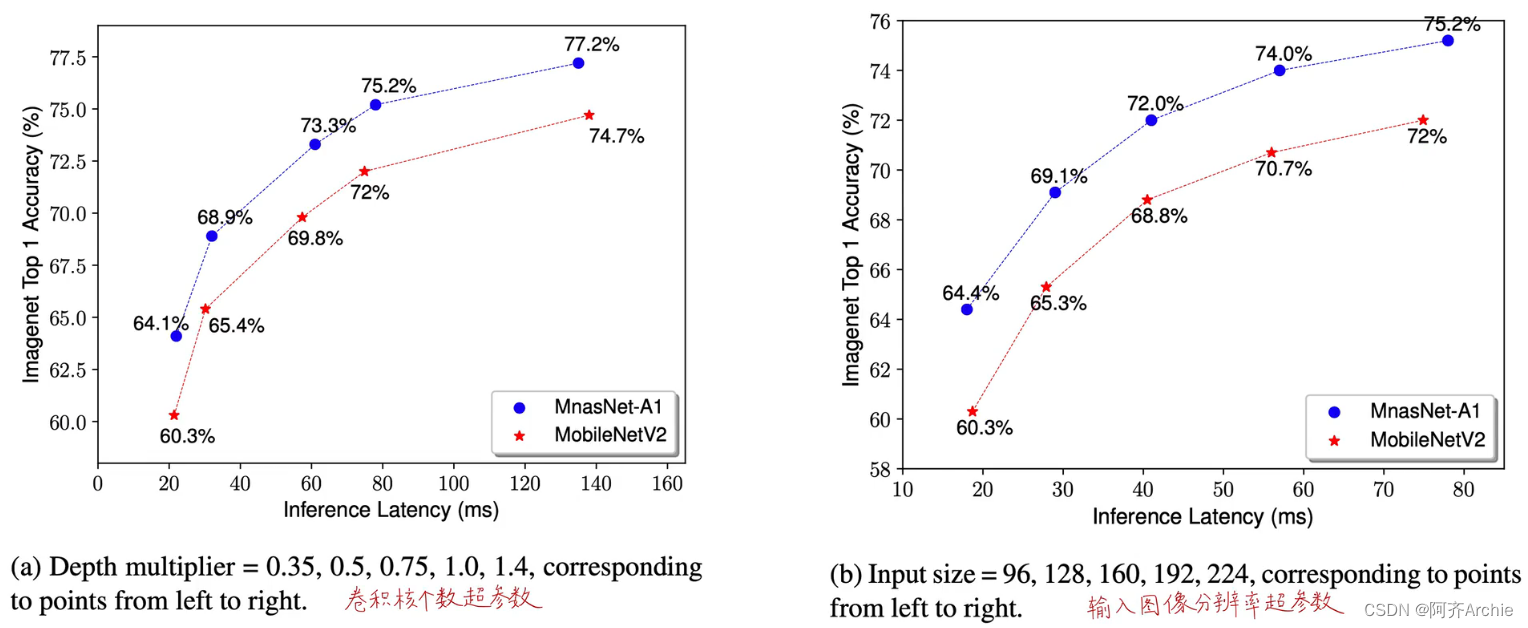
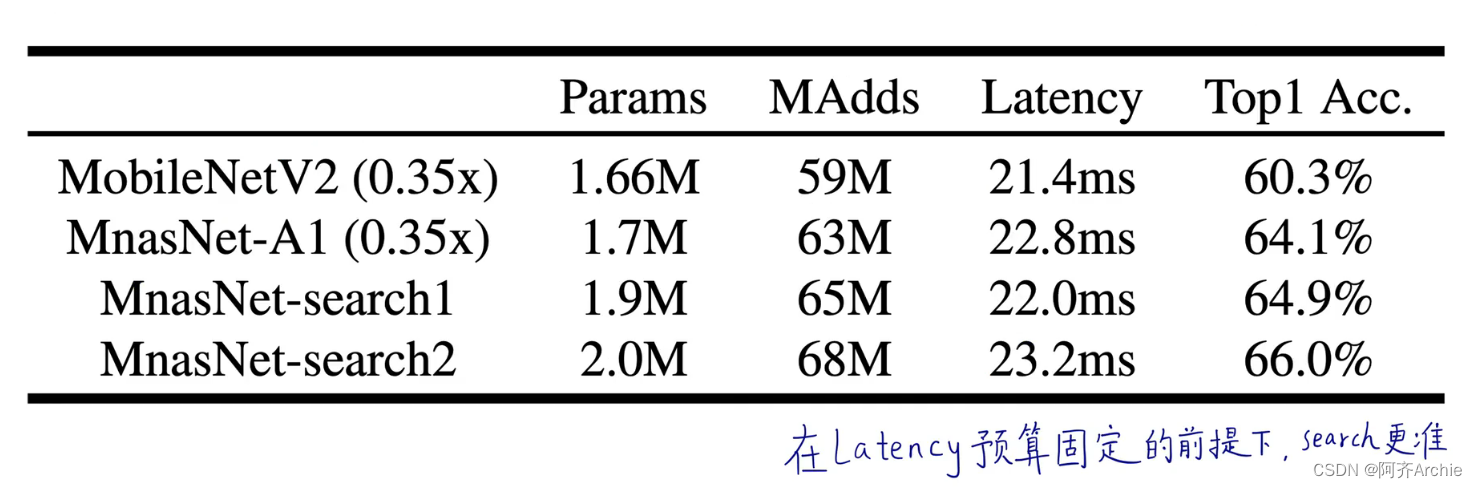
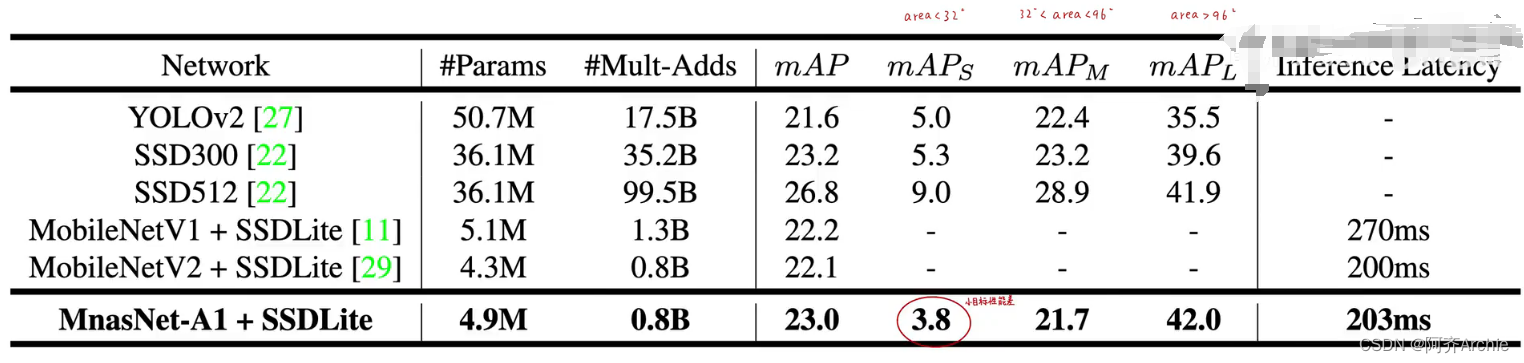

代码与网络结构的对应
如下所示。

补充:1.SE注意力机制
SE(Squeeze-and-Excitation)注意力机制是一种用于提高深度学习模型,特别是卷积神经网络(CNN)性能的技术。它通过显式地建模卷积特征通道之间的相互依赖关系,使得模型能够学习到每个通道的重要性,并自适应地调整通道的权重。SE注意力机制的核心在于两个阶段:Squeeze和Excitation。
Squeeze阶段:在这一阶段,通过全局平均池化操作,将输入特征图的每个通道压缩成一个标量,这个标量代表了对应通道的全局信息。这个过程使得模型能够获得每个通道的平均响应强度。
Excitation阶段:在这一阶段,模型学习到通道之间的相互依赖关系。通常,这一阶段包括两个全连接层,第一个全连接层会减少通道的数量,第二个全连接层则会恢复到原来的通道数量。在这两个全连接层之间,通常会使用ReLU激活函数。最后,通过Sigmoid函数,将每个通道的权重压缩到0到1之间,从而可以与原始输入特征图相乘,得到加权后的特征图。
通过SE注意力机制,模型可以重点关注那些权重值较大的通道,同时抑制那些权重值较小的通道,从而提高模型的特征提取和表达能力。这种机制不仅适用于卷积神经网络,也可以很容易地集成到其他类型的神经网络结构中,如mini_Xception网络。
2.硬指标latency为25ms则为40FPS
3.ckpt权重文件
4.线性激活函数可以理解为不使用激活函数