0.概述
介绍了有序向量二分查找与Fibonacci查找,再介绍下有序向量的插值查找。
1. 原理与算法
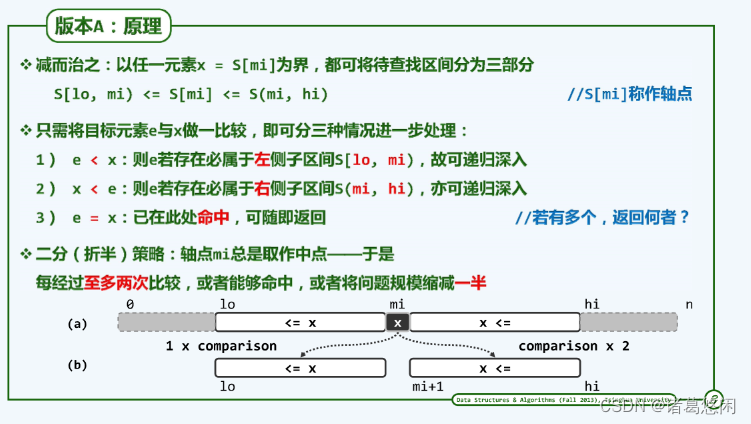
算法基于二分查找(binary search) 演变而成,拥有二分查找时间复制度小的优点,而思想也几乎是继承了二分查找。
算法前提:有序且分布均匀且独立

轴点mi值依据首尾索引值、该位置上对应的值和待查找元素大致猜测。
该公式即为mid点的选取方式,而在 e < A[mi] 时则将high取为mid - 1,这点与二分查找同理,e > A[mid]时则同理将 low 取为 mid + 1

2. 性能

- 对二长度为 n 的此类向量,插值查找的期望运行时间为 O(loglogn)

3. 实现
//实现插值查找算法,ele 表示要查找的目标元素,[begin,end] 指定查找区域
int interpolation_search(int* arr, int begin, int end, int ele) {
int mid = 0;
//如果[begin,end] 不存在,返回 -1
if (begin > end) {
return -1;
}
//如果搜索区域内只有一个元素,判断其是否为目标元素
if (begin == end) {
if (ele == arr[begin]) {
return begin;
}
//如果该元素非目标元素,则查找失败
return -1;
}
// 找到"中间元素"所在的位置
mid = begin + ((end - begin) / (arr[end] - arr[begin]) * (ele - arr[begin]));
//递归的出口
if (ele == arr[mid]) {
return mid;
}
//比较 ele 和 arr[mid] 的值,缩小 ele 可能存在的区域
if (ele < arr[mid]) {
//新的搜索区域为 [begin,mid-1]
return interpolation_search(arr, begin, mid - 1, ele);
}
else {
//新的搜索区域为 [mid+1,end]
return interpolation_search(arr, mid + 1, end, ele);
}
}
4. 不足
未严格遵守search()语义,即返回确定不大于e的最后一个元素得秩,而不是-1。
5. 综合

当需要查找的数据源极大的时候,插值查找可以很大程度上缩短所需的时间,而在极小的数据源中,顺序查找更优,二分查找以及斐波那契查找则相较占中些。
大规模:插值查找
中规模:折半查找
小规模:顺序查找
参考连接:https://blog.csdn.net/glassesone/article/details/106910155