文章目录
0.概述
若向量S[0, n)中的所有元素不仅按线性次序存放,而且其数值大小也按此次序单调分布,则称作有序向量(sorted vector)。
1.比较器
有序向量的定义的先决条件:各元素之间必须能够比较大小和判等操作。这一条件构成了有序向量中“次序”概念的基础,否则所谓的“有序”将无从谈起。
复杂数据对象应重载"<“和”<="等操作符。
2.有序性甄别

算法思想:顺序扫描整个向量,逐一比较每一对相邻元素——向量已经有序,当且仅当它们都是顺序的。
template <typename T>
int Vector<T>::disordered() const { //返回向量中逆序相邻元素对的总数
int n = 0; //计数器
for ( int i = 1; i < _size; i++ ) //逐一检查_size - 1对相邻元素
if ( _elem[i - 1] > _elem[i] ) n++; //逆序则计数
return n; //向量有序当且仅当n = 0
}
3.唯一化
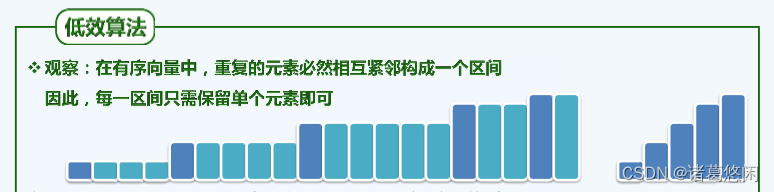
出于效率的考虑,为清除无序向量中的重复元素,一般做法往往是首先将其转化为有序向量。
3.1低效算法
3.1.1实现
算法思想:
template <typename T>
int Vector<T>::uniquify() { //有序向量重复元素剔除算法(低效版)
int oldSize = _size; int i = 1; //当前比对元素的秩,起始于首元素
while ( i < _size ) //从前向后,逐一比对各对相邻元素
_elem[i - 1] == _elem[i] ? remove ( i ) : i++; //若雷同,则初除后者;否则,转至后一元素
return oldSize - _size; //向量觃模发化量,即被初除元素总数
}
3.1.2 复杂度

分析需用结论:remove()操作的复杂度线性正比于被删除元素的后继元素总数。不清除的可看无序向量。
最坏情况下:
当所有元素均雷同时,用于所有这些remove()操作的时间总量将高达:
(n - 2) + (n - 3) + … + 2 + 1= O( n 2 n^2 n2) 由算术级数得 。不清楚可看算法分析
这一效率竟与向量未排序时相同,说明该方法未能充分利用此时向量的有序性。
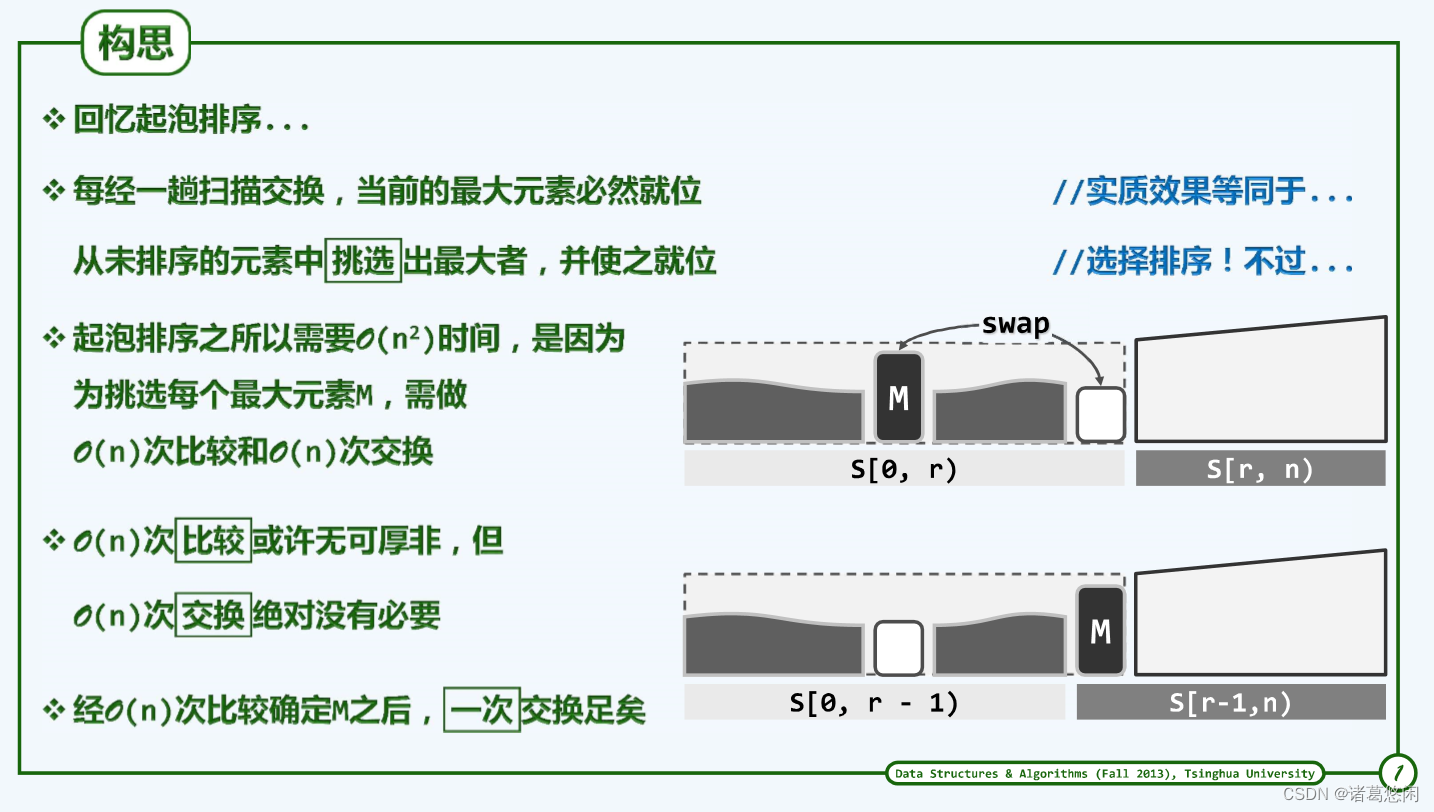
3.1.3 改进思路
反思:低效的根源在于,同一元素可作为被删除元素的后继多次前移
启示:若能以重复区间为单位,成批删除雷同元素,性能必能改进。
3.2 高效算法
3.2.1 实现
算法思想:
可以区间为单位成批地删除前后紧邻的各组重复元素,并将其后继元素(若存在)统一地大跨度前移。
template <typename T>
Rank Vector<T>::uniquify() { //有序向量重复元素剔除算法(高效版)
Rank i = 0, j = 0; //各对互异“相邻”元素的秩
while ( ++j < _size ) //逐一扫描,直至末元素
if ( _elem[i] != _elem[j] ) //跳过雷同者
_elem[++i] = _elem[j]; //发现不同元素时,向前移至紧邻于前者右侧
_size = ++i; shrink(); //直接截除尾部多余元素
return j - i; //向量规模变化量,即被删除元素总数
}
3.2.2 复杂度
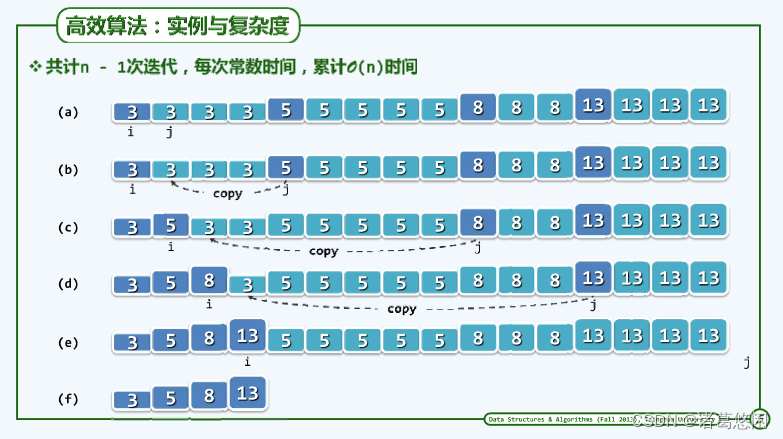
由此可知,uniquify()算法的时间复杂度应为O(n),较之无序向量唯一化算法的O( n 2 n^2 n2),效率整整提高了一个线性因子。关键在于向量已经排序。
4.查找
4.1统一接口
为区别于无序向量的查找接口find(),有序向量的查找接口将统一命名为search()。外部接口形式上统一,内部实现算法却不见得完全统一。
template <typename T> //在有序向量的区间[lo, hi)内,确定不大于e的最后一个节点的秩
Rank Vector<T>::search( T const& e, Rank lo, Rank hi ) const { // 0 <= lo < hi <= _size
return ( rand() % 2 ) ? binSearch( _elem, e, lo, hi ) : fibSearch( _elem, e, lo, hi );
} //等概率地随机使用二分查找、Fibonacci查找
- 如何处理特殊情况?
比如,目标不存在;或者反过来,目标元素同时存在多个
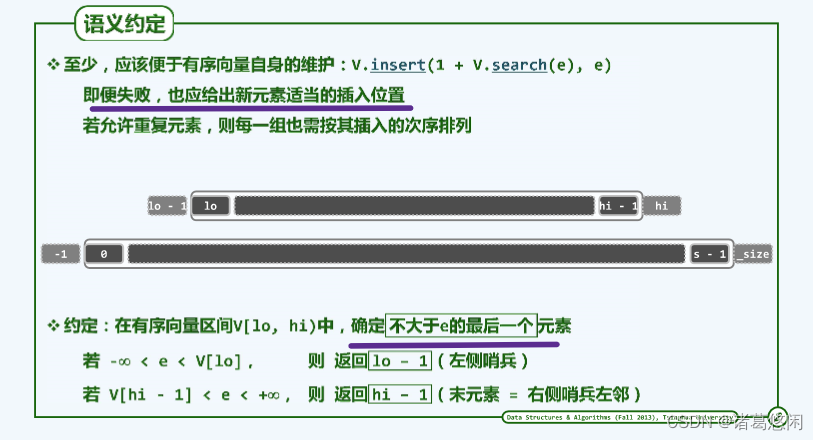
4.2 语义定义
在语义上进一步的细致约定,使search()接口作为一个基本部件为其他算法利用。
在有序向量区间V[lo,hi)中,确定不大于e的最后一个元素。
4.3 二分查找
4.3.1 原理
算法思想:减而治之
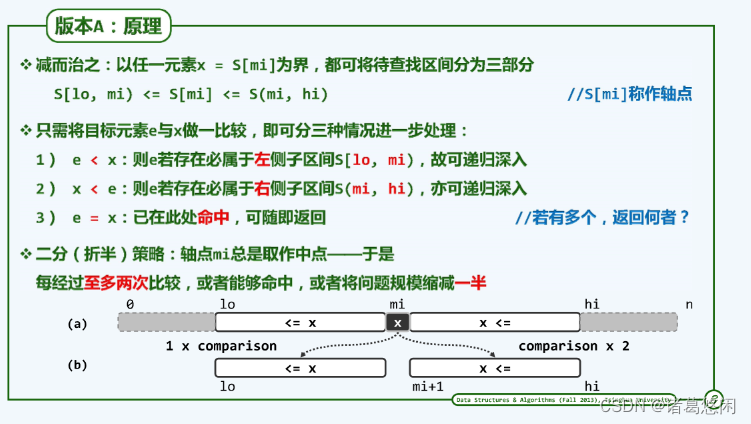
每经过至多两次比较操作,可以将查找问题简化为一个规模更小的新问题。如此,借助递归机制即可便捷地描述和实现此类算法。
4.3.2 实现
//二分查找算法(版本A):在有序向量的区间[lo, hi)内查找元素e,0 <= lo <= hi <= _size
template <typename T> static Rank binSearch( T* S, T const& e, Rank lo, Rank hi ) {
/*DSA*/printf ( "BIN search (A)\n" );
while ( lo < hi ) { //每步迭代可能要做两次比较判断,有三个分支
/*DSA*/ for ( int i = 0; i < lo; i++ ) printf ( " " ); if ( lo >= 0 ) for ( int i = lo; i < hi; i++ ) printf ( "....^" ); printf ( "\n" );
Rank mi = ( lo + hi ) >> 1; //以中点为轴点(区间宽度折半,等效于其数值表示的右移一位)
if ( e < S[mi] ) hi = mi; //深入前半段[lo, mi)继续查找
else if ( S[mi] < e ) lo = mi + 1; //深入后半段(mi, hi)继续查找
else return mi; //在mi处命中
/*DSA*/ if ( lo >= hi ) { for ( int i = 0; i < mi; i++ ) printf ( " " ); if ( mi >= 0 ) printf ( "....|\n" ); else printf ( "<<<<|\n" ); }
} //成功查找可以提前终止
return -1; //查找失败
} //有多个命中元素时,不能保证返回秩最大者;查找失败时,简单地返回-1,而不能指示失败的位置
通过快捷的整数移位操作回避了相对更加耗时的除法运算。
另外,通过引入lo、hi和mi等变量,将减治算法通常的递归模式改成了迭代模式。(递归消除)
4.3.3 复杂度

随着迭代的不断深入,有效的查找区间宽度将按1/2的比例以几何级数的速度递
减。经过至多log2(hi - lo)步迭代后,算法必然终止。故总体时间复杂度不超过:
O( l o g 2 ( h i − l o ) log_2(hi - lo) log2(hi−lo)) = O(logn)
上图中的递归公式也可得出这个结论,递推公式不熟悉的可以看递推分析。
顺序查找算法的O(n)复杂度相比无序向量的查找find()无序向量,O(logn)几乎改进了一个线性因子(任意c > 0,logn = O( n c n^c nc))。
4.3.4 查找长度
查找算法的整体效率主要地取决于其中所执行的元素大小比较操作的次数,即所谓查找长度。
通常,需分别针对成功与失败查找,从最好、最坏、平均等角度评估
结论:成功、失败时的平均查找长度均大致为O(1.5logn)
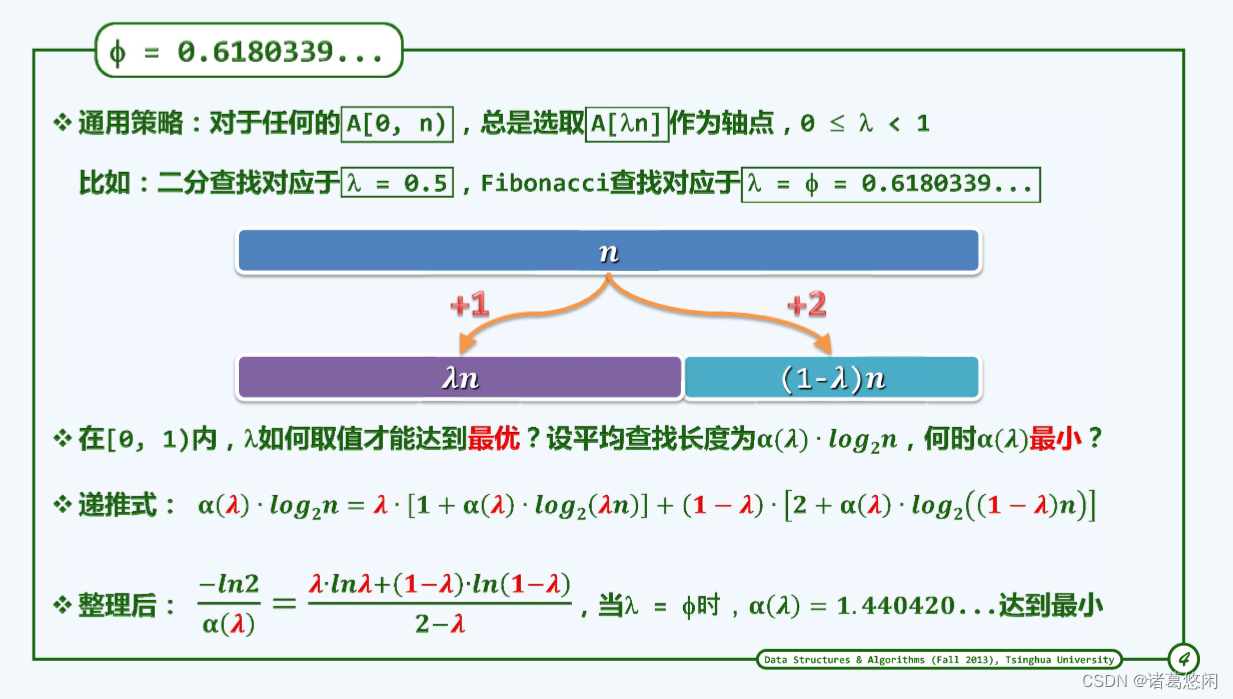
- 成功查找长度
等概率条件下考查长度为n = 2 k 2^k 2k- 1的有序向量,并将其对应的平均成功查找长度记作 c a v e r a g e c_{average} caverage(k),将所有元素对应的查找长度总和记作C(k) = c a v e r a g e c_{average} caverage(k)∙( 2 k 2^k 2k- 1)。
~~~~~~~~~~~ 当k = 1时向量长度n = 1,成功查找仅有一种情况
~~~~~~~~~~~~~~~~~~~~~~~~~ c a v e r a g e c_{average} caverage(1) = C(1) = 2
对于长度为n = 2 k 2^k 2k- 1的有序向量,每步迭代都有三种可能的分支:经过1次成功的比较后,转化为一个规模为 2 k − 1 2^{k-1} 2k−1- 1的新问题(左侧分支);经2次失败的比较后,终止于向量中的某一元素,并确认在此处成功中;经1次失败的比较另加1次成功的比较后,转化为另一个规模为 2 k − 1 2^{k-1} 2k−1- 1的新问题(右侧分支)。
递推公式:
C(k) = [C(k - 1) + ( 2 k − 1 2^{k-1} 2k−1- 1)] + 2 + [C(k - 1) + 2*( 2 k − 1 2^{k-1} 2k−1- 1)] = 2∙C(k - 1) + 3* 2 k − 1 2^{k-1} 2k−1- 1
令 F(k) = C(k) - 3k* 2 k − 1 2^{k-1} 2k−1- 1
整理得: c a v e r a g e c_{average} caverage(k) = O(1.5∙log2n)
- 失败查找长度
失败查找可能的情况,恰好比成功查找可能的情况多出一种。
1.5∙log2(n + 1) = O(1.5∙logn)
4.3.5 不足
尽管二分查找算法(版本A)即便在最坏情况下也可保证O(logn)的渐进时间复杂度,但就其常系数1.5而言仍有改进余地。见
4.4 Fibonacci查找
4.4.1 思路及原理
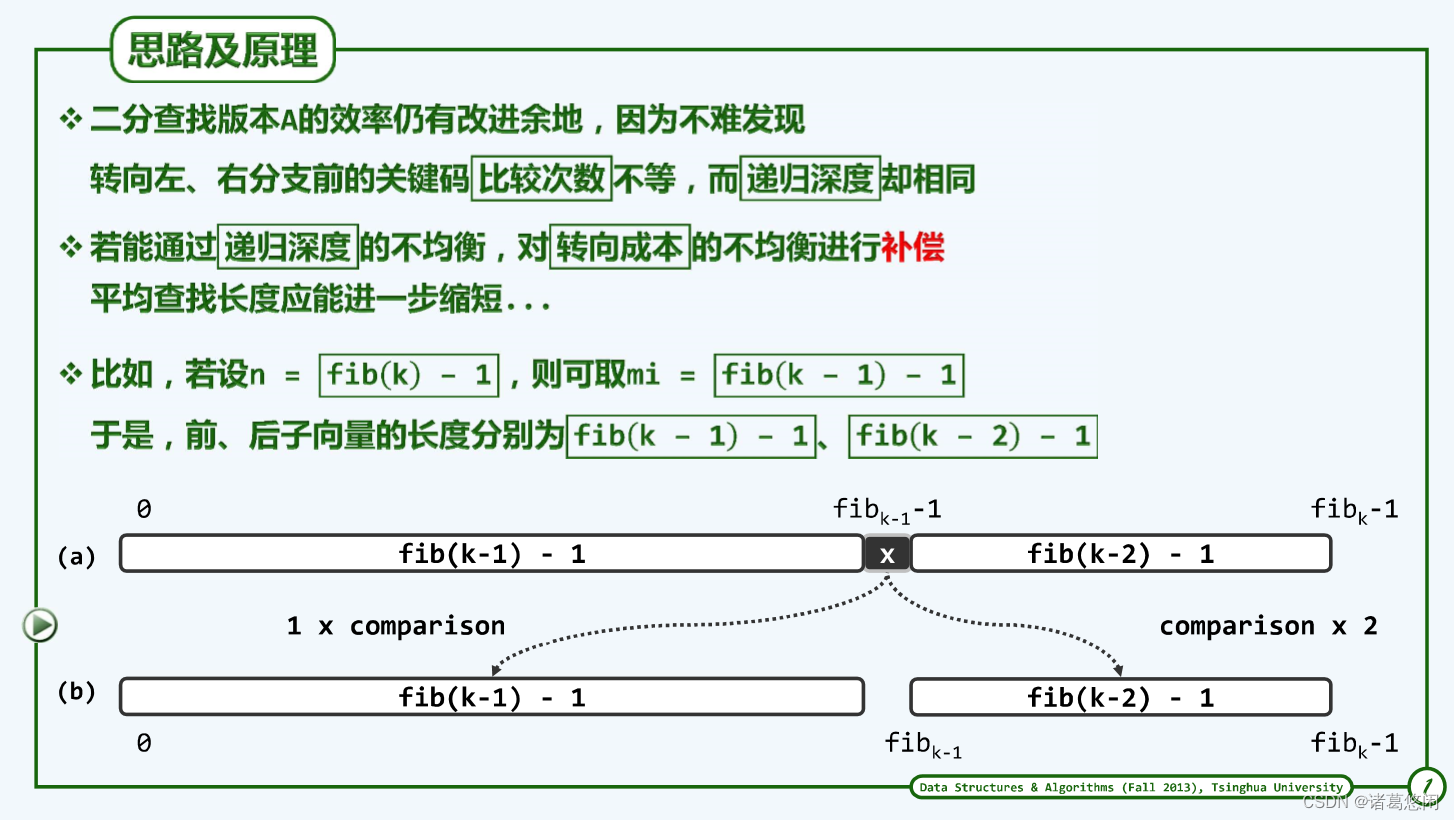 调整前、后区域的宽度,适当地加长(缩短)前(后)子向量
调整前、后区域的宽度,适当地加长(缩短)前(后)子向量
4.4.2 实现
#include "fibonacci/Fib.h" //引入Fib数列类
//Fibonacci查找算法(版本A):在有序向量的区间[lo, hi)内查找元素e,0 <= lo <= hi <= _size
template <typename T> static Rank fibSearch( T* S, T const& e, Rank lo, Rank hi ) {
/*DSA*/printf ( "FIB search (A)\n" );
//用O(log_phi(n = hi - lo)时间创建Fib数列
for ( Fib fib( hi - lo ); lo < hi; ) { //Fib制表备查;此后每步迭代仅一次比较、两个分支
/*DSA*/ for ( Rank i = 0; i < lo; i++ ) printf ( " " ); if ( lo >= 0 ) for ( Rank i = lo; i < hi; i++ ) printf ( "....^" ); else printf ( "<<<<|" ); printf ( "\n" );
while ( hi - lo < fib.get() ) fib.prev(); //自后向前顺序查找(分摊O(1))
Rank mi = lo + fib.get() - 1; //确定形如Fib(k)-1的轴点
if ( e < S[mi] ) hi = mi; //深入前半段[lo, mi)继续查找
else if ( S[mi] < e ) lo = mi + 1; //深入后半段(mi, hi)继续查找
else return mi; //在mi处命中
/*DSA*/ if ( lo >= hi ) { for ( int i = 0; i < mi; i++ ) printf ( " " ); if ( mi >= 0 ) printf ( "....|\n" ); else printf ( "<<<<|\n" ); }
} //一旦找到,随即终止
return -1; //查找失败
} //有多个命中元素时,不能保证返回秩最大者;失败时,简单地返回-1,而不能指示失败的位置
对Fib数不清楚得可以看fib
效率略有提高。

























![【Hadoop】-Apache Hive使用语法与概念原理[15]](https://img-blog.csdnimg.cn/direct/66d2055bdcdc441cb2656239a18dadbb.png)