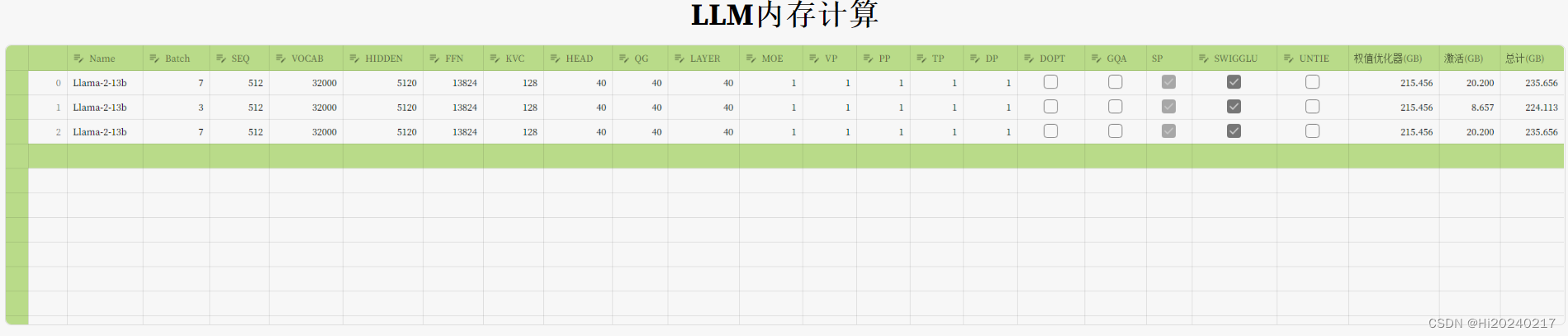
根据用户设置的LLM参数,计算设备内存的占用量。以web的形式方便共享,可以插入多条记录,表格更新后,可以动态计算结果
一.效果
二.代码
import streamlit as st #1.31.1
import cv2
import math
from collections import OrderedDict
import pandas as pd
NUM_BYTES_IN_MEGABYTE = 1024 * 1024 * 1024
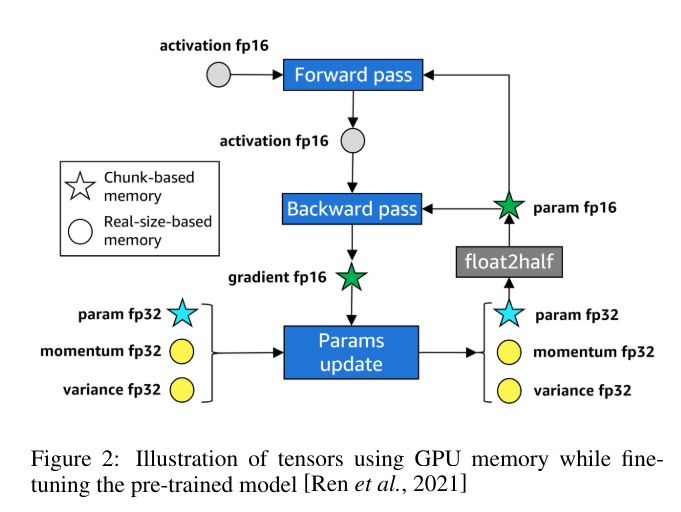
# 计算公式来源: https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/training/theoretical_memory_usage.py
# st.data_editor用法参考: https://zhuanlan.zhihu.com/p/686385274
def compute_weight_and_optimizer_memory(args, verbose=True):
# Attention projection size.
if args.kv_channels==0:
args.kv_channels = args.hidden_size // args.num_attention_heads
query_projection_size = args.kv_channels * args.num_attention_heads
query_projection_to_hidden_size_ratio = query_projection_size / args.hidden_size
# Group Query Attention.
if not args.group_query_attention:
args.num_query_groups = args.num_attention_heads
# MoE.
num_experts = 1 if args.num_experts is None else args.num_experts
gated_linear_multiplier = 3 / 2 if args.swiglu else 1
num_parameters_in_transformer_layers = (
2
* args.num_layers
* args.hidden_size
* args.hidden_size
* (
# Attention.
(
(1 + (args.num_query_groups / args.num_attention_heads))
* query_projection_to_hidden_size_ratio
)
# MLP.
+ ((args.ffn_hidden_size / args.hidden_size) * num_experts * gated_linear_multiplier)
# Transformer layernorms.
+ (2 / args.hidden_size)
# Final layernorm.
+ (1 / (args.num_layers * args.hidden_size))
)
)
embedding_size = args.hidden_size * args.padded_vocab_size
if args.untie_embeddings_and_output_weights:
num_parameters_in_embedding_layers = 2 * embedding_size
else:
num_parameters_in_embedding_layers = embedding_size
num_total_parameters = num_parameters_in_transformer_layers + num_parameters_in_embedding_layers
if verbose:
print(
f"Number of parameters in transformer layers in billions: "
f"{num_parameters_in_transformer_layers / 10**9: .2f}"
)
print(
f"Number of parameters in embedding layers in billions: "
f"{num_parameters_in_embedding_layers / 10**9:.2f}"
)
print(f"Total number of parameters in billions: {num_total_parameters / 10**9:.2f}")
# Most loaded model shard has (1/pp_size transformer layers + 1 embedding layer) / tp_size.
num_parameters_on_most_loaded_model_shard = (
(num_parameters_in_transformer_layers / args.pipeline_model_parallel_size) + embedding_size
) / args.tensor_model_parallel_size
if args.untie_embeddings_and_output_weights and args.pipeline_model_parallel_size == 1:
num_parameters_on_most_loaded_model_shard += (
embedding_size / args.tensor_model_parallel_size
)
if verbose:
print(
f"Number of parameters in most loaded shard in billions: "
f"{num_parameters_on_most_loaded_model_shard / 10**9:.4f}"
)
if args.pipeline_model_parallel_size > 1:
# Other shards just have (1/pp_size transformer layers) / tp_size.
num_parameters_on_other_model_shards = num_parameters_in_transformer_layers / (
args.pipeline_model_parallel_size * args.tensor_model_parallel_size
)
if verbose:
print(
f"Number of parameters in other shards in billions: "
f"{num_parameters_on_other_model_shards / 10**9:.4f}"
)
num_bytes_per_parameter = (
18 if not args.use_distributed_optimizer else 6 + (12 / args.data_parallel_size)
)
weight_and_optimizer_memory = (
num_parameters_on_most_loaded_model_shard * num_bytes_per_parameter
)
return weight_and_optimizer_memory
def compute_activation_memory(args, num_microbatches, verbose=False):
# Using formula in Table 2 of https://arxiv.org/pdf/2205.05198.pdf.
# We are trying to compute the maximum activation footprint, so all calculations in this
# function are for the first pipeline stage.
# TODO: This function needs to take into account query_projection_size potentially being
# different from hidden_size.
# Memory footprint from transformer layer (self-attention and MLP).
activation_memory = (args.seq_length * args.micro_batch_size * args.hidden_size) * (
18 + (4 * (args.ffn_hidden_size / args.hidden_size))
)
if verbose:
print(
f"Activation memory footprint per transformer layer: "
f"{activation_memory / NUM_BYTES_IN_MEGABYTE / args.tensor_model_parallel_size:.1f} MB"
)
activation_memory *= args.num_layers
# Now add activation memory required for input embeddings, last LayerNorm and output layer.
# Input to embedding (pp_size microbatches in flight).
activation_memory += (
8 * args.seq_length * args.micro_batch_size * args.pipeline_model_parallel_size
)
# Dropout in embedding layer (pp_size microbatches in flight).
activation_memory += (
args.seq_length
* args.micro_batch_size
* args.hidden_size
* args.pipeline_model_parallel_size
)
# Multiply by interleaved PP memory factor.
if args.virtual_pipeline_model_parallel_size>0:
interleaved_schedule_memory_penalty = 1 + (
(args.pipeline_model_parallel_size - 1)
/ (args.pipeline_model_parallel_size * args.virtual_pipeline_model_parallel_size)
)
in_flight_microbatches = math.ceil(
interleaved_schedule_memory_penalty * args.pipeline_model_parallel_size
)
if verbose:
print(
f"Memory penalty from interleaved schedule: {interleaved_schedule_memory_penalty:.2f}"
)
print(f"Number of in-flight microbatches: {in_flight_microbatches}")
activation_memory *= interleaved_schedule_memory_penalty
# If using non-interleaved schedule, number of microbatches in pipeline can be less than pp_size,
# so discount accordingly.
if args.virtual_pipeline_model_parallel_size>0 and args.pipeline_model_parallel_size > 1:
if num_microbatches is not None:
activation_memory *= min(1, num_microbatches / args.pipeline_model_parallel_size)
in_flight_microbatches = min(num_microbatches, args.pipeline_model_parallel_size)
else:
in_flight_microbatches = args.pipeline_model_parallel_size
if verbose:
print(f"Number of in-flight microbatches: {in_flight_microbatches}")
if args.pipeline_model_parallel_size == 1:
# Inputs to output layer and CE loss.
activation_memory += (
args.seq_length
* args.micro_batch_size
* args.hidden_size
* 4
* (1 + (args.padded_vocab_size / args.hidden_size))
)
# Activation memory is partitioned by TP size due to tensor and sequence model parallelism.
return activation_memory / args.tensor_model_parallel_size
def report_theoretical_memory(args, num_microbatches=None, verbose=False):
weight_and_optimizer_memory = (
compute_weight_and_optimizer_memory(args, verbose=verbose) / NUM_BYTES_IN_MEGABYTE
)
# Formulae here assume sequence parallelism and selective activation recomputation.
if not args.sequence_parallel:# or args.recompute_granularity != 'selective':
print(
f"Theoretical memory footprints: weight and optimizer={weight_and_optimizer_memory:.2f} MB"
)
return
activation_memory = (
compute_activation_memory(args, num_microbatches=num_microbatches, verbose=verbose)
/ NUM_BYTES_IN_MEGABYTE
)
total_memory = weight_and_optimizer_memory + activation_memory
# print(
# f"batch:{args.micro_batch_size} Theoretical memory footprints: weight and optimizer={weight_and_optimizer_memory:.2f} MB, "
# f"activation={activation_memory:.2f} MB, total={total_memory:.2f} MB\n"
# )
return weight_and_optimizer_memory,activation_memory,total_memory
class Parameter:
def __init__(self):
self.__dict__['data'] = []
def __setattr__(self, key, value):
if key not in self.keys():
self.data.append([key,value])
else:
if isinstance(value,tuple):
self.data[self.keys().index(key)][1]=value
else:
temp=list(self.data[self.keys().index(key)][1])
temp[0]=value
self.data[self.keys().index(key)][1]=temp
def fullname(self,name):
for k,value in self.data:
if value[1]==name:
return k
raise ValueError(f"{name} not found")
def keys(self):
return [x[0] for x in self.data]
def values(self):
return [x[1] for x in self.data]
def __getattr__(self, key):
if key in self.keys():
return self.values()[self.keys().index(key)][0]
def __getitem__(self, key):
if key in self.keys():
return self.values()[self.keys().index(key)]
def apply_de_change(df0,default_params,changes):
add_rows = changes.get('added_rows')
edited_rows = changes.get('edited_rows')
deleted_rows = changes.get('deleted_rows')
for idx, row in edited_rows.items():
for name, value in row.items():
df0.loc[df0.index[idx], name] = value
df0.drop(df0.index[deleted_rows], inplace=True)
ss = []
has_index = add_rows and '_index' in add_rows[0]
for add_row in add_rows:
if '_index' in add_row:
ss.append(pd.Series(data=add_row, name=add_row.pop('_index')))
else:
ss.append(pd.Series(data=add_row))
df_add = pd.DataFrame(ss)
data= pd.concat([df0, df_add], axis=0) if has_index else pd.concat([df0, df_add], axis=0, ignore_index=True)
keys=data.keys().tolist()
for idx, row in data.iterrows():
for k in keys:
default_params.__setattr__(default_params.fullname(k),row[k])
default_params.weight_and_optimizer_memory,default_params.activation_memory,default_params.total_memory=report_theoretical_memory(default_params)
for k in keys:
data.loc[idx,k]=default_params.__getattr__(default_params.fullname(k))
return data
def data_editor_change(key,default_params,editor_key):
st.session_state[key] = apply_de_change(st.session_state[key],default_params,st.session_state[editor_key])
def df_editor_key(key):
return "llm_table_"+key
def set_customer_style():
#手机上column依然保持在一行,而不是一列
st.write('''<style>
[data-testid="column"] {
width: calc(16.6666% - 1rem) !important;
flex: 1 1 calc(16.6666% - 1rem) !important;
min-width: calc(16.6666% - 1rem) !important;
}
</style>''', unsafe_allow_html=True)
#去掉顶部的padding,使得在手机上的空间更紧致(配合--client.toolbarMode="minimal"使用)
st.write('''<style>
[data-testid="stAppViewBlockContainer"] {
padding: 18px;
}
</style>''', unsafe_allow_html=True)
# 运行命令 streamlit.exe run main.py --client.toolbarMode="minimal"
if __name__ == "__main__":
#初始化默认参数 default_params.变量名=(缺省值,"表格的字段名")
default_params=Parameter()
default_params.name=("Llama-2-13b","Name")
default_params.micro_batch_size=(1,"Batch")
default_params.seq_length=(512,"SEQ")
default_params.padded_vocab_size=(32000,"VOCAB")
default_params.hidden_size=(5120,"HIDDEN")
default_params.ffn_hidden_size=(13824,"FFN")
default_params.kv_channels=(0,"KVC")
default_params.num_attention_heads=(40,"HEAD")
default_params.num_query_groups=(0,"QG")
default_params.num_layers=(40,"LAYER")
default_params.num_experts=(1,"MOE")
default_params.virtual_pipeline_model_parallel_size=(1,"VP")
default_params.pipeline_model_parallel_size=(1,"PP")
default_params.tensor_model_parallel_size=(1,"TP")
default_params.data_parallel_size=(1,"DP")
default_params.use_distributed_optimizer=(False,"DOPT")
default_params.group_query_attention=(False,"GQA")
default_params.sequence_parallel=(True,"SP")
default_params.swiglu=(True,"SWIGGLU")
default_params.untie_embeddings_and_output_weights=(False,"UNTIE")
#用默认参数,计算内存占用量
v1,v2,v3=report_theoretical_memory(default_params)
default_params.weight_and_optimizer_memory=(v1,"权值优化器(GB)")
default_params.activation_memory=(v2,"激活(GB)")
default_params.total_memory=(v3,"总计(GB)")
#创建DataFrame并根据字段的数据类型,创建column配置
column_config={}
default_data=OrderedDict()
for fullname,v in zip(default_params.keys(),default_params.values()):
default_value,shortname=v
default_data[shortname]=default_value
value_class_name=default_value.__class__.__name__
if value_class_name=="bool":
column_config[shortname]=st.column_config.CheckboxColumn(shortname,help=fullname,default=default_value)
elif value_class_name=="str":
column_config[shortname]=st.column_config.TextColumn(shortname,help=fullname,default=default_value,validate="^st\.[a-z_]+$")
elif value_class_name=="int":
column_config[shortname]=st.column_config.NumberColumn(shortname,help=fullname,default=default_value,format="%d")
elif value_class_name=="float":
column_config[shortname]=st.column_config.NumberColumn(shortname,help=fullname,default=default_value,format="%.3f")
else:
raise ValueError(f"{value_class_name} not supported")
#赋值给session_state
df_default_key = 'llm_table'
df_editor_key="llm_table_edit"
if df_default_key not in st.session_state:
st.session_state[df_default_key] = pd.DataFrame([default_data])
st.set_page_config(page_title="LLM内存计算", layout="wide")
set_customer_style()
st.markdown("<h1 style='text-align: center; color: black;'>LLM内存计算</h1>", unsafe_allow_html=True)
chart_df=st.data_editor(
st.session_state[df_default_key].copy(),
key=df_editor_key,
on_change=data_editor_change,
args=(df_default_key,default_params,df_editor_key),
height=400,
num_rows="dynamic",
column_config=column_config,
disabled=["权值优化器(GB)","激活(GB)","总计(GB)","SP"],
hide_index=False,
use_container_width=True)
三.运行命令
streamlit.exe run main.py --client.toolbarMode="minimal"



























![Vue3[黑马笔记]未完待续](https://img-blog.csdnimg.cn/direct/d9313ece4ce04452886d12fa6d63dccf.png#pic_center)