from transformers import AutoTokenizer
#加载编码器
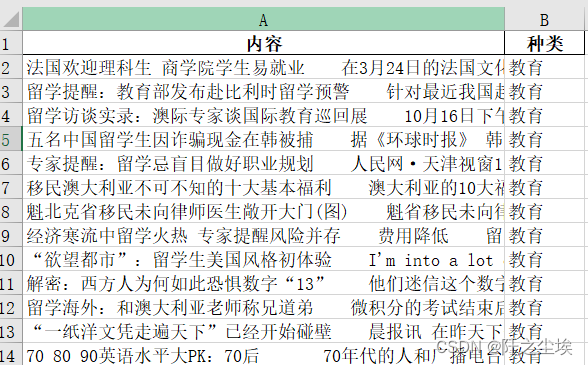
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased',
use_fast=True)
print(tokenizer)
#编码试算
tokenizer.batch_encode_plus([
'hide new secretions from the parental units',
'contains no wit , only labored gags'
])
from transformers import AutoTokenizer
#加载编码器
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased',
use_fast=True)
print(tokenizer)
#编码试算
tokenizer.batch_encode_plus([
'hide new secretions from the parental units',
'contains no wit , only labored gags'
])
from datasets import load_dataset, load_from_disk
#加载数据
dataset = load_dataset(path='glue', name='cola')
# dataset = load_from_disk('datas/glue/cola')
#分词,同时删除多余的字段
def f(examples):
return tokenizer.batch_encode_plus(examples['sentence'], truncation=True)
dataset = dataset.map(function=f,
batched=True,
batch_size=1000,
num_proc=4,
remove_columns=['sentence', 'idx'])
print(dataset['train'][0])
dataset
{'label': 1, 'input_ids': [101, 2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'attention_mask'],
num_rows: 8551
})
validation: Dataset({
features: ['label', 'input_ids', 'attention_mask'],
num_rows: 1043
})
test: Dataset({
features: ['label', 'input_ids', 'attention_mask'],
num_rows: 1063
})
})
import torch
from transformers.data.data_collator import DataCollatorWithPadding
#数据加载器
loader = torch.utils.data.DataLoader(
dataset=dataset['train'],
batch_size=8,
collate_fn=DataCollatorWithPadding(tokenizer),
shuffle=True,
drop_last=True,
)
for i, data in enumerate(loader):
break
for k, v in data.items():
print(k, v.shape, v[:3])
len(loader)
)
for i, data in enumerate(loader):
break
for k, v in data.items():
print(k, v.shape, v[:3])
len(loader)
You're using a DistilBertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
input_ids torch.Size([8, 11]) tensor([[ 101, 2008, 4463, 3369, 1999, 27942, 15070, 19960, 5243, 1012,
102],
[ 101, 2198, 2913, 5362, 2845, 1012, 102, 0, 0, 0,
0],
[ 101, 3021, 7777, 2841, 1012, 102, 0, 0, 0, 0,
0]])
attention_mask torch.Size([8, 11]) tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]])
labels torch.Size([8]) tensor([1, 0, 0])
1068
from transformers import AutoModelForSequenceClassification, DistilBertModel
#加载模型
#model = AutoModelForSequenceClassification.from_pretrained('distilbert-base-uncased', num_labels=2)
#定义下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.pretrained = DistilBertModel.from_pretrained(
'distilbert-base-uncased')
self.fc = torch.nn.Sequential(torch.nn.Linear(768, 768),
torch.nn.ReLU(), torch.nn.Dropout(p=0.2),
torch.nn.Linear(768, 2))
#加载预训练模型的参数
parameters = AutoModelForSequenceClassification.from_pretrained(
'distilbert-base-uncased', num_labels=2)
self.fc[0].load_state_dict(parameters.pre_classifier.state_dict())
self.fc[3].load_state_dict(parameters.classifier.state_dict())
self.criterion = torch.nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask, labels=None):
logits = self.pretrained(input_ids=input_ids,
attention_mask=attention_mask)
logits = logits.last_hidden_state[:, 0]
logits = self.fc(logits)
loss = None
if labels is not None:
loss = self.criterion(logits, labels)
return {'loss': loss, 'logits': logits}
model = Model()
#统计参数量
print(sum(i.numel() for i in model.parameters()) / 10000)
out = model(**data) # 6695.501
out['loss'], out['logits'].shape
# (tensor(0.6801, grad_fn=<NllLossBackward0>), torch.Size([8, 2]))
from datasets import load_metric
#加载评价函数
metric = load_metric(path='glue', config_name='cola')
#试算
metric.compute(predictions=[0, 1, 1, 0], references=[0, 1, 1, 1])
<ipython-input-7-242a384a3976>:4: FutureWarning: load_metric is deprecated and will be removed in the next major version of datasets. Use 'evaluate.load' instead, from the new library 🤗 Evaluate: https://huggingface.co/docs/evaluate
metric = load_metric(path='glue', config_name='cola')
Using the latest cached version of the module from /home/xx/.cache/huggingface/modules/datasets_modules/metrics/glue/91f3cfc5498873918ecf119dbf806fb10815786c84f41b85a5d3c47c1519b343 (last modified on Thu Dec 1 08:29:49 2022) since it couldn't be found locally at glue, or remotely on the Hugging Face Hub.
{'matthews_correlation': 0.5773502691896258}
测试
#测试
def test():
model.eval()
#数据加载器
loader_test = torch.utils.data.DataLoader(
dataset=dataset['validation'],
batch_size=16,
collate_fn=DataCollatorWithPadding(tokenizer),
shuffle=True,
drop_last=True,
)
outs = []
labels = []
for i, data in enumerate(loader_test):
#计算
with torch.no_grad():
out = model(**data)
outs.append(out['logits'].argmax(dim=1))
labels.append(data['labels'])
if i % 10 == 0:
print(i)
if i == 50:
break
outs = torch.cat(outs)
labels = torch.cat(labels)
accuracy = (outs == labels).sum().item() / len(labels)
metric_out = metric.compute(predictions=outs, references=labels)
print(accuracy, metric_out)
test()
0
10
20
30
40
50
0.3002450980392157 {'matthews_correlation': 0.0}
/home/newtranx/anaconda3/lib/python3.8/site-packages/sklearn/metrics/_classification.py:870: RuntimeWarning: invalid value encountered in double_scalars
mcc = cov_ytyp / np.sqrt(cov_ytyt * cov_ypyp)
训练
from transformers import AdamW
from transformers.optimization import get_scheduler
#训练
def train():
optimizer = AdamW(model.parameters(), lr=2e-5)
scheduler = get_scheduler(name='linear',
num_warmup_steps=0,
num_training_steps=len(loader),
optimizer=optimizer)
model.train()
for i, data in enumerate(loader):
out = model(**data)
loss = out['loss']
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad()
if i % 50 == 0:
out = out['logits'].argmax(dim=1)
accuracy = (data['labels'] == out).sum().item() / 8
metric_out = metric.compute(predictions=out,
references=data['labels'])
lr = optimizer.state_dict()['param_groups'][0]['lr']
print(i, loss.item(), accuracy, metric_out, lr)
torch.save(model, 'models/5.分类.model')
train()
调用模型
model = torch.load('models/5.分类.model')
test()
伊织 2022-12-08