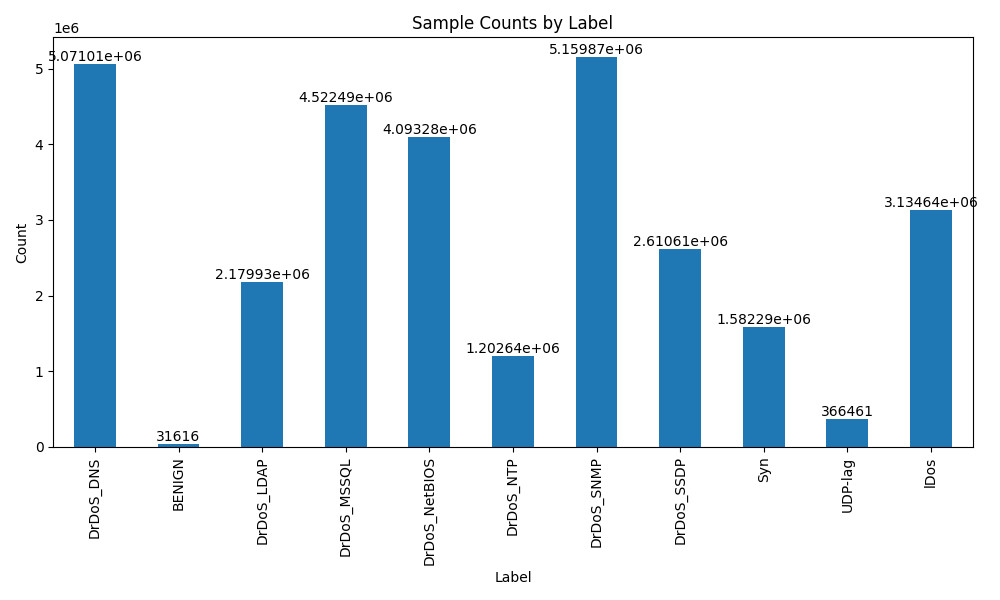
SVM(支持向量机)和随机森林是机器学习中常用的两种算法。
支持向量机是一种监督学习算法,主要用于二分类问题。其基本原理是通过在数据集中找到一个超平面,将两个不同的类别分隔开来。SVM的核心思想是尽可能将超平面与两个类别的样本点之间的间隔最大化,这样可以提高模型的泛化能力。SVM的优点包括:
- 在高维空间中工作效果良好,非线性问题能够通过核技巧转化为线性问题。
- 可以通过设置不同的核函数来适应不同的数据类型。
- SVM对于样本数据维度较高的情况下仍然有很好的表现。
- 可以通过引入惩罚项来防止过拟合。
然而,SVM也有一些缺点:
- SVM对于大规模数据集的训练时间较长。
- 对于数据噪声和缺失值敏感,需要进行额外的数据处理。
- SVM在处理多分类问题时需要进行多个二分类模型的组合。
随机森林是一种集成学习算法,通过构建多个决策树模型来进行分类或回归任务。每个决策树都是在随机选择的数据子集上进行训练,并且通过随机选择属性子集进行分裂。最终的预测结果是基于所有决策树的投票或平均结果。随机森林的优点包括:
- 能够处理高维数据,并且对于特征之间的相关性不敏感。
- 对于异常值和缺失值具有良好的鲁棒性。
- 能够对于拥有大量特征的数据集进行有效的特征选择。
然而,随机森林也有一些缺点:
- 由于每个决策树都是基于随机数据子集进行训练,因此可能会产生过拟合。
- 对于某些噪声较大的数据集,随机森林可能会产生错误的推断。
- 随机森林的模型结构较为复杂,难以解释其中的具体决策过程。
总体而言,SVM适用于处理高维数据集和二分类问题,而随机森林适用于解决多分类和回归问题。具体选择哪种算法取决于问题的性质和数据集的特点。