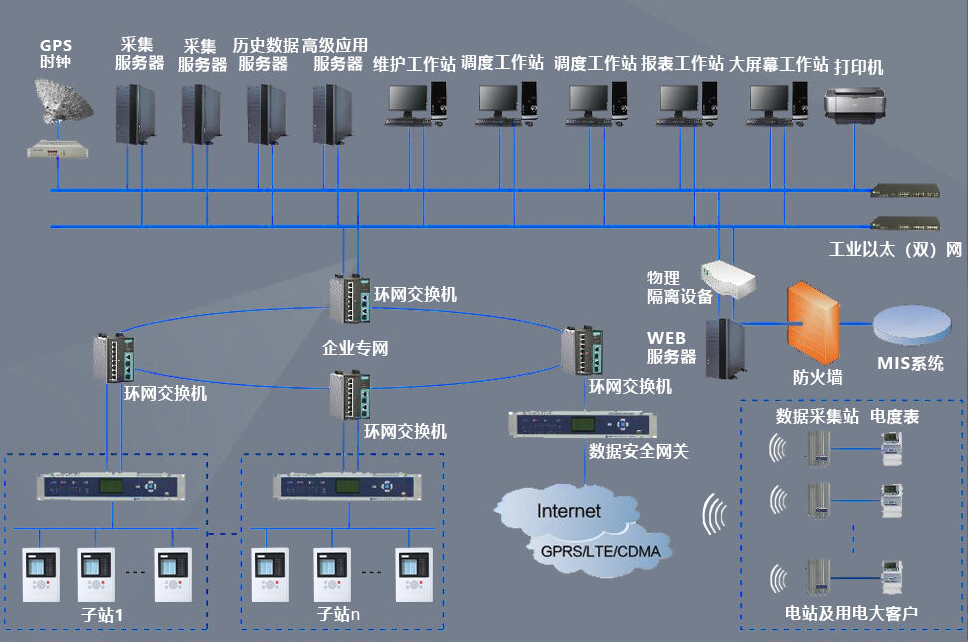
【OpenCompass 大模型评测实战(一期)】:https://www.bilibili.com/video/BV1Gg4y1U7uc/
【视频地址】:https://www.bilibili.com/video/BV1Pm41127jU/
【课程文档】:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md
【课程作业】:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/homework.md
【opencompass】:https://github.com/open-compass/opencompass
【操作平台】:https://studio.intern-ai.org.cn/console/instance/
【自定义客观题数据集】:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_dataset.html
【自定义客观题数据集】:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/subjective_evaluation.html
理论学习
大模型评测
大模型类型:基座模型(base),对话模型(sft,rlhf),公开权重的开源模型,API模型
大模型评测中的挑战:全面性,数据污染,评测成本,鲁棒性
评测类型:客观问答题,客观选择题,开放式主观问答
提示词工程:(下面两幅图很好的示例了很多好的提示词和不好的提示词)


opencompass
100+评测集,50万+题目,工具+基准+榜单
支持功能:单模态,多模态;数据污染检查,长文本能力评测,更丰富的模型推理接入(如lmdeploy),中英文双语主观评测
评测流水线:任意模型+100万多数据集+任务切分+多种输出方案
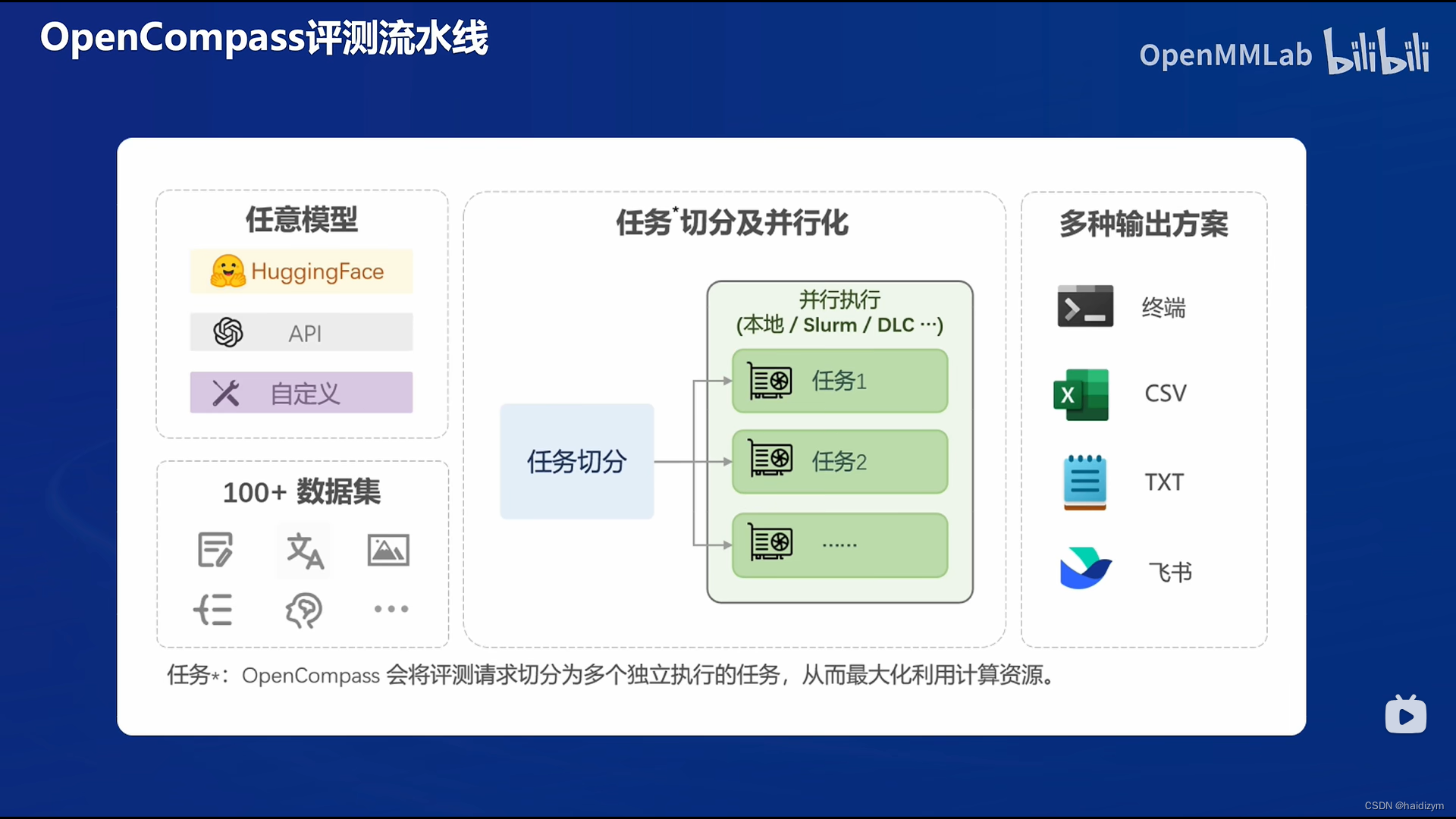
compassKit:大模型评测全栈工具链
多模态评测工具:VLMEvalKit
代码评测工具:Code-Evaluator
MOE模型入门工具:MixtralKit

能力维度:

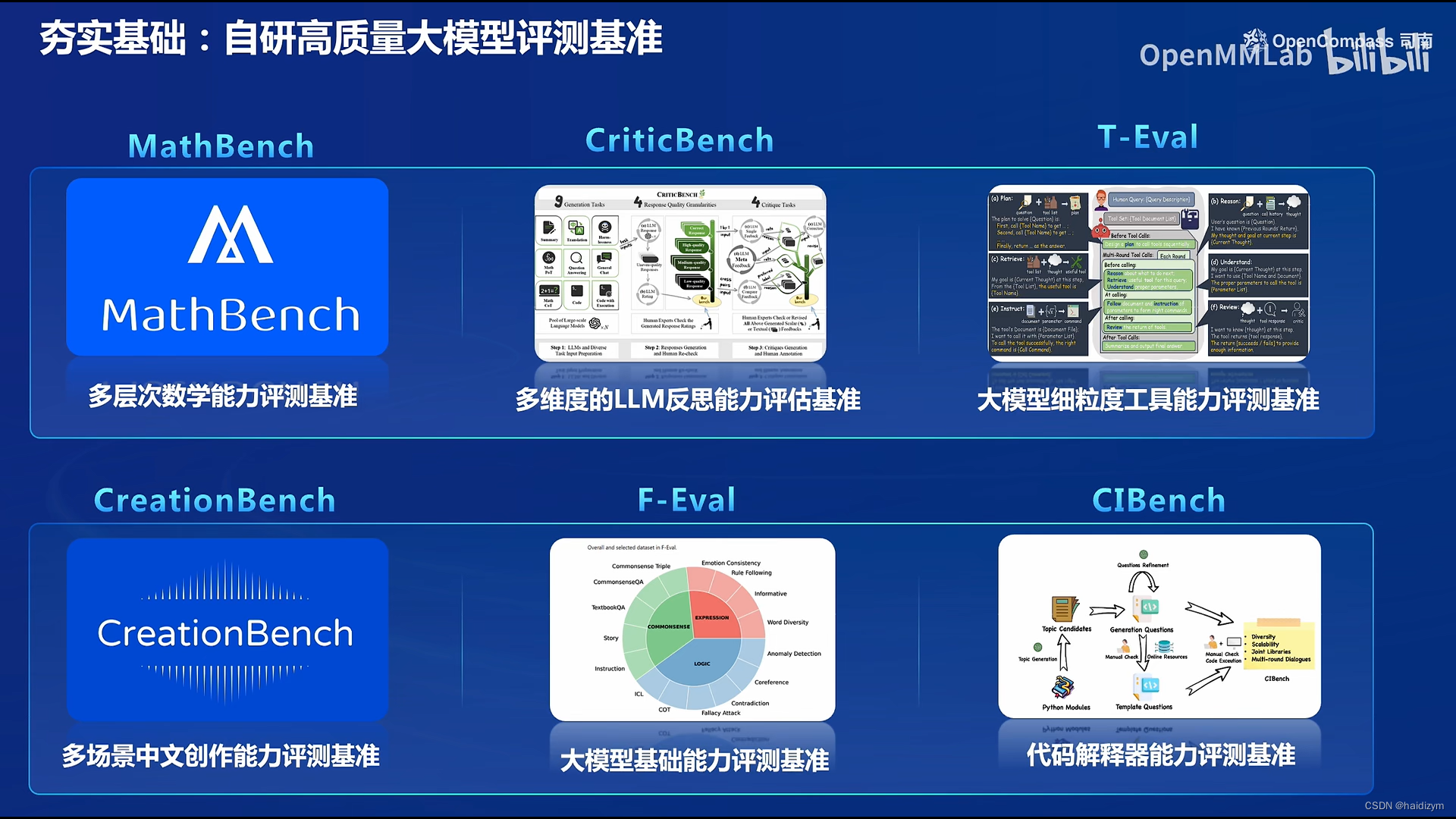
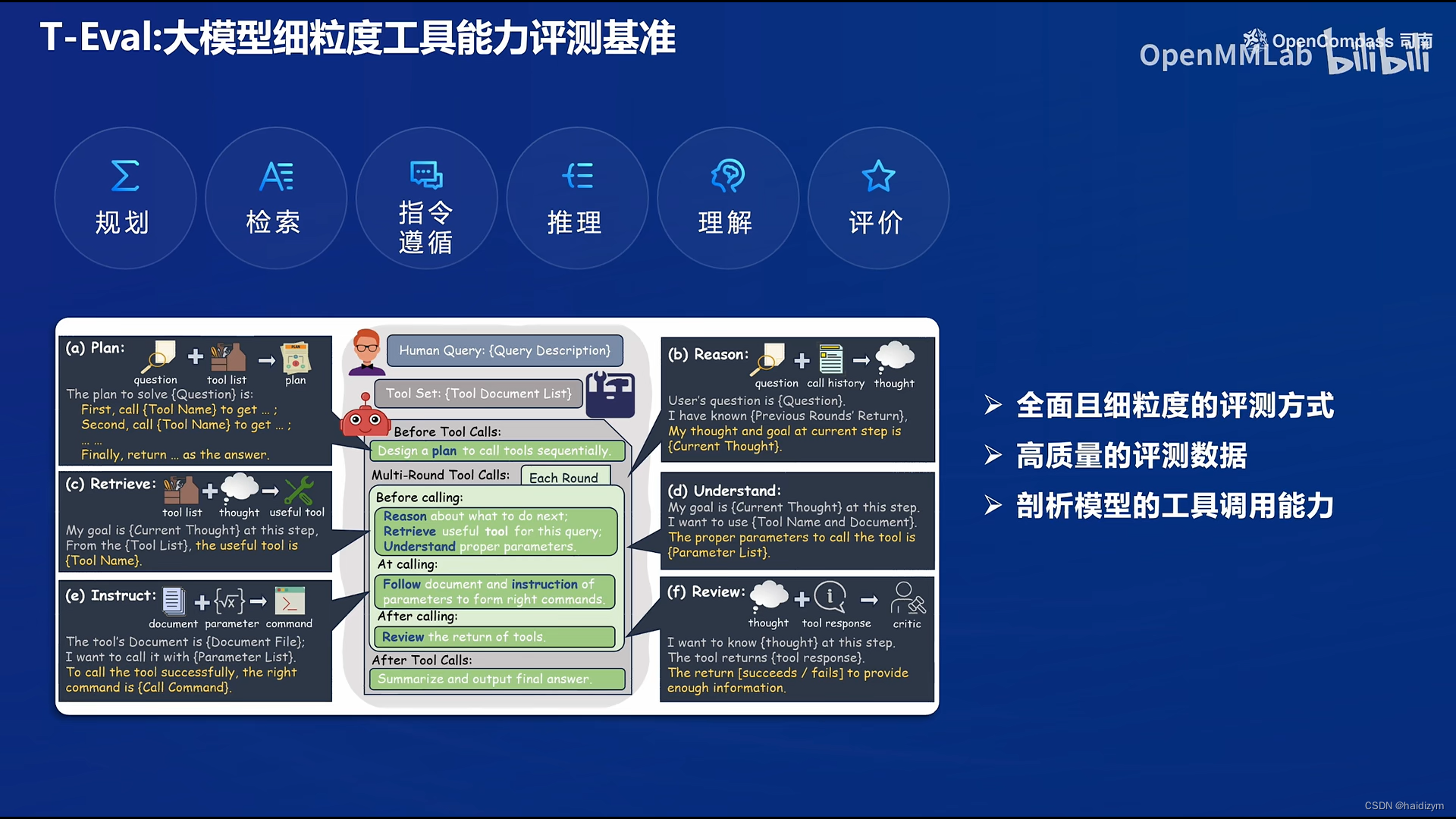
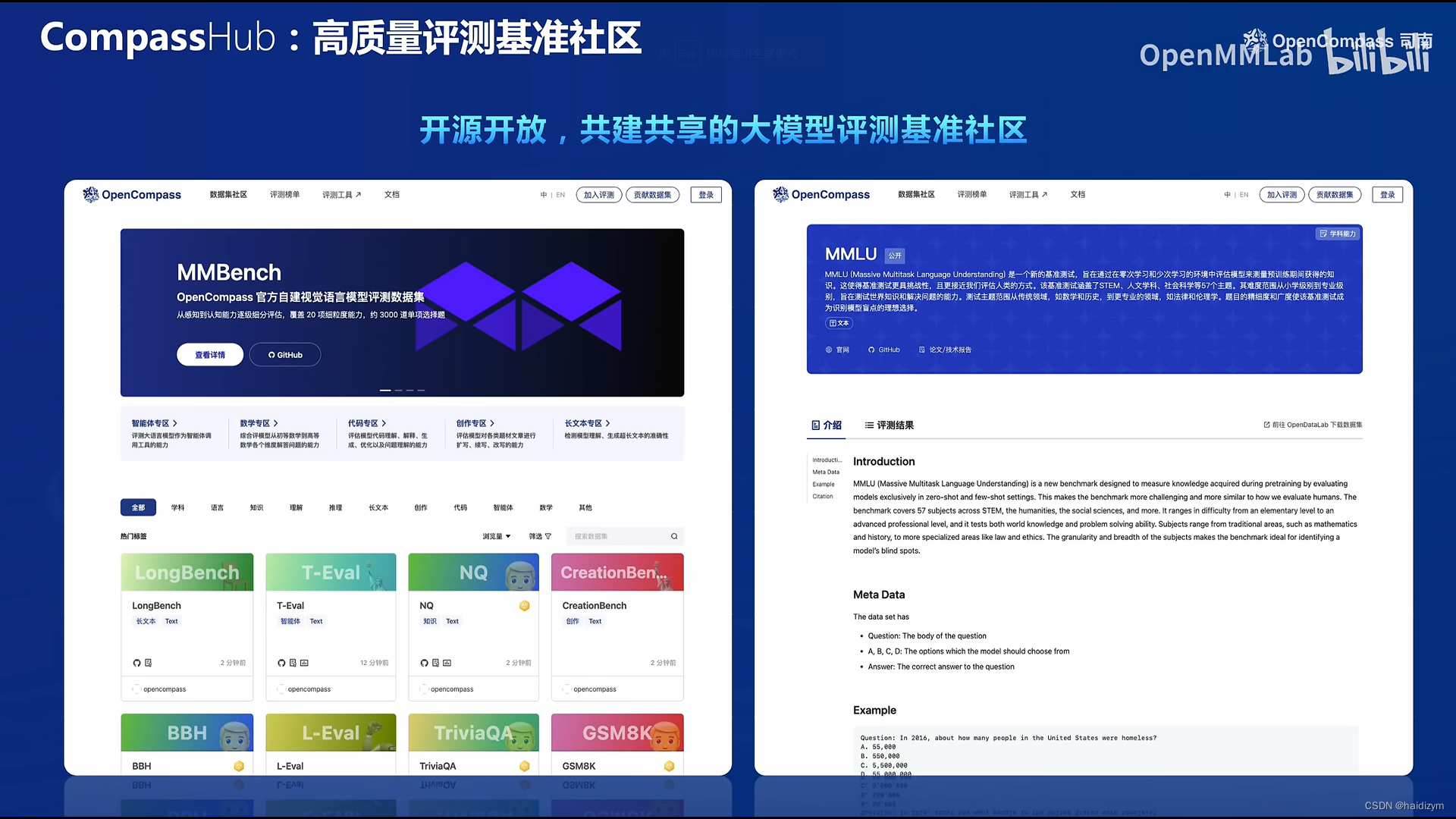
自研高质量大模型评测基准:
代码实战
资源准备
cd ~
studio-conda -o internlm-base -t opencompass
source activate opencompass
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -r requirements.txt
pip install -e .
pip install protobuf
export MKL_SERVICE_FORCE_INTEL=1
#评测数据集下载
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
#列出所有跟 InternLM 及 C-Eval 相关的配置
python tools/list_configs.py internlm ceval
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
启动评测
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 --debug
#python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
命令解析
python run.py
--datasets ceval_gen \
--hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
--tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 1024 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
自定义客观数据集
【自定义客观题数据集】:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_dataset.html
除了数据集本身,需要新建或修改三个文件:
Configs–append评测
Configs–》datasets:新建ceval_gen_5f30c7.py文件–》实现返回一个list,包含如下字段type,path,name,reader_cfg,infer_cfg,eval_cfg,
Opencompass–load数据
Opencompass–》datasets–》新建ceval.py文件–》实现评测数据集加载,返回一个CEvalDataset序列,格式:[{k,v},{},{}]
导入_init_.py–import数据集
Opencompass–》datasets–》在_init_.py文件里新加:from .ceval import *
自定义客观评测题数据集案例示范(单选题)
Configs–append评测
from opencompass.openicl.icl_prompt_template import PromptTemplate
from opencompass.openicl.icl_retriever import FixKRetriever
from opencompass.openicl.icl_inferencer import GenInferencer
from opencompass.openicl.icl_evaluator import AccEvaluator
from opencompass.datasets import CEvalDataset
from opencompass.utils.text_postprocessors import first_capital_postprocess
ceval_subject_mapping = {
'computer_network': ['Computer Network', '计算机网络', 'STEM'],
'operating_system': ['Operating System', '操作系统', 'STEM'],
'computer_architecture': ['Computer Architecture', '计算机组成', 'STEM'],
'college_programming': ['College Programming', '大学编程', 'STEM'],
'college_physics': ['College Physics', '大学物理', 'STEM'],
'college_chemistry': ['College Chemistry', '大学化学', 'STEM'],
'advanced_mathematics': ['Advanced Mathematics', '高等数学', 'STEM'],
'probability_and_statistics': ['Probability and Statistics', '概率统计', 'STEM'],
'discrete_mathematics': ['Discrete Mathematics', '离散数学', 'STEM'],
'electrical_engineer': ['Electrical Engineer', '注册电气工程师', 'STEM'],
'metrology_engineer': ['Metrology Engineer', '注册计量师', 'STEM'],
'high_school_mathematics': ['High School Mathematics', '高中数学', 'STEM'],
'high_school_physics': ['High School Physics', '高中物理', 'STEM'],
'high_school_chemistry': ['High School Chemistry', '高中化学', 'STEM'],
'high_school_biology': ['High School Biology', '高中生物', 'STEM'],
'middle_school_mathematics': ['Middle School Mathematics', '初中数学', 'STEM'],
'middle_school_biology': ['Middle School Biology', '初中生物', 'STEM'],
'middle_school_physics': ['Middle School Physics', '初中物理', 'STEM'],
'middle_school_chemistry': ['Middle School Chemistry', '初中化学', 'STEM'],
'veterinary_medicine': ['Veterinary Medicine', '兽医学', 'STEM'],
'college_economics': ['College Economics', '大学经济学', 'Social Science'],
'business_administration': ['Business Administration', '工商管理', 'Social Science'],
'marxism': ['Marxism', '马克思主义基本原理', 'Social Science'],
'mao_zedong_thought': ['Mao Zedong Thought', '毛泽东思想和中国特色社会主义理论体系概论', 'Social Science'],
'education_science': ['Education Science', '教育学', 'Social Science'],
'teacher_qualification': ['Teacher Qualification', '教师资格', 'Social Science'],
'high_school_politics': ['High School Politics', '高中政治', 'Social Science'],
'high_school_geography': ['High School Geography', '高中地理', 'Social Science'],
'middle_school_politics': ['Middle School Politics', '初中政治', 'Social Science'],
'middle_school_geography': ['Middle School Geography', '初中地理', 'Social Science'],
'modern_chinese_history': ['Modern Chinese History', '近代史纲要', 'Humanities'],
'ideological_and_moral_cultivation': ['Ideological and Moral Cultivation', '思想道德修养与法律基础', 'Humanities'],
'logic': ['Logic', '逻辑学', 'Humanities'],
'law': ['Law', '法学', 'Humanities'],
'chinese_language_and_literature': ['Chinese Language and Literature', '中国语言文学', 'Humanities'],
'art_studies': ['Art Studies', '艺术学', 'Humanities'],
'professional_tour_guide': ['Professional Tour Guide', '导游资格', 'Humanities'],
'legal_professional': ['Legal Professional', '法律职业资格', 'Humanities'],
'high_school_chinese': ['High School Chinese', '高中语文', 'Humanities'],
'high_school_history': ['High School History', '高中历史', 'Humanities'],
'middle_school_history': ['Middle School History', '初中历史', 'Humanities'],
'civil_servant': ['Civil Servant', '公务员', 'Other'],
'sports_science': ['Sports Science', '体育学', 'Other'],
'plant_protection': ['Plant Protection', '植物保护', 'Other'],
'basic_medicine': ['Basic Medicine', '基础医学', 'Other'],
'clinical_medicine': ['Clinical Medicine', '临床医学', 'Other'],
'urban_and_rural_planner': ['Urban and Rural Planner', '注册城乡规划师', 'Other'],
'accountant': ['Accountant', '注册会计师', 'Other'],
'fire_engineer': ['Fire Engineer', '注册消防工程师', 'Other'],
'environmental_impact_assessment_engineer': ['Environmental Impact Assessment Engineer', '环境影响评价工程师', 'Other'],
'tax_accountant': ['Tax Accountant', '税务师', 'Other'],
'physician': ['Physician', '医师资格', 'Other'],
}
ceval_all_sets = list(ceval_subject_mapping.keys())
ceval_datasets = []
for _split in ["val"]:
for _name in ceval_all_sets:
_ch_name = ceval_subject_mapping[_name][1]
ceval_infer_cfg = dict(
ice_template=dict(
type=PromptTemplate,
template=dict(
begin="</E>",
round=[
dict(
role="HUMAN",
prompt=
f"以下是中国关于{_ch_name}考试的单项选择题,请选出其中的正确答案。\n{{question}}\nA. {{A}}\nB. {{B}}\nC. {{C}}\nD. {{D}}\n答案: "
),
dict(role="BOT", prompt="{answer}"),
]),
ice_token="</E>",
),
retriever=dict(type=FixKRetriever, fix_id_list=[0, 1, 2, 3, 4]),
inferencer=dict(type=GenInferencer),
)
ceval_eval_cfg = dict(
evaluator=dict(type=AccEvaluator),
pred_postprocessor=dict(type=first_capital_postprocess))
ceval_datasets.append(
dict(
type=CEvalDataset,
path="./data/ceval/formal_ceval",
name=_name,
abbr="ceval-" + _name if _split == "val" else "ceval-test-" +
_name,
reader_cfg=dict(
input_columns=["question", "A", "B", "C", "D"],
output_column="answer",
train_split="dev",
test_split=_split),
infer_cfg=ceval_infer_cfg,
eval_cfg=ceval_eval_cfg,
))
del _split, _name, _ch_name
Opencompass–load数据
import csv
import json
import os.path as osp
from datasets import Dataset, DatasetDict
from opencompass.registry import LOAD_DATASET
from .base import BaseDataset
@LOAD_DATASET.register_module()
class CEvalDataset(BaseDataset):
@staticmethod
def load(path: str, name: str):
dataset = {}
for split in ['dev', 'val', 'test']:
filename = osp.join(path, split, f'{name}_{split}.csv')
with open(filename, encoding='utf-8') as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
item = dict(zip(header, row))
item.setdefault('explanation', '')
item.setdefault('answer', '')
dataset.setdefault(split, []).append(item)
dataset = {i: Dataset.from_list(dataset[i]) for i in dataset}
return DatasetDict(dataset)
class CEvalDatasetClean(BaseDataset):
# load the contamination annotations of CEval from
# https://github.com/liyucheng09/Contamination_Detector
@staticmethod
def load_contamination_annotations(path, split='val'):
import requests
assert split == 'val', 'Now we only have annotations for val set'
annotation_cache_path = osp.join(
path, split, 'ceval_contamination_annotations.json')
if osp.exists(annotation_cache_path):
with open(annotation_cache_path, 'r') as f:
annotations = json.load(f)
return annotations
link_of_annotations = 'https://github.com/liyucheng09/Contamination_Detector/releases/download/v0.1.1rc/ceval_annotations.json' # noqa
annotations = json.loads(requests.get(link_of_annotations).text)
with open(annotation_cache_path, 'w') as f:
json.dump(annotations, f)
return annotations
@staticmethod
def load(path: str, name: str):
dataset = {}
for split in ['dev', 'val', 'test']:
if split == 'val':
annotations = CEvalDatasetClean.load_contamination_annotations(
path, split)
filename = osp.join(path, split, f'{name}_{split}.csv')
with open(filename, encoding='utf-8') as f:
reader = csv.reader(f)
header = next(reader)
for row_index, row in enumerate(reader):
item = dict(zip(header, row))
item.setdefault('explanation', '')
item.setdefault('answer', '')
if split == 'val':
row_id = f'{name}-{row_index}'
if row_id in annotations:
item['is_clean'] = annotations[row_id][0]
else:
item['is_clean'] = 'not labeled'
dataset.setdefault(split, []).append(item)
dataset = {i: Dataset.from_list(dataset[i]) for i in dataset}
return DatasetDict(dataset)
导入_init_.py–import数据集
from .advglue import * # noqa: F401, F403
from .afqmcd import * # noqa: F401, F403
from .agieval import * # noqa: F401, F403
from .anli import AnliDataset # noqa: F401, F403
from .anthropics_evals import * # noqa: F401, F403
from .apps import * # noqa: F401, F403
from .arc import * # noqa: F401, F403
from .ax import * # noqa: F401, F403
from .bbh import * # noqa: F401, F403
from .boolq import * # noqa: F401, F403
from .bustum import * # noqa: F401, F403
from .c3 import * # noqa: F401, F403
from .cb import * # noqa: F401, F403
from .ceval import * # noqa: F401, F403
from .chid import * # noqa: F401, F403
from .cibench import * # noqa: F401, F403
from .circular import * # noqa: F401, F403
from .civilcomments import * # noqa: F401, F403
from .clozeTest_maxmin import * # noqa: F401, F403
from .cluewsc import * # noqa: F401, F403
from .cmb import * # noqa: F401, F403
from .cmmlu import * # noqa: F401, F403
from .cmnli import * # noqa: F401, F403
from .cmrc import * # noqa: F401, F403
from .commonsenseqa import * # noqa: F401, F403
from .commonsenseqa_cn import * # noqa: F401, F403
from .copa import * # noqa: F401, F403
from .crowspairs import * # noqa: F401, F403
from .crowspairs_cn import * # noqa: F401, F403
from .csl import * # noqa: F401, F403
from .custom import * # noqa: F401, F403
from .cvalues import * # noqa: F401, F403
from .drcd import * # noqa: F401, F403
from .drop import * # noqa: F401, F403
from .ds1000 import * # noqa: F401, F403
from .ds1000_interpreter import * # noqa: F401, F403
from .eprstmt import * # noqa: F401, F403
from .FinanceIQ import * # noqa: F401, F403
from .flores import * # noqa: F401, F403
from .game24 import * # noqa: F401, F403
from .GaokaoBench import * # noqa: F401, F403
from .govrepcrs import * # noqa: F401, F403
from .gpqa import * # noqa: F401, F403
from .gsm8k import * # noqa: F401, F403
from .gsm_hard import * # noqa: F401, F403
from .hellaswag import * # noqa: F401, F403
from .huggingface import * # noqa: F401, F403
from .humaneval import * # noqa: F401, F403
from .humanevalx import * # noqa: F401, F403
from .hungarian_math import * # noqa: F401, F403
from .IFEval.ifeval import IFEvalDataset, IFEvaluator # noqa: F401, F403
from .infinitebench import * # noqa: F401, F403
from .iwslt2017 import * # noqa: F401, F403
from .jigsawmultilingual import * # noqa: F401, F403
from .jsonl import JsonlDataset # noqa: F401, F403
from .kaoshi import KaoshiDataset, KaoshiEvaluator # noqa: F401, F403
from .lambada import * # noqa: F401, F403
from .lawbench import * # noqa: F401, F403
from .lcsts import * # noqa: F401, F403
from .leval import * # noqa: F401, F403
from .longbench import * # noqa: F401, F403
from .lveval import * # noqa: F401, F403
from .mastermath2024v1 import * # noqa: F401, F403
from .math import * # noqa: F401, F403
from .math401 import * # noqa: F401, F403
from .math_intern import * # noqa: F401, F403
from .mathbench import * # noqa: F401, F403
from .mbpp import * # noqa: F401, F403
from .medbench import * # noqa: F401, F403
from .mmlu import * # noqa: F401, F403
from .multirc import * # noqa: F401, F403
from .narrativeqa import * # noqa: F401, F403
from .natural_question import * # noqa: F401, F403
from .natural_question_cn import * # noqa: F401, F403
from .NPHardEval import * # noqa: F401, F403
from .obqa import * # noqa: F401, F403
from .OpenFinData import * # noqa: F401, F403
from .piqa import * # noqa: F401, F403
from .py150 import * # noqa: F401, F403
from .qasper import * # noqa: F401, F403
from .qaspercut import * # noqa: F401, F403
from .QuALITY import * # noqa: F401, F403
from .race import * # noqa: F401, F403
from .realtoxicprompts import * # noqa: F401, F403
from .reasonbench import ReasonBenchDataset # noqa: F401, F403
from .record import * # noqa: F401, F403
from .safety import * # noqa: F401, F403
from .scibench import ScibenchDataset, scibench_postprocess # noqa: F401, F403
from .siqa import * # noqa: F401, F403
from .squad20 import SQuAD20Dataset, SQuAD20Evaluator # noqa: F401, F403
from .storycloze import * # noqa: F401, F403
from .strategyqa import * # noqa: F401, F403
from .subjective import * # noqa: F401, F403
from .summedits import * # noqa: F401, F403
from .summscreen import * # noqa: F401, F403
from .svamp import * # noqa: F401, F403
from .tabmwp import * # noqa: F401, F403
from .taco import * # noqa: F401, F403
from .teval import * # noqa: F401, F403
from .TheoremQA import * # noqa: F401, F403
from .tnews import * # noqa: F401, F403
from .triviaqa import * # noqa: F401, F403
from .triviaqarc import * # noqa: F401, F403
from .truthfulqa import * # noqa: F401, F403
from .tydiqa import * # noqa: F401, F403
from .wic import * # noqa: F401, F403
from .wikibench import * # noqa: F401, F403
from .winograd import * # noqa: F401, F403
from .winogrande import * # noqa: F401, F403
from .wnli import wnliDataset # noqa: F401, F403
from .wsc import * # noqa: F401, F403
from .xcopa import * # noqa: F401, F403
from .xiezhi import XiezhiDataset, XiezhiRetriever # noqa: F401, F403
from .xlsum import * # noqa: F401, F403
from .xsum import * # noqa: F401, F403
自定义客观评测题数据集案例示范(多选题)
Configs–append评测
在这里插入代码片
Opencompass–load数据
在这里插入代码片
导入_init_.py–import数据集
在这里插入代码片
自定义主观数据集
【自定义客观题数据集】:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/subjective_evaluation.html
(未完待续)
自定义主观评测题数据集案例示范(客观问答)
Configs–append评测
在这里插入代码片
Opencompass–load数据
在这里插入代码片
导入_init_.py–import数据集
在这里插入代码片
自定义主观评测题数据集案例示范(开放问答)
Configs–append评测
在这里插入代码片
Opencompass–load数据
在这里插入代码片
导入_init_.py–import数据集
在这里插入代码片