提到数据库,不可避免的要考虑高可用HA(High Availability)。但是很多人对高可用的理解并不是很透彻。
要搞清高可用需要回答以下几个问题:
- 什么是高可用?
- 为什么需要高可用?
- 高可用需要达到什么样的目标?
- 如何做到高可用?
什么是高可用?
高可用(HA)
高可用通常是指在单个组件出现故障时,整个系统仍可以对外提供服务。因此高可用主要还是针对一个系统而言,而非单独的一个组件(这点非常重要)。
我们通常用一段时间内系统可用时间占比作为高可用的衡量指标。
计算方式如下:
MTBF(Mean Time Between Failure),系统平均正常运行时间
MTTR(Mean Time to Repair),系统平均恢复时间
可用性的计算公式: AVAILABILITY = MTBF / ( MTBF + MTTR ) × 100%
如可用性 99.9%,就意味着该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时【(1-99.9%) x 365 x 24】。
通常提到的可用性指标与允许业务中断时间(1年)如下:
| 可用性指标 | 允许中断时间 |
|---|---|
| 99% | 3.65天 |
| 99.9% | 8.76小时 |
| 99.99% | 52.6分钟 |
| 99.999% | 5.26分钟 |
提到高可用,不可避免要提到RTO和RPO(这两个也是灾备方案的关键指标),高可用方案的选择要基于RTO和RPO。
RTO
RTO,Recovery time objective,恢复时间目标,是指所能容忍的业务系统停止服务的最长时间,也就是灾难发生到业务系统恢复服务功能所需要的最短时间。
RPO
RPO,Recovery point objective,恢复点目标,是指业务系统所能容忍的数据丢失量。
为什么需要高可用?
这个问题最好回答:为了提供持续服务。
但是你的系统真的需要提供持续服务吗?如果服务中断会带来哪些损失呢?
高可用需要达到什么样的目标?
在高可用概念中我们提到了高可用的衡量标准,那么对于一套系统,什么样的标准才是合理的呢?3个9还是4个9?
这需要平衡三个方面:服务中断的损失、方案的预算、技术的可行性。
如何判断标准是否合理?其实只有一个判断条件,预算。
没有预算,什么都是扯淡。
有了预算,那么才能考虑下一步,采用什么高可用方案。
如何做到高可用
在概念中我们提到,高可用是为了保障组件遇到故障时仍可以提供服务。
那么我们需要对故障进行总和分析,对症下药。
数据库故障分类
通常数据库故障可以分为以下几类:
- 硬件故障
- 软件故障
- 误操作
硬件故障
硬件故障时最常见的故障,诸如:网络中断、磁盘损坏、服务器断电等。针对不同的故障,也有成形的解决方案:
- 网络故障–网络设备冗余、多链路、bond
- 磁盘损坏–分布式、RAID
- 服务器断电–UPS、双电源
- 机房爆炸–异地灾备
- 世界毁灭–拜菩萨
软件故障
软件故障通常被忽略,但是也是最棘手的。数据库软件遇到bug,很难通过其他手段快速恢复。
误操作
这类故障时最难防范的。通常需要技术外的手段进行防范,如:安全培训、双人操作、方案审核等。
高可用方案
不管多么高大上的高可用方案,归根到底只有一个方法:冗余。
因此高可用方案都绕不过两个问题:
- 故障发生时,如何快速在冗余系统间切换?切换时间决定了RTO。
- 冗余系统间数据如何保持一致?数据差异决定了RPO。
常见的数据库高可用方案可以分为四种:
- 共享存储
2个或2个以上服务器使用同一个存储(Oracle就是这样实现的),这样就保证了数据的一致性,但是想保证高可用,需要数据库软件支持两个数据库节点通知读写1个存储,否则只能实现主备,RTO会很长。 - 操作系统级别文件复制
共享存储通常需要磁盘阵列来实现,增加了方案整体成本。如果没有磁盘阵列,可以采用折中的方法,使用复制软件(scp/rsync/bbcp)保证服务器间数据的一致性。但这样带来的问题是无法保证两个服务器之前的数据同步的实时性和一致性(一致性可以通过文件校验来实现,但会降低实时性)。 - 数据库级别数据复制
相较于操作系统基本的文件复制,数据库级别的文件复制(如Oracle ADG)更加安全和高效,能够更好的保证数据的一致性,但是同样实时性是一个挑战。 - 数据库集群/分布式数据库
这种方式是数据库软件自身实现的,在保证数据一致性和实时性方面都较以上方案都更高效。但对数据库软件自身的设计也要求更高。
需要注意的是以上所有方案都是用来应对硬件故障,遇到软件故障或误操作通常无能为力。
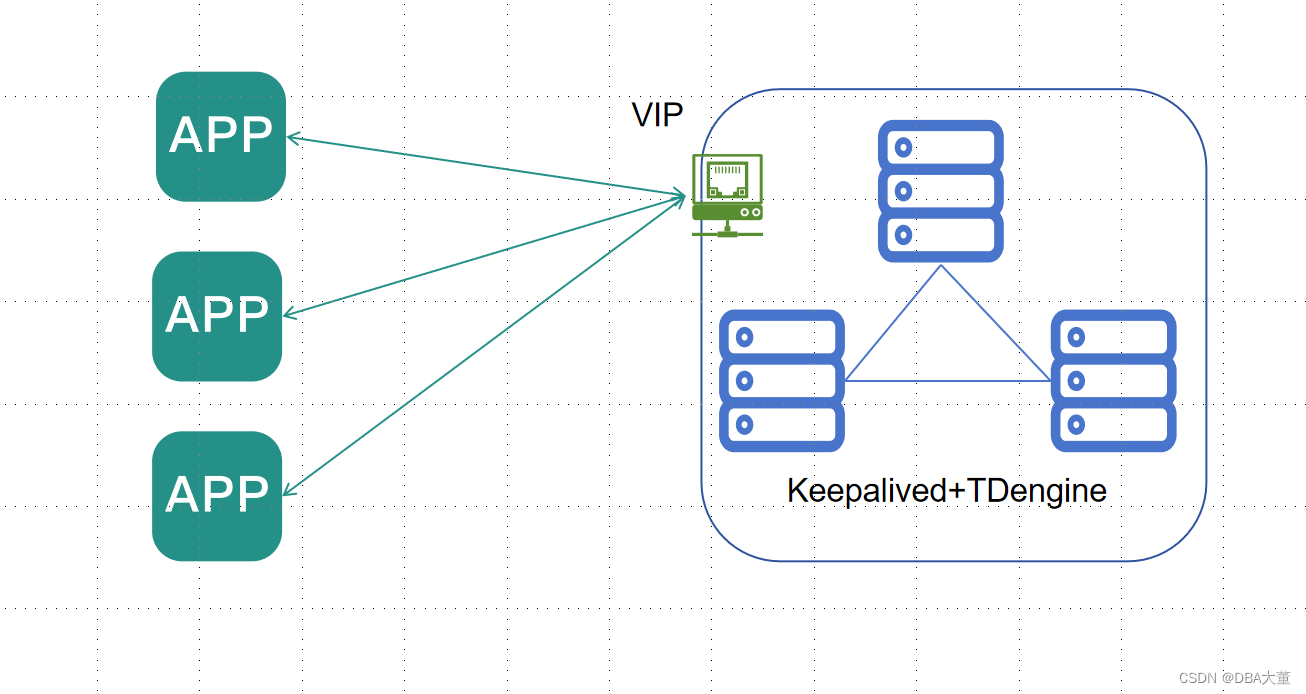
TDengine高可用探讨
TDengine 通过多节点和多副本来提供整个数据库系统可用性。这个方案有如下特点:
- 任何1个节点故障(硬件故障、操作系统故障等非数据库软件故障)时,整个系统仍可以对外提供服务,且数据不会有任何损失。RPO=0
- 任何1个节点故障时,对客户端几乎时无感知的。RTO=0
以上方案可以应对硬件故障、操作系统故障(也不是绝对),但是当网络故障或数据库软件自身出bug时就无能为力了。
那么应该采用什么方案才能提高可用性呢?
冗余,增加冗余!!

- 部署2套TDengine集群,集群间进行数据同步。
- 前端部署负载均衡集群,当节点或集群故障时进行切换。
这个方案存在以下优缺点:
优点:
- 同步部署两套集群,可以规避绝大部分硬件故障。如果异地部署,设置可以规避机房级别的故障。
- 所有访问通过负载均衡进行反向代理,节点故障/集群切换时,对应用而言无需做任何变更,甚至是无感知的。
缺点:
- 目前可以使用订阅来实现数据的单向同步,但无法实现双向。因此当由集群1切换到集群2后,需要手动修改订阅,才能保证两个集群间数据一致。
- 集群切换时,Nginx需要手动修改配置。切换过程会造成短时间应用访问异常。
- 预算高。