大数据导论
一、数据导论
数据:一种可以被鉴别的对客观事件进行记录的符号。(对人类的行为及产生的事件的一种记录)
大数据技术栈:对超大规模的数据进行处理并挖掘出数据背后的价值的技术体系。
Q:数据有什么价值?
A:对数据的内容进行深入分析,可以更好的帮助了解事和物在现实世界的运行规律。
二、大数据诞生
分布式处理技术:在数据量巨大的基础下以服务器的数量来解决大规模数据处理问题。
大规模服务器集群下的大规模数据存储/计算/传输技术
Apache Hadoop :一款开源的分布式处理技术栈 为业界提供了:
• 基于Hadoop HDFS的:分布式数据存储技术
• 基于Hadoop MapReduce的:分布式数据计算技术
• 基于Hadoop YARN的:分布式资源调度技术
三、大数据概述
大数据:狭义上:大数据是一类技术栈,是一种用来处理海量数据的软件技术体系。
广义上:大数据是数字化时代、信息化时代的基础(技术)支撑,以数据为生活赋能。
大数据的特征:数量体积大;种类、来源多样化;低价值密度;速度快;数据的质量;
大数据的核心工作:数据存储;数据计算;数据传输
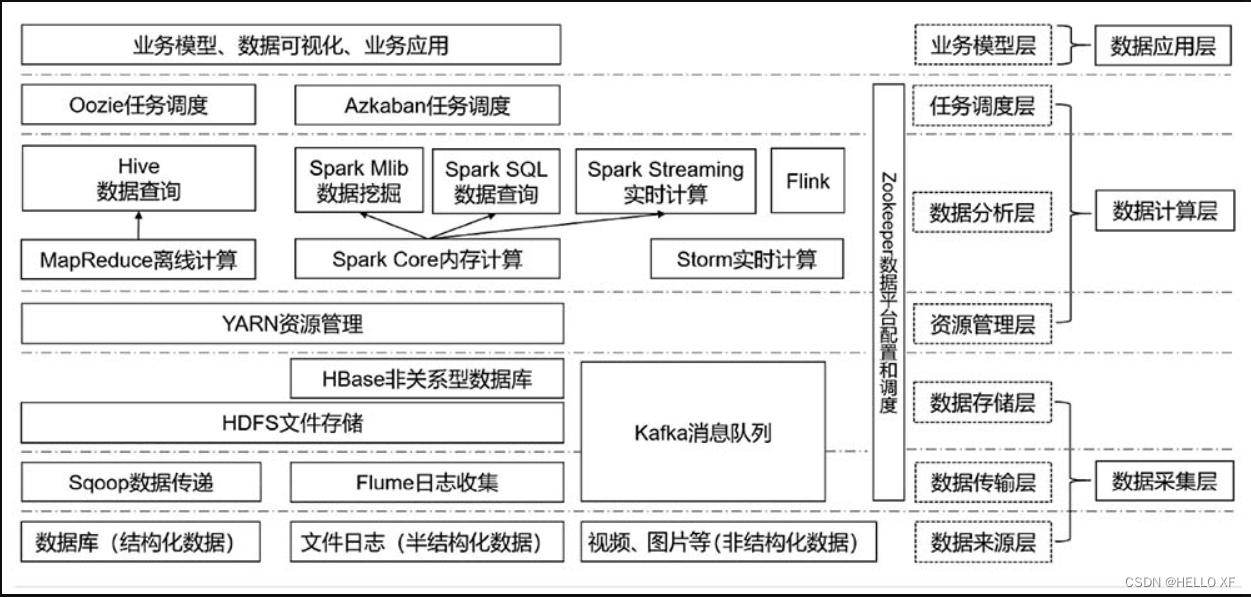
四、大数据软件生态
Apache Hadoop - MapReduce:最早一代的大数据分布式计算引擎
Apache Hive:以SQL为要开发语言的分布式计算框架
Apache Spark:分布式内存计算引擎
Apache Flink:大数据分布式内存计算引擎
Apache Sqoop:一款ETL工具,可以协助大数据体系和关系型数据库 之间进行数据传输。
Apache Flume:是一款流式数据采集工具
Apache Kafka:是一款分布式的消息系统
Apache Pulsar:一款分布式的消息系统
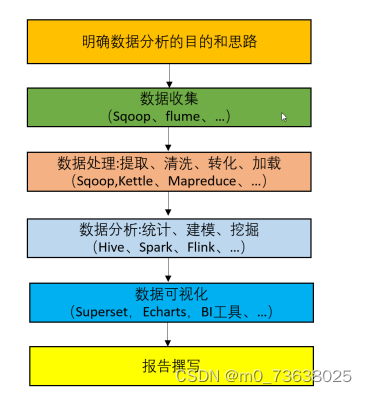
五、大数据的分析步骤
Hadoop入门
一、分布式系统和集群
分布式:是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。
集群:所谓集群是指一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机 联合起来工作(服务),可以是并行的,也可以是做备份。
分布式的调度主要有2类架构模式:
• 去中心化模式:没有明确的中心, 众多服务器之间基于特定规则进行同步协调。
• 中心化模式:有明确的中心。
• Hadoop是主从模式(中心化模式)的架构
二、Hadoop框架概论
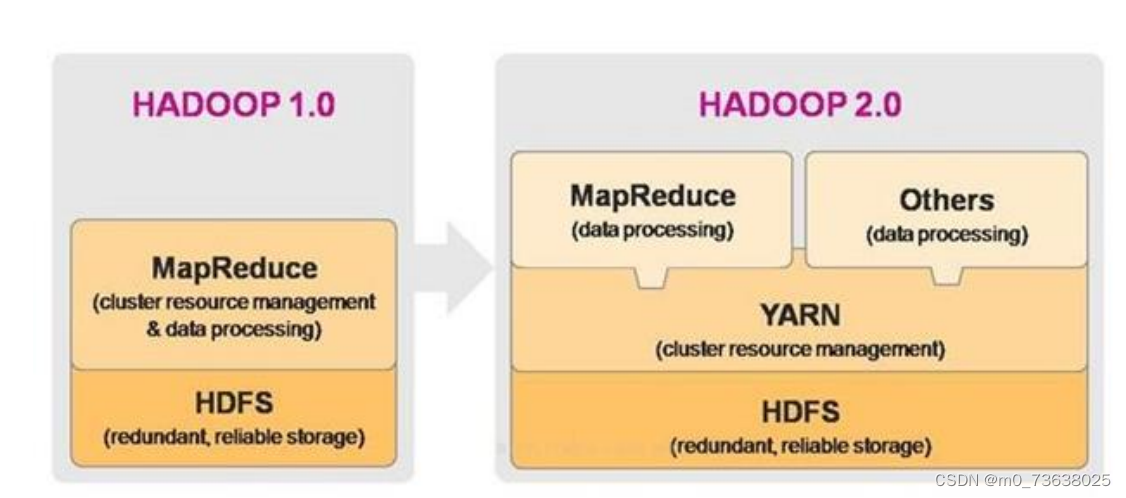
Hadoop是一个集合了:存储、计算、资源调度为一体的大数据分布式框架
Hadoop框架内容:
⚫ 狭义解释
Hadoop指Apache这款开源框架,它的核心组件有:
➢ HDFS(分布式文件系统):解决海量数据存储
➢ MAPREDUCE(分布式运算编程框架):解决海量数据计算
➢ YARN(作业调度和集群资源管理的框架):解决资源任务调度 Hadoop框架内容
⚫ 广义解释
Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
⚫ Hadoop架构模块
⚫ Hadoop2.x架构内部模型-HDFS和Yarn
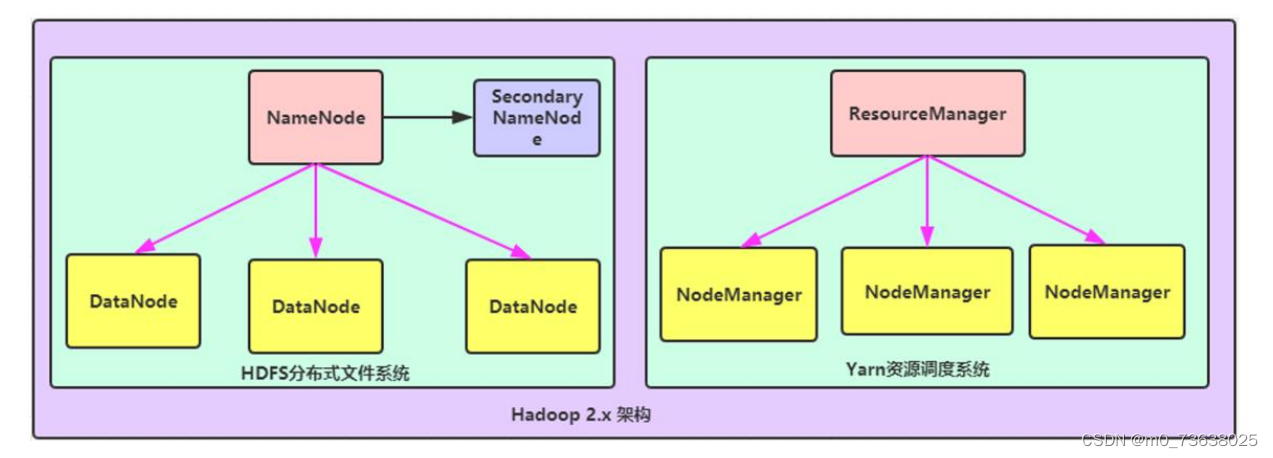
➢ HDFS模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
➢ 数据计算核心模块:
ResourceManager:接收用户的计算请求任务, 并负责集群的资源分配
NodeManager: 负责执行主节点分配的任务
三、HDFS文件系统
特点:
⚫ HDFS文件系统可存储超大文件,时效性稍差。
⚫ HDFS具有硬件故障检测和自动快速恢复功能。
⚫ HDFS为数据存储提供很强的扩展能力。
⚫ HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
⚫ HDFS可在普通廉价的机器上运行。
架构:
⚫ HDFS采用Master/Slave架构
⚫ 一个HDFS集群有两个重要的角色,分别是Namenode和Datanode。
⚫ HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
学习感受:
通过对本节课程的学习使得我对本专业的就业前景和未来职业规划有了更加清晰地定位与认知。更加深入了解学习到了Hadoop的基本构成和基本原理。认识到了自己了解到的东西还是太少,需要更加努力学习相关知识。