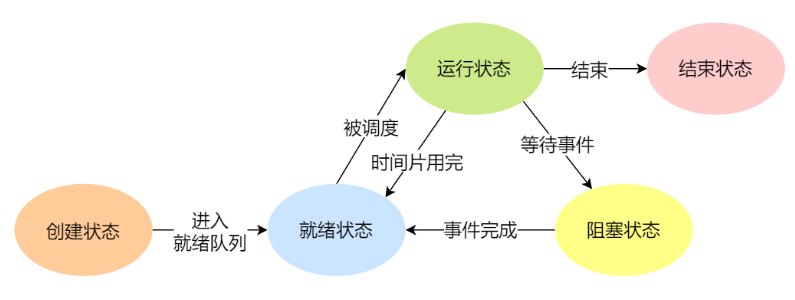
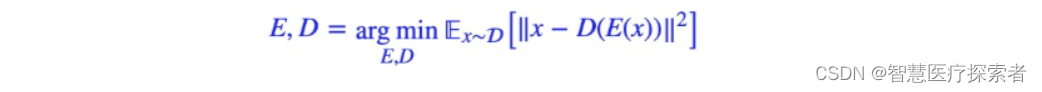import torch
from torch import nn
import torch. nn. functional as F
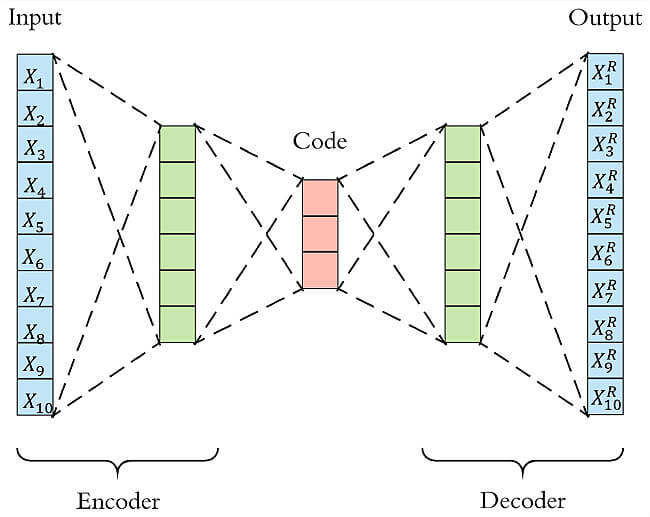
class Encoder ( nn. Module) :
def __init__ ( self, input_size, hidden_size, latent_size) :
super ( Encoder, self) . __init__( )
self. linear1 = nn. Linear( input_size, hidden_size)
self. linear2 = nn. Linear( hidden_size, latent_size)
def forward ( self, x) :
x = F. relu( self. linear1( x) )
x = self. linear2( x)
return x
class Decoder ( nn. Module) :
def __init__ ( self, latent_size, hidden_size, output_size) :
super ( Decoder, self) . __init__( )
self. linear1 = nn. Linear( latent_size, hidden_size)
self. linear2 = nn. Linear( hidden_size, output_size)
def forward ( self, x) :
x = F. relu( self. linear1( x) )
x = self. linear2( x)
return x
class AutoEncoder ( nn. Module) :
def __init__ ( self, input_size, hidden_size, latent_size, output_size) :
super ( AutoEncoder, self) . __init__( )
self. encoder = Encoder( input_size, hidden_size, latent_size)
self. decoder = Decoder( latent_size, hidden_size, output_size)
def forward ( self, x) :
x = self. encoder( x)
x = self. decoder( x)
return x
from io import BytesIO
import lmdb
from PIL import Image
from torch. utils. data import Dataset
from imutils. paths import list_files
class LMDBDataset ( Dataset) :
def __init__ ( self, path, transform, resolution= 256 , max_num= 70000 ) :
self. env = lmdb. open (
path,
max_readers= 32 ,
readonly= True ,
lock= False ,
readahead= False ,
meminit= False ,
)
if not self. env:
raise IOError( 'Cannot open lmdb dataset' , path)
self. keys = [ ]
with self. env. begin( write= False ) as txn:
cursor = txn. cursor( )
for idx, ( key, _) in enumerate ( cursor) :
self. keys. append( key)
if idx > max_num:
break
self. length = len ( self. keys)
self. resolution = resolution
self. transform = transform
def __len__ ( self) :
return self. length
def __getitem__ ( self, index) :
with self. env. begin( write= False ) as txn:
key = self. keys[ index]
img_bytes = txn. get( key)
buffer = BytesIO( img_bytes)
img = Image. open ( buffer ) . resize( ( self. resolution, self. resolution) )
img = self. transform( img)
return img
IMG_EXTENSIONS = [ 'webp' , '.png' , '.jpg' , '.jpeg' , '.ppm' , '.bmp' , '.pgm' , '.tif' , '.tiff' ]
class NormalDataset ( Dataset) :
def __init__ ( self, path, transform, resolution= 256 , max_num= 70000 ) :
self. files = [ ]
listed_files = sorted ( list ( list_files( path) ) )
for i in range ( min ( max_num, len ( listed_files) ) ) :
file = listed_files[ i]
if any ( file . lower( ) . endswith( ext) for ext in IMG_EXTENSIONS) :
self. files. append( file )
self. resolution = resolution
self. transform = transform
self. length = len ( self. files)
def __len__ ( self) :
return self. length
def __getitem__ ( self, index) :
img = Image. open ( self. files[ index] ) . resize( ( self. resolution, self. resolution) )
img = self. transform( img)
return img
def set_dataset ( type , path, transform, resolution) :
datatype = None
if type == 'lmdb' :
datatype = LMDBDataset
elif type == 'normal' :
datatype = NormalDataset
else :
raise NotImplementedError
return datatype( path, transform, resolution)
from torch. utils import data
def data_sampler ( dataset, shuffle) :
if shuffle:
return data. RandomSampler( dataset)
else :
return data. SequentialSampler( dataset)
def sample_data ( loader) :
while True :
for batch in loader:
yield batch
from torch import nn, optim
from tqdm import tqdm
from AutoEncoder import AutoEncoder
from torch. utils import data
from torchvision import transforms
from dataset import set_dataset
import argparse
from utils import data_sampler, sample_data
import torch
import os
import matplotlib. pyplot as plt
def train ( args, dataloader_train, dataloader_test, model, criterion, optimizer) :
for epoch in range ( args. epochs) :
model. train( )
train_loss = 0
train_sample = 0
t = tqdm( dataloader_train, desc= f'[ { epoch} / { args. epochs} ]' )
for i, x in enumerate ( t) :
x = x. to( args. device) . view( args. batch_size, args. image_size * args. image_size * 3 )
output = model( x)
loss = criterion( x, output)
loss. backward( )
optimizer. step( )
optimizer. zero_grad( )
train_loss += loss. item( )
train_sample += args. batch_size
t. set_postfix( { "loss" : train_loss / train_sample} )
torch. save( { "model_state_dict" : model. state_dict( ) , "epoch" : epoch+ 1 } , f' { args. ckpt_dir} /ckpt_ { epoch} .pt' )
torch. save( { "model_state_dict" : model. state_dict( ) , "epoch" : epoch+ 1 } , f' { args. ckpt_dir} /ckpt.pt' )
model. eval ( )
imgs = next ( sample_data( dataloader_test) )
imgs = imgs. to( args. device)
imgs = imgs. to( args. device) . view( args. batch_size, args. image_size * args. image_size * 3 )
test_output = model( imgs)
imgs = imgs[ 0 ] . view( 3 , args. image_size, args. image_size)
imgs = imgs. permute( 1 , 2 , 0 ) * 0.5 + 0.5
test_output = test_output[ 0 ] . view( 3 , args. image_size, args. image_size)
test_output = test_output. permute( 1 , 2 , 0 ) * 0.5 + 0.5
concat = torch. cat( ( imgs, test_output) , 1 )
print ( concat. shape)
plt. matshow( concat. cpu( ) . detach( ) . numpy( ) , cmap= 'gray' )
plt. savefig( f" { args. sample_dir} /test_ { epoch} .png" )
plt. show( )
if __name__ == '__main__' :
args = {
"exp_name" : "test2" ,
"dataset_type" : "normal" ,
"dataset_path_train" : r"D:\MyFiles\Papers\Codes\datasets\celebahq_train" ,
"dataset_path_test" : r"D:\MyFiles\Papers\Codes\datasets\celebahq_test" ,
"image_size" : 64 ,
"batch_size" : 32 ,
"hidden_size" : 128 ,
"latent_size" : 64 ,
"learning_rate" : 0.001 ,
"epochs" : 30 ,
"device" : "cuda" ,
"log_interval" : 100 ,
"save_interval" : 500 ,
"ckpt" : "ckpt.pt" ,
"resume" : False ,
}
args = argparse. Namespace( ** args)
base_dir = f"experiments/ { args. exp_name} " = f" { base_dir} /checkpoints" = f" { base_dir} /samples" . makedirs( ckpt_dir, exist_ok= True )
os. makedirs( sample_dir, exist_ok= True )
args. ckpt_dir = ckpt_dir
args. sample_dir = sample_dir
transform = transforms. Compose(
[
transforms. RandomHorizontalFlip( ) ,
transforms. ToTensor( ) ,
transforms. Normalize( ( 0.5 , 0.5 , 0.5 ) , ( 0.5 , 0.5 , 0.5 ) , inplace= True ) ,
]
)
dataset_train = set_dataset(
type = args. dataset_type,
path= args. dataset_path_train,
transform= transform,
resolution= args. image_size
)
loader_train = data. DataLoader(
dataset= dataset_train,
batch_size= args. batch_size,
sampler= data_sampler( dataset= dataset_train, shuffle= True )
)
dataset_test = set_dataset(
type = args. dataset_type,
path= args. dataset_path_test,
transform= transform,
resolution= args. image_size
)
loader_test = data. DataLoader(
dataset= dataset_test,
batch_size= args. batch_size,
sampler= data_sampler( dataset= dataset_test, shuffle= False )
)
input_size = output_size = args. image_size * args. image_size * 3
model = AutoEncoder( input_size, args. hidden_size, args. latent_size, output_size) . to( args. device)
if args. resume:
print ( "加载预训练模型:" , args. ckpt)
ckpt = torch. load( f" { ckpt_dir} / { args. ckpt} " , map_location= lambda storage, loc: storage)
args. epoch = ckpt[ 'epoch' ]
model. load_state_dict( ckpt[ 'model_state_dict' ] )
criterion = nn. MSELoss( )
optimizer = optim. Adam( model. parameters( ) , lr= args. learning_rate)
train( args, loader_train, loader_test, model, criterion, optimizer)