关于
在脑电信号分析处理任务中,数据不均衡是一个常见的问题。针对数据不均衡,传统方法有过采样和欠采样方法来应对,但是效果有限。本项目通过变分自编码器对脑电信号进行生成增强,提高增强样本的多样性,从而提高最终的后端分析性能。
工具

数据集下载地址: BCI Competition IV

方法实现
加载必要的库函数和数据
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import glob
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Input, Conv2D, Conv2DTranspose, BatchNormalization, LeakyReLU, Dense, Lambda, Reshape, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.losses import mse
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras import backend as K
direc = r'bci_iv_2a_data/A01/train/0/' #data directory
train_dataset = []
train_label = []
test_dataset = []
test_label = []
files = os.listdir(direc)
for j, name in enumerate(files):
filename = glob.glob(direc + '/'+ name)
df = pd.read_csv(filename[0], index_col=None, header=None)
df = df.drop(0, axis=1) #dropping column of channel names
df = df.iloc[:,0:1000] #taking 1000 timesteps
train_dataset.append(np.array(df))
train_dataset = np.array(train_dataset)
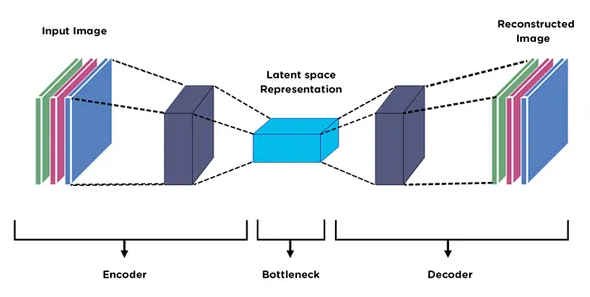
train_data = np.expand_dims(train_dataset,axis=-1)VAE模型>编码器定义
# VAE model
input_shape=(X_train.shape[1:])
batch_size = 32
kernel_size = 5
filters = 16
latent_dim = 2
epochs = 1000
# reparameterization
def sampling(args):
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1]
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + K.exp(0.5 * z_log_var) * epsilon
# encoder
inputs = Input(shape=input_shape, name='encoder_input')
x = inputs
filters = filters* 2
x = Conv2D(filters=filters,kernel_size=(1, 50),strides=(1,25),)(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
filters = filters* 2
x = Conv2D(filters=filters,kernel_size=(22, 1),)(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
shape = K.int_shape(x)
x = Flatten()(x)
x = Dense(16, activation='relu')(x)
z_mean = Dense(latent_dim, name='z_mean')(x)
z_log_var = Dense(latent_dim, name='z_log_var')(x)
z_log_var = z_log_var + 1e-8
# reparameterization
z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var])
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
encoder.summary()VAE模型>解码器定义
# decoder
latent_inputs = Input(shape=(latent_dim,), name='z_sampling')
x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs)
x = Reshape((shape[1], shape[2], shape[3]))(x)
x = Conv2DTranspose(filters=filters,kernel_size=(22, 1),activation='relu',)(x)
x = BatchNormalization()(x)
filters = filters// 2
x = Conv2DTranspose(filters=filters,kernel_size=(1, 50),activation='relu',strides=(1,25))(x)
x = BatchNormalization()(x)
filters = filters// 2
outputs = Conv2DTranspose(filters=1,kernel_size=kernel_size,padding='same',name='decoder_output')(x)
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()# VAE model (merging encoder and decoder)
outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, outputs, name='vae')
vae.summary()定义损失函数
# defining Custom loss function
reconstruction_loss = mse(K.flatten(inputs), K.flatten(outputs))
reconstruction_loss *= input_shape[0] * input_shape[1]
kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var)
kl_loss = K.sum(kl_loss, axis=-1)
kl_loss *= -0.5
vae_loss = K.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
#optimizer
optimizer = Adam(learning_rate=0.001, beta_1=0.5, beta_2=0.999)
# compiling vae
vae.compile(optimizer=optimizer, loss=None)
vae.summary()模型配置和训练
# early stopping callback
callbacks = EarlyStopping(monitor = 'val_loss',
mode='min',
patience =50,
verbose = 1,
restore_best_weights = True)
# fit vae model
history = vae.fit(X_train,X_train,
epochs=epochs,
batch_size=batch_size,
validation_data=(X_test, X_test),callbacks=callbacks)
训练流程可视化
# loss curves
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('loss curves')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()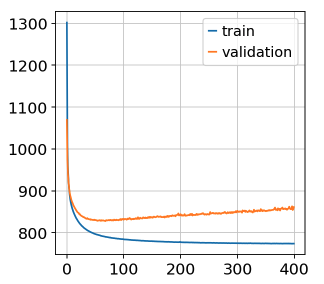
中间隐空间特征2D可视化
# 2D plot of the classes in latent space
z_m, _, _ = encoder.predict(X_test,batch_size=batch_size)
plt.figure(figsize=(12, 10))
plt.scatter(z_m[:, 0], z_m[:, 1], c=X_test[:,0,0,0])
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.show()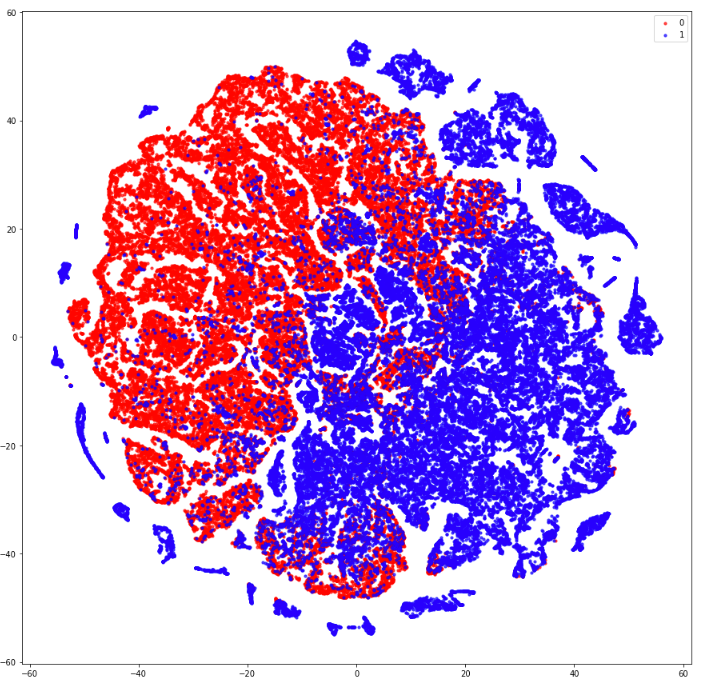
数据合成
# predicting on validation data
pred=vae.predict(X_test)代码获取
附文章底部;
相关项目开发,问题咨询,欢迎交流沟通。