Linux文本处理三剑客:awk、grep和sed的完美结合
在Linux世界里,文本处理是一项至关重要的任务。无论是日常的系统管理还是复杂的软件开发,都需要对文本数据进行提取、过滤和转换。Linux为我们提供了三款强大的文本处理工具:awk、grep和sed,它们被称为“文本三剑客”。
一、grep:文本搜索的利器
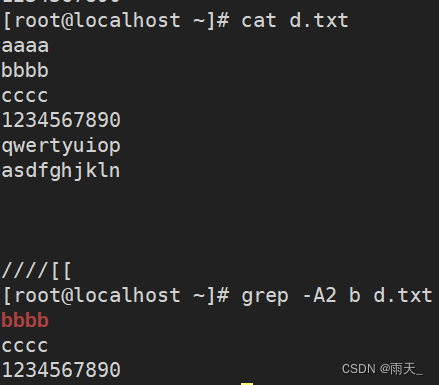
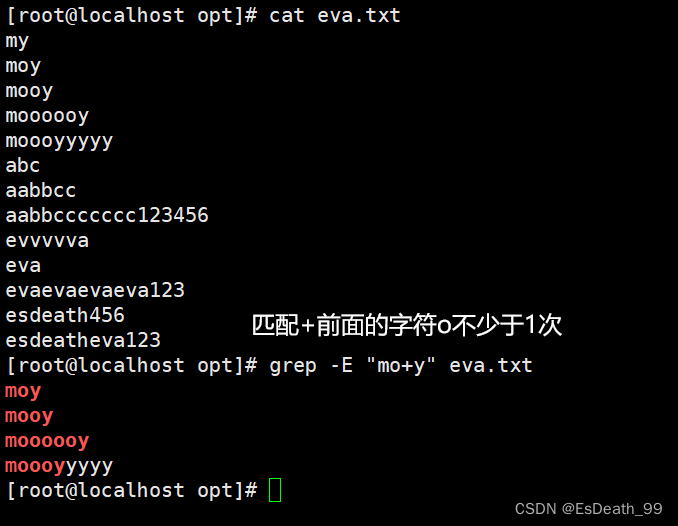
grep是文本搜索的利器,它使用正则表达式来匹配文本内容,并将匹配的行打印出来。在论坛文章中,可以使用grep来快速查找关键信息。
例如,假设我们有一个包含大量论坛帖子的文本文件forum.txt,我们可以使用grep来查找包含特定关键词的帖子:
grep "关键词" forum.txt
grep会输出所有包含关键词的行,让我们能够迅速定位到相关的讨论内容。
二、awk:文本提取与报表生成的专家
awk是一个强大的文本分析工具,它擅长处理结构化文本数据,提取所需的信息,并生成报表。在论坛文章中,我们可以利用awk来提取用户信息、统计帖子数量等。
例如,假设forum.txt文件中的每一行都包含用户的用户名、发帖时间和帖子内容,我们可以使用awk来提取用户名列表:
awk '{print $1}' forum.txt
这条命令会输出forum.txt文件中每一行的第一个字段,即用户名。通过调整awk的字段分隔符和打印格式,我们可以灵活地提取和格式化文本数据。
三、sed:文本编辑与转换的瑞士军刀
sed是一个流编辑器,它可以在文本流中执行基本的文本转换和编辑操作。在论坛文章中,我们可以使用sed来清理文本格式、替换敏感信息或进行批量修改。
例如,如果我们想要将forum.txt文件中所有的URL链接替换为"[链接]"字样,以保护用户的隐私,可以使用以下sed命令:
sed 's/http[s]?:\/\/[^\s]*/[链接]/g' forum.txt
这条命令使用正则表达式匹配URL模式,并将其替换为"[链接]"字样。通过类似的sed命令,我们可以对论坛文章进行各种文本转换和编辑操作,以满足不同的需求。
使用示例:
以下是“文本三剑客”awk、grep和sed的一些基础使用示例:
grep
- 查找单个字符串:在文件example.txt中查找包含字符串"hello"的所有行:
grep "hello" example.txt
- 查找多个字符串:在文件example.txt中查找包含字符串"hello"或"world"的所有行:
grep "hello\|world" example.txt
- 使用正则表达式查找模式:查找文件example.txt中包含以"he"开头的字符串的行:
grep "^he" example.txt
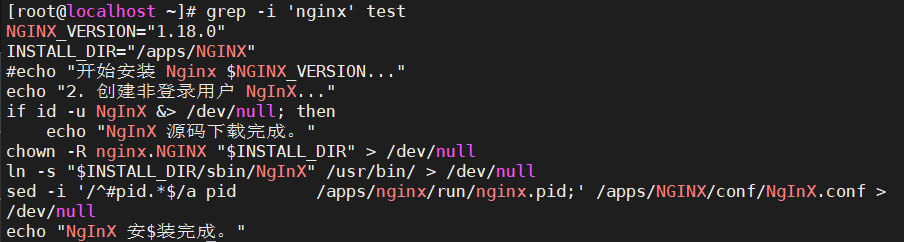
- 忽略大小写:查找文件example.txt中包含字符串"hello"(忽略大小写)的所有行:
grep -i "hello" example.txt
sed
- 替换文件中的字符串:将文件fruits.txt中所有的"apple"替换为"banana":
sed 's/apple/banana/g' fruits.txt
- 删除文件中的行:删除文件example.txt中包含字符串"hello"的所有行:
sed '/hello/d' example.txt
如果希望直接修改文件内容,可以使用-i选项:
sed -i 's/apple/banana/g' fruits.txt
s:这是sed替换命令的标识符。它告诉sed我们要执行一个替换操作。apple:这是我们要查找并替换的文本模式(或称为“源字符串”)。在这个例子中,我们查找的是文本“apple”。banana:这是我们要替换成的文本(或称为“目标字符串”)。在这个例子中,我们将“apple”替换为“banana”。g:这是一个全局替换的标志。它告诉sed在整个行中替换所有匹配的“apple”,而不仅仅是每行的第一个匹配。如果省略g,则只替换每行的第一个匹配。-i:选项告诉sed直接修改文件内容,而不是将修改后的内容输出到标准输出。
awk
- 打印文件的第一列:假设文件data.txt的内容由空格分隔的字段组成,打印其第一列:
awk '{print $1}' data.txt
- 统计文件中的行数:统计文件example.txt的行数:
awk 'END {print NR}' example.txt
- 条件打印:打印文件data.txt中第一列大于10的所有行:
awk '$1 > 10' data.txt
通过结合正则表达式、管道和其他命令,可以实现更为复杂和强大的文本处理任务。对于更高级的用法和选项,建议查阅各工具的官方文档或手册页(通过man grep、man sed、man awk命令查看)。