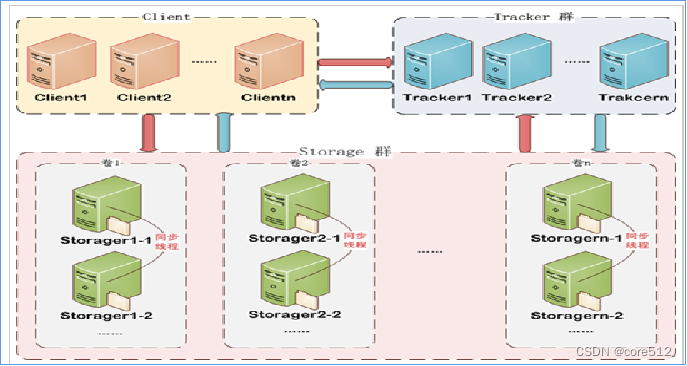
一、编译环境准备
1、hadoop和hive安装
hive官网版本依赖:https://hive.apache.org/general/downloads/
这里都是用了hadoop3.1.3和hive3.1.3版本,具体的安装可以参考之前的文章
2、编译环境搭建
使用了ubuntu20作为的编译环境
# ==================安装jdk===========
# 卸载现有JDK
# centos 操作
# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
# 下面是ubuntu
sudo apt-get remove openjdk-8-jre-headless
# 将JDK上传到虚拟机的/opt/software文件夹下面
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
# 配置JDK环境变量
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# 让环境生效
source /etc/profile.d/my_env.sh
# 查看是否成功
java -version
# ==================安装maven========
wget https://dlcdn.apache.org/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
# 解压Maven到/opt/module目录下
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module/
# 配置Maven环境变量
sudo vim /etc/profile.d/my_env.sh
# MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin
# 让环境变量生效
source /etc/profile.d/my_env.sh
mvn -version
# 配置仓库镜像
vim /opt/module/apache-maven-3.6.3/conf/settings.xml
# 在<mirrors></mirrors>节点中增加以下内容
<mirror>
<id>aliyunmaven</id>
<mirrorOf>central</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
# ====================安装Git====================
# 这是对于centos的
sudo yum install https://repo.ius.io/ius-release-el7.rpm https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
sudo yum install -y git236
# 对于ubuntu来说,甚至可以自带
sudo apt-get install git
# =====================安装IDEA=======================
wget https://download.jetbrains.com/idea/ideaIU-2021.1.3.tar.gz
# 解压IDEA到/opt/module目录下
tar -zxvf ideaIU-2021.1.3.tar.gz -C /opt/module/
# 启动IDEA(在图形化界面启动)
nohup /opt/module/idea-IU-211.7628.21/bin/idea.sh 1>/dev/null 2>&1 &
# 配置Maven,配置好maven
3、Hive on Spark配置
# 1、Spark官网下载jar包地址,在Hive所在节点部署Spark纯净版
http://spark.apache.org/downloads.html
# 上传并解压解压spark-3.1.3-bin-without-hadoop.tgz
tar -zxvf spark-3.1.3-bin-without-hadoop.tgz -C /opt/module/
mv /opt/module/spark-3.1.3-bin-hadoop3 /opt/module/spark
# 修改spark-env.sh配置文件
mv /opt/module/spark/conf/spark-env.sh.template /opt/module/spark/conf/spark-env.sh
# 增加如下内容
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
# 2、配置SPARK_HOME环境变量
sudo vim /etc/profile.d/my_env.sh
# 添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
# 生效
source /etc/profile.d/my_env.sh
# 3、在hive中创建spark配置文件
vim /opt/module/hive/conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
# 在HDFS创建如下路径,用于存储历史日志
hadoop fs -mkdir /spark-history
向HDFS上传Spark纯净版jar包
- 说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
- 说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
# 上传并解压spark-3.0.0-bin-without-hadoop.tgz
tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
# 上传Spark纯净版jar包到HDFS
hadoop fs -mkdir /spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
# 修改hive-site.xml文件
vim /opt/module/hive/conf/hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
Hive on Spark测试
# 启动hive客户端
bin/hive
# 创建一张测试表
hive (default)> create table student(id int, name string);
# 通过insert测试效果
hive (default)> insert into table student values(1,'abc');
二、Hive相关问题
1、Hadoop和Hive的兼容性问题
1.1 问题描述
配置好3.1.3版本之后,启动hive会报错
java.lang.NoSuchMethodError:
com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
上述问题是由Hadoop3.1.3版本所依赖的guava-27.0-jre和Hive-3.1.3版本所依赖的guava-19.0不兼容所致
1.2 解决思路
更换Hadoop版本
经过观察发现,Hadoop-3.1.0,Hadoop-3.1.1,Hadoop-3.1.2版本的guava依赖均为guava-11.0.2,而到了Hadoop-3.1.3版本,guava依赖的版本突然升级到了guava-27.0-jre。Hive-3的所有发行版本的guava依赖均为guava-19.0。而guava-19.0和guava-11.0.2版本是兼容的,所以理论上降低Hadoop版本,这个问题就能得到有效的解决(将hadoop的guava-27.0-jre复制到hive中也可以暂时使用)
升级Hive-3.1.3中的guava依赖版本,并重新编译Hive
若将Hive-3.1.3中的guava依赖版本升级到guava-27.0-jre,这样就能避免不同版本的guava依赖冲突,上述问题同样能得到解决。
1.3 修改并编译Hive源码
# Hive源码的远程仓库地址:
https://github.com/apache/hive.git
# 国内镜像地址:
https://gitee.com/apache/hive.git
# 编译官网:https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-BuildingHivefromSource
# 首先测试一下能不能成功打包
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
# 修改Maven父工程的pom.xml文件中的guava.version参数
# 将<guava.version>19.0</guava.version>改为<guava.version>27.0-jre</guava.version>
# 不停排错,直至编译打包成功
2、Hive插入数据StatsTask失败问题
3.1 问题描述
# 启动hive客户端
bin/hive
# 创建一张测试表
create table student(id int, name string);
# 执行insert语句
insert into table student values(1,'abc');
# 测试发现过程发现如下错误信息
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask
# 该问题问由Hive自身存在的bug所致,bug详情可参照以下连接:https://issues.apache.org/jira/browse/HIVE-19316
3.2 解决思路
该bug已经在3.2.0, 4.0.0, 4.0.0-alpha-1等版本修复了,所以可以参考修复问题的PR,再修改Hive源码并重新编译
3、Hive和Spark兼容性问题
3.1 问题描述
# 配置好hive on spark 后,启动hive客户端
bin/hive
insert into table student values(1,'abc');
# 测试发现过程发现如下错误信息
Job failed with java.lang.NoSuchMethodError:
org.apache.spark.api.java.JavaSparkContext.accumulator(Ljava/lang/Object;Ljava/lang/String;Lorg/apache/spark/AccumulatorParam;)Lorg/apache/spark/Accumulator;
问题是官网下载的Hive3.1.3和Spark3.0.0默认是不兼容的。因为Hive3.1.3支持的Spark版本是2.3.0,所以需要我们重新编译Hive3.1.3版本
3.2 解决思路
降低Spark版本
经过观察发现Hive-3.1.3,版本所兼容的Spark版本为Spark-2.3.0,故降低Spark版本便可有效解决该问题。
升级Hive-3.1.3中的Spark依赖版本至Spark-3.1.3,并重新编译Hive
将Hive源码中的Spark依赖版本升级为Spark-3.1.3,并修改源码,重新编译打包后,同样能解决该问题。
3.3 修改实操
# 修改Hive项目的pom.xml文件,将spark依赖的版本改为3.1.3
<spark.version>2.3.0</spark.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.8</scala.version>
# 将上面的依赖变为
<spark.version>3.1.3</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.10</scala.version>
# 然后将错误信息弄好即可
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
4、Hive编译实战
下面我说一下我编译过程遇到的问题,首先将hive源码克隆下来,git选择checkout Tag or Revision,选择rel/release-3.1.3进行编译
# 开始前需要首先编译测试一下环境
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
# 这里有可能会遇到5.1.5-jhyde没有这个jar包错误,将其放入maven仓库即可
# 然后0001-guava-27.0-jre.patch/HIVE-19316.patch/spark-3_1_3.patch这三个git补丁包分别对应上面三个问题
# 选择git apply即可导入比较,这个自行研究了
# 同时针对HIVE-19316问题,可以在可视化的git log中搜索HIVE-19316,选择最新的commit,点击cherry-pick和打补丁一样的效果
补丁文件包,依赖包,hive3.1.2-spark3.0.0和hive3.1.3-spark3.1.3二进制包已经全部放进该压缩包
三、调优之Yarn和Spark配置
1、环境配置介绍
一般生产环境NN和RM吃资源少的会单独配置,而工作节点会单独配置资源较多,例如Master节点配置为16核CPU、64G内存;Workder节点配置为32核CPU、128G内存,五台服务器如下所示
| hadoop100 | hadoop101 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|---|
| master | master | worker | worker | worker |
| NameNode | NameNode | DataNode | DataNode | DataNode |
| ResourceManager | ResourceManager | NodeManager | NodeManager | NodeManager |
| JournalNode | JournalNode | JournalNode | ||
| Zookeeper | Zookeeper | Zookeeper | ||
| Kafka | Kafka | Kafka | ||
| Hiveserver2 | Metastore | hive-client | hive-client | hive-client |
| Spark | Spark | Spark | Spark | |
| DS-master | DS-master | DS-worker | DS-worker | DS-worder |
| Maxwell | ||||
| mysql | ||||
| flume | flume |
2、Yarn配置
2.1 Yarn配置说明
需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下
- yarn.nodemanager.resource.memory-mb
一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。考虑上述因素,此处可将该参数设置为64G
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
- yarn.nodemanager.resource.cpu-vcores
一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。考虑上述因素,此处可将该参数设置为16
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
- yarn.scheduler.maximum-allocation-mb
该参数的含义是,单个Container能够使用的最大内存。由于Spark的yarn模式下,Driver和Executor都运行在Container中,故该参数不能小于Driver和Executor的内存配置,推荐配置如下
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
- yarn.scheduler.minimum-allocation-mb
该参数的含义是,单个Container能够使用的最小内存,推荐配置如下:
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
2.2 Yarn配置实操
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件,修改如下参数,然后分发重启yarn(注意,对于单台的话,想修改哪台资源就动对应的机器)
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
3、Spark配置
3.1 Executor配置说明
- Executor CPU核数配置
单个Executor的CPU核数,由spark.executor.cores参数决定,建议配置为4-6,具体配置为多少,视具体情况而定,原则是尽量充分利用资源
此处单个节点共有16个核可供Executor使用,则spark.executor.core配置为4最合适。原因是,若配置为5,则单个节点只能启动3个Executor,会剩余1个核未使用;若配置为6,则只能启动2个Executor,会剩余4个核未使用
- Executor内存配置
Spark在Yarn模式下的Executor内存模型如下图所示
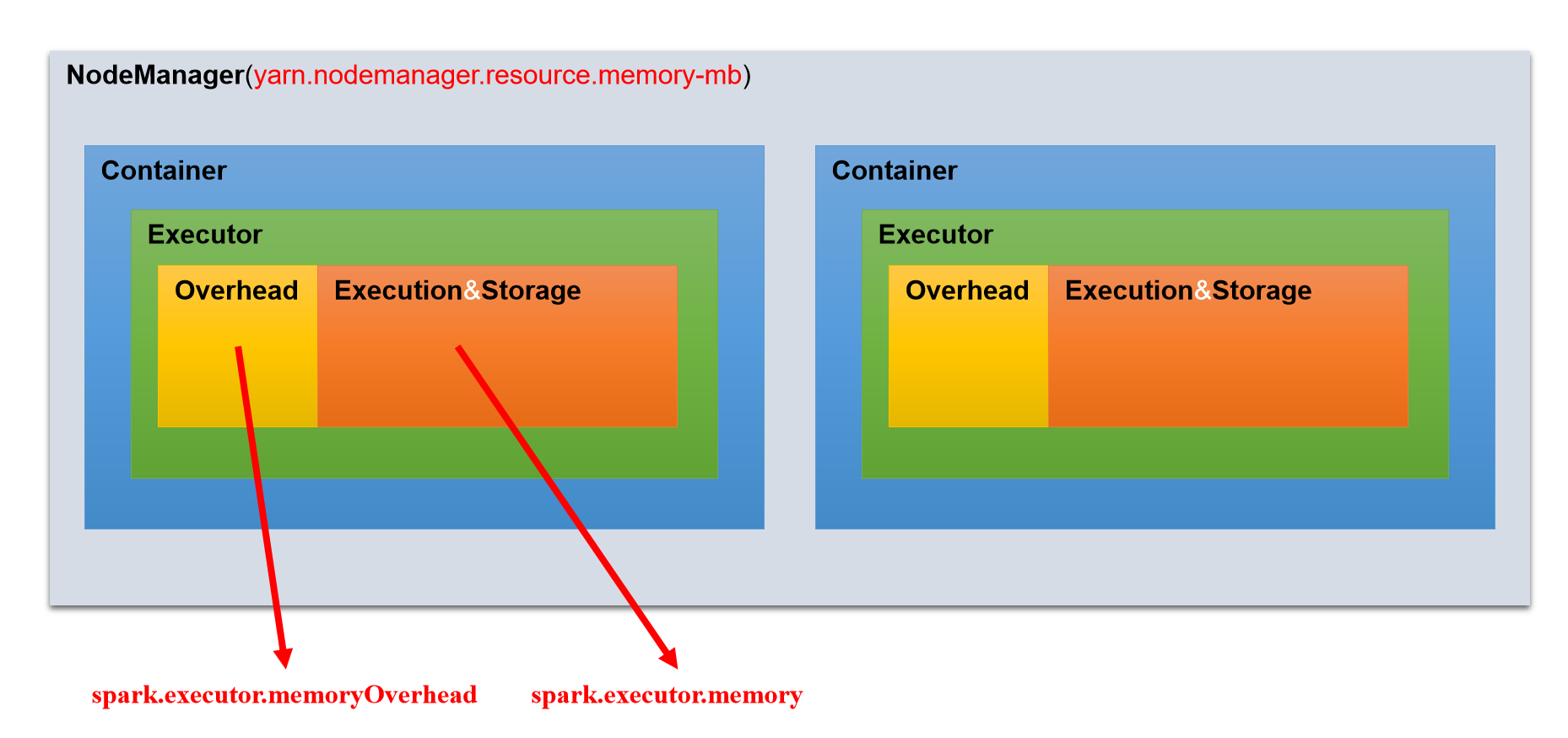
Executor相关的参数有:spark.executor.memory和spark.executor.memoryOverhead。spark.executor.memory用于指定Executor进程的堆内存大小,这部分内存用于任务的计算和存储;spark.executor.memoryOverhead用于指定Executor进程的堆外内存,这部分内存用于JVM的额外开销,操作系统开销等。两者的和才算一个Executor进程所需的总内存大小。默认情况下spark.executor.memoryOverhead的值等于spark.executor.memory*0.1。
以上两个参数的推荐配置思路是,先按照单个NodeManager的核数和单个Executor的核数,计算出每个NodeManager最多能运行多少个Executor。在将NodeManager的总内存平均分配给每个Executor,最后再将单个Executor的内存按照大约10:1的比例分配到spark.executor.memory和spark.executor.memoryOverhead。根据上述思路,可得到如下关系:
# (spark.executor.memory+spark.executor.memoryOverhead)=
# yarn.nodemanager.resource.memory-mb * (spark.executor.cores/yarn.nodemanager.resource.cpu-vcores)
# 经计算,此处应做如下配置:
spark.executor.memory 14G
spark.executor.memoryOverhead 2G
3.2 Executor个数配置
此处的Executor个数是指分配给一个Spark应用的Executor个数,Executor个数对于Spark应用的执行速度有很大的影响,所以Executor个数的确定十分重要。一个Spark应用的Executor个数的指定方式有两种,静态分配和动态分配
- 静态分配
可通过spark.executor.instances指定一个Spark应用启动的Executor个数。这种方式需要自行估计每个Spark应用所需的资源,并为每个应用单独配置Executor个数。
- 动态分配
动态分配可根据一个Spark应用的工作负载,动态的调整其所占用的资源(Executor个数)。这意味着一个Spark应用程序可以在运行的过程中,需要时,申请更多的资源(启动更多的Executor),不用时,便将其释放。在生产集群中,推荐使用动态分配。动态分配相关参数如下:
#启动动态分配
spark.dynamicAllocation.enabled true
#启用Spark shuffle服务
spark.shuffle.service.enabled true
#Executor个数初始值
spark.dynamicAllocation.initialExecutors 1
#Executor个数最小值
spark.dynamicAllocation.minExecutors 1
#Executor个数最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空闲时长,若某Executor空闲时间超过此值,则会被关闭
spark.dynamicAllocation.executorIdleTimeout 60s
#积压任务等待时长,若有Task等待时间超过此值,则申请启动新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
#spark shuffle老版本协议
spark.shuffle.useOldFetchProtocol true
说明:Spark shuffle服务的作用是管理Executor中的各Task的输出文件,主要是shuffle过程map端的输出文件。由于启用资源动态分配后,Spark会在一个应用未结束前,将已经完成任务,处于空闲状态的Executor关闭。Executor关闭后,其输出的文件,也就无法供其他Executor使用了。需要启用Spark shuffle服务,来管理各Executor输出的文件,这样就能关闭空闲的Executor,而不影响后续的计算任务了
3.3 Driver配置说明
Driver主要配置内存即可,相关的参数有spark.driver.memory和spark.driver.memoryOverhead。spark.driver.memory用于指定Driver进程的堆内存大小,spark.driver.memoryOverhead用于指定Driver进程的堆外内存大小。默认情况下,两者的关系如下:spark.driver.memoryOverhead=spark.driver.memory*0.1。两者的和才算一个Driver进程所需的总内存大小。
一般情况下,按照如下经验进行调整即可:假定yarn.nodemanager.resource.memory-mb设置为X,若X>50G,则Driver可设置为12G,若12G<X<50G,则Driver可设置为4G。若1G<X<12G,则Driver可设置为1G。 此处yarn.nodemanager.resource.memory-mb为64G,则Driver的总内存可分配12G,所以上述两个参数可配置为。
spark.driver.memory 10G
spark.yarn.driver.memoryOverhead 2G
3.4 Spark配置实操
修改$HIVE_HOME/conf/spark-defaults.conf,注意hive连哪台就修改哪台,也可以都分发
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.shuffle.useOldFetchProtocol true
然后配置Spark shuffle服务,Spark Shuffle服务的配置因Cluster Manager(standalone、Mesos、Yarn)的不同而不同。此处以Yarn作为Cluster Manager
- 拷贝
$SPARK_HOME/yarn/spark-3.0.0-yarn-shuffle.jar到$HADOOP_HOME/share/hadoop/yarn/lib; - 分发
$HADOOP_HOME/share/hadoop/yarn/lib/yarn/spark-3.0.0-yarn-shuffle.jar - 修改
$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
- 分发
$HADOOP_HOME/etc/hadoop/yarn-site.xml文件 - 重启Yarn
四、查询优化
具体的hive优化可以参考Hive文章中的企业级调优,这里仅当复习
1、Hive SQL执行计划
参考1:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
参考2:https://cwiki.apache.org/confluence/download/attachments/44302539/hos_explain.pdf?version=1&modificationDate=1425575903211&api=v2
Hive SQL的执行计划,可由Explain查看。Explain呈现的执行计划,由一系列Stage组成,这个Stage具有依赖关系,每个Stage对应一个MapReduce Job或者Spark Job,或者一个文件系统操作等。每个Stage由一系列的Operator组成,一个Operator代表一个逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。
desc formated xxx
2、分组聚合优化
优化思路为map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成分区内的、部分的聚合,然后将部分聚合的结果,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
--启用map-side聚合
set hive.map.aggr=true;
--hash map占用map端内存的最大比例
set hive.map.aggr.hash.percentmemory=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的HashTable,占用map任务堆内存的最大比例,若超出该值,则会对HashTable进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
3、Join优化
3.1 Hive Join算法概述
Hive拥有多种join算法,包括common join,map join,sort Merge Bucket Map Join等
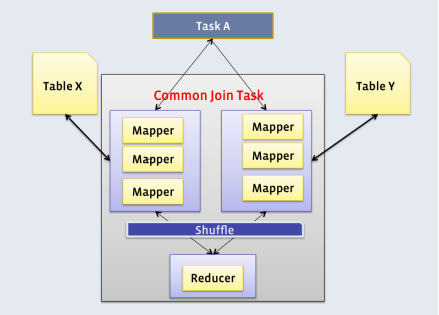
- common join
Map端负责读取参与join的表的数据,并按照关联字段进行分区,将其发送到Reduce端,Reduce端完成最终的关联操作
- map join
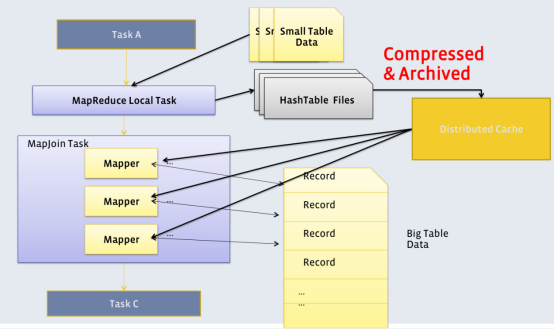
若参与join的表中,有n-1张表足够小,Map端就会缓存小表全部数据,然后扫描另外一张大表,在Map端完成关联操作
- Sort Merge Bucket Map Join
若参与join的表均为分桶表,且关联字段为分桶字段,且分桶字段是有序的,且大表的分桶数量是小表分桶数量的整数倍。此时,就可以以分桶为单位,为每个Map分配任务了,Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶
3.2 Map Join优化
join的两表一大一小,可考虑map join优化
--启用map join自动转换
set hive.auto.convert.join=true;
--common join转map join小表阈值
set hive.auto.convert.join.noconditionaltask.size=1612000
3.3 Sort Merge Bucket Map Join
两张表都相对较大,可以考虑采用SMB Map Join对分桶大小是没有要求的。首先需要依据源表创建两个的有序的分桶表,dwd_trade_order_detail_inc建议分36个bucket,dim_user_zip建议分6个bucket,注意分桶个数的倍数关系以及分桶字段和排序字段。(创建的时候就要创建桶,一般应用场景比较小)
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
4、数据倾斜优化
4.1 数据倾斜说明
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。Hive中的数据倾斜常出现在分组聚合和join操作的场景中
4.2 分组聚合导致的数据倾斜
-- 第一种方案
--启用map-side聚合
set hive.map.aggr=true;
--hash map占用map端内存的最大比例
set hive.map.aggr.hash.percentmemory=0.5;
-- 第二种方案
-- 启用skew groupby优化
-- 其原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
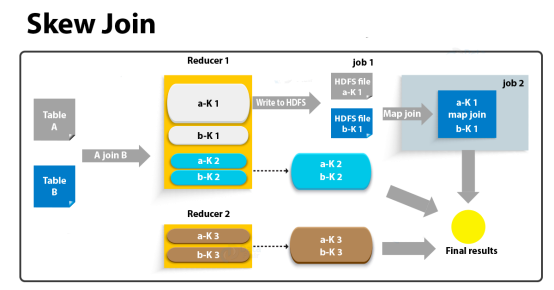
4.3 join导致的数据倾斜
-- 第一种方案
--启用map join自动转换
set hive.auto.convert.join=true;
--common join转map join小表阈值
set hive.auto.convert.join.noconditionaltask.size
-- 第二种方案
--启用skew join优化
set hive.optimize.skewjoin=true;
--触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
5、任务并行度优化
5.1 优化说明
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。在Hive中,无论其计算引擎是什么,所有的计算任务都可分为Map阶段和Reduce阶段。所以并行度的调整,也可从上述两个方面进行调整
5.2 Map阶段并行度
ap端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。Map端的并行度相关参数如下
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理,默认开启的
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
--一个切片的最大值
set mapreduce.input.fileinputformat.split.maxsize=256000000;
5.3 Reduce阶段并行度
Reduce端的并行度,相对来说,更需要关注。默认情况下,Hive会根据Reduce端输入数据的大小,估算一个Reduce并行度。但是在某些情况下,其估计值不一定是最合适的,故需要人为调整其并行度
--指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;
--Reduce端并行度最大值
set hive.exec.reducers.max;
--单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;
Reduce端并行度的确定逻辑为,若指定参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为指定值。否则,Hive会自行估算Reduce并行度,估算逻辑如下:
假设Reduce端输入的数据量大小为totalInputBytes,参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer,参数hive.exec.reducers.max的值为maxReducers,则Reduce端的并行度为:
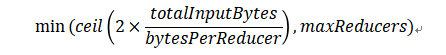
其中,Reduce端输入的数据量大小,是从Reduce上游的Operator的Statistics(统计信息)中获取的。为保证Hive能获得准确的统计信息,需配置如下参数
--执行DML语句时,收集表级别的统计信息,默认true
set hive.stats.autogather=true;
--执行DML语句时,收集字段级别的统计信息,默认true
set hive.stats.column.autogather=true;
--计算Reduce并行度时,从上游Operator统计信息获得输入数据量,默认true
set hive.spark.use.op.stats=true;
--计算Reduce并行度时,使用列级别的统计信息估算输入数据量,默认false
set hive.stats.fetch.column.stats=true;
6、小文件合并优化
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
--开启合并Hive on Spark任务输出的小文件
set hive.merge.sparkfiles=true;
其他优化:
参考1:https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_hos_tuning.html#hos_tuning
参考2:https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started