目录
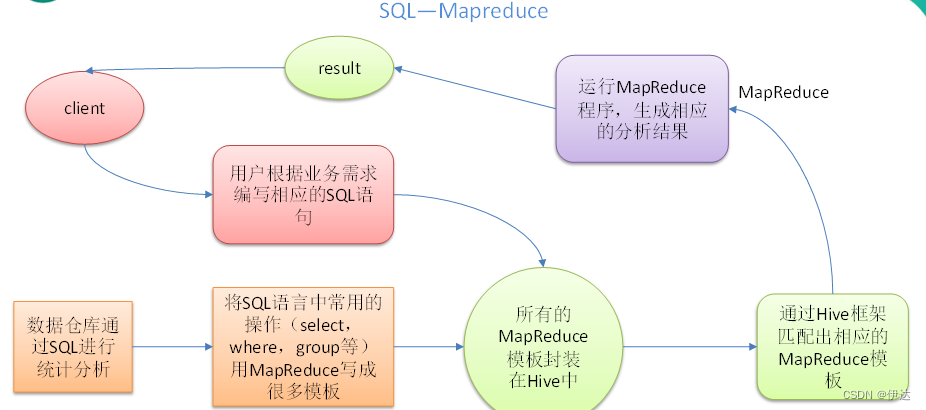
一、MapReduce的计算过程
分布式计算框架
需要编写代码执行,执行时会数据所在服务器上运行相同的计算代码
计算过程分为map 和reduce过程
map对多份数据进行拆分计算
reduce将分开的map结果合并一起计算
map的计算程序数量由文件块个数据决定,每个map计算一个块的数据
reduce的个数默认是一个;在进行数据拆分存储时,reduce个数由分区数和分桶数决定
map将数据传递给reduce过程称为shuffle过程
包含 分区,排序,合并
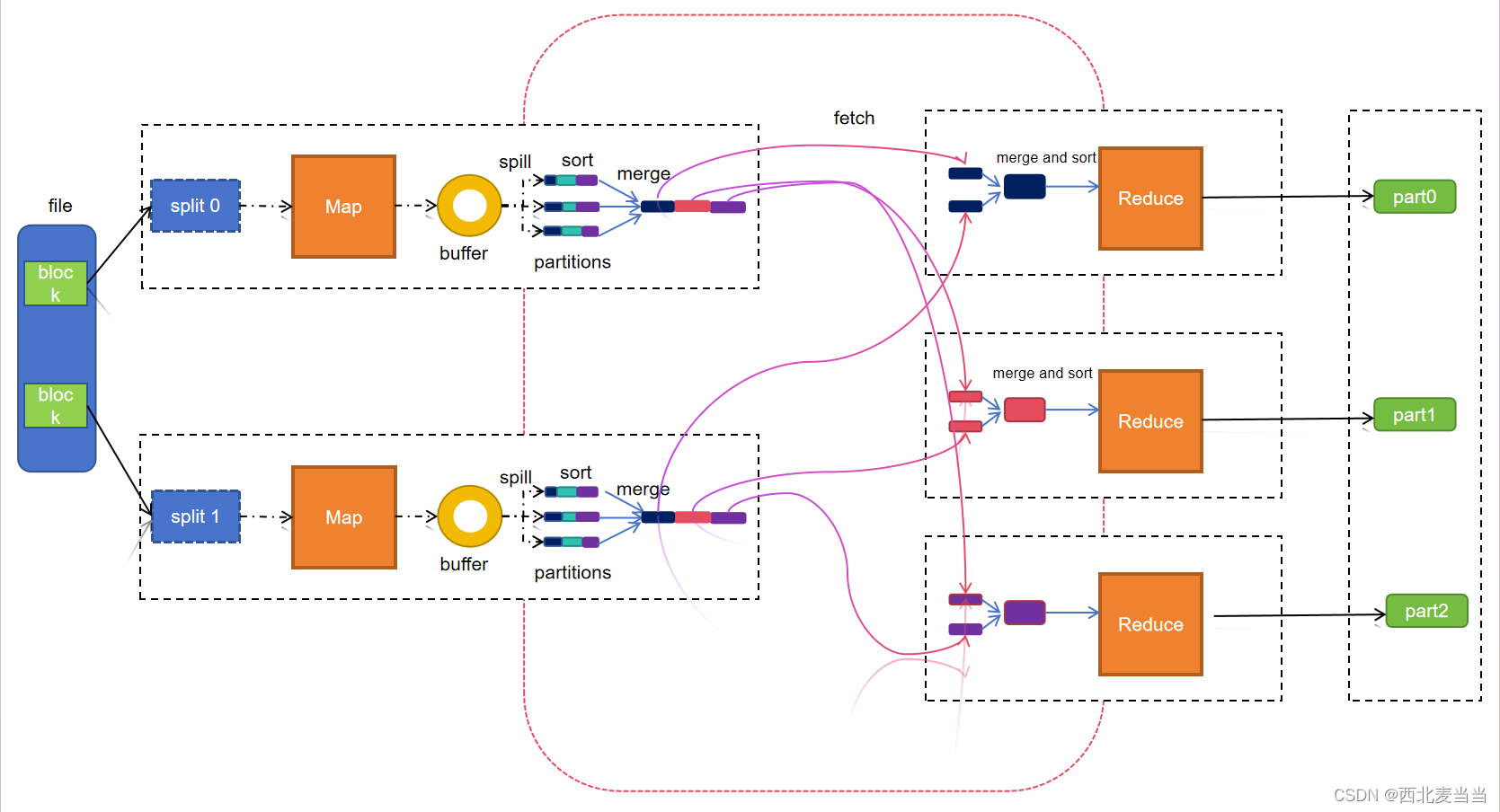
Map阶段
1-按照块数量进行split的块数据读取
2-split切割后的数据传递给对应的map进行处理,会对数据转为kv (张三,1) (张三,1),(李四,1)
3-map将处理的后的数据写入buffer缓存区
4-对缓冲区内的数据进行spill溢出(读取缓冲区内的数据)
5-对读取的数据进行分区,将数据拆分多份
6-对每份拆分的数据进行排序 sort
7-将拆分的数据写入不同的文件
8-在将每次溢出的数据合并merge在一起,保存同一文件,文件是临时文件,计算后会删除
Reduce阶段
1-根据的分区数创建出多个reduce
2-每个reduce从不同的map中fetch获取相同分区的文件数据
3-在将fetch后的文件合并,对合并后的数据进行排序
4-reduce对合并后的文件数据进行计算
5-reduce对结果输出到hdfs的目录下
二、Yarn的资源调度
分布式资源调度,管理整个hadoop集群的所有服务器资源
6.7章节
ResourceManger
负责处理所有计算资源申请
NodeManager
负责资源空间(container)的创建
ApplicationMaster管理计算任务,只有产生了mapreduce计算才会运行ApplicationMaster
负责具体的资源分配
map使用多少
reduce使用多少
1-mapreduce提交计算任务给RM(ResourceManager)
2-RM中的applicationmanager负责创建applicationMaster进程
3-applicationMaster和applicationmanager保持通讯
4-applicationMaster找RM中的ResourceScheduler(资源调度器)申请计算需要的资源
5-applicationMaster通知对应的NodeManger创建资源空间container
6-在资源空间中先运行map阶段的计算,先运行reduce阶段的计算
7-map和reduce运行期间会将自身状态信息汇报给applicationMaster
8-计算完成后,applicationMaster通知NodeManger释放资源
9-资源释放后再通知applicationmanager把自身(applicationMaster)关闭释放资源
yarn的资源调度策略
当有多个计算任务同时请求yarn进行计算,如何分配资源给每个计算任务?
先进先出
谁先抢到资源谁使用所有资源
资源利用效率低
如果遇到一个计算时间较长的任务,保资源占用后。其他的任务就无法计算
容量调度将资源分成多份
不同计算任务使用不同的资源大小
公平调度
资源全部给一个计算任务使用,但是当计算任务中的某个map或reduce计算完成后,可以将自身资源释放掉给其他计算任务使用
5个map,其中有两个map计算完成,就可以先释放掉两个资源,给他任务使用,不同等待所有任务计算完成在释放
三、Hive的语法树
解析器
解析sql关键词转为语法数据
分析器
分析语法格式,字段类型等是否正确
优化器
谓词下推
调整jion和where执行顺序
列值裁剪
执行器
将语法中的逻辑转为mapreduce的计算java代码交给MR执行
四、Hive配置优化
hive中有三种配置方式
配置文件配置
hive的安装目录下的conf目录中的hive-site.xml
全局有效,启动hive后会自动使用配置文件中的配置
文件格式xml
hive指令配置
nohup hive --service hiveserve2 --hiveconf 'hive.exec.dynamic.partition.mode=nostrict' &
set配置
在sql的操作界面设置
set hive.exec.dynamic.partition.mode=nostrict; set hive.exec.dynamic.partition.mode;
优先级: set配置 > hive指令配置 > 配置文件
set配置只在当前操作界面生效,创建新的连接窗口就是失效了
日常开发中为了减少配置信息的影响,谁开发谁设置,采用set方式
hive的配置属性信息 Configuration Properties - Apache Hive - Apache Software Foundation
五、数据开发
数据开发主要分两种
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing)
对数据进行事务操作,保证数据操作的安全性
事务特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
原子性:一个sql语句的执行是不可拆分的,能完整执行得到结果,不被抢占资源
select * from (select * from tb2) tb;
一致性
多表数据写入时,数据是一致性
订单表
小米手机 1
商品表
小米手机 99
隔离性
程序员张三 update from order set stock=old_stock-num where id=1
在更新数据之前会先查询剩余库存的
程序员李四 update from order set stock=90 where id=1
保证每个sql执行的任务是独立的,此时任务就要按顺序执行语句
持久性
数据会持久存储在磁盘上
业务开发使用到数据库都属于联机事务处理业务开发(网站或程序)进行的数据操作对安全性要求比较高,所有采用的数据操作方式是联机事务处理
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing)
大数据的数据开发主要进行的是联机分析处理
对数据进行查询计算,得到结果进行分析
数据一般是一次写入,多次读取
大数据开发不涉及数据的删除,也不修改数据
六、数据仓库
数据仓库就是对公司的过往历史数据进行计算分析,为公司决策提供数据支撑
历史数据的数据量比较大,就需要采用大数据技术实现数据仓库开发
使用HiveSQL对海量数据采用结构化数据方式进行计算
数仓开发本质就是将文件数据转为了结构化数据进行分析计算的
数仓特征
面向主题的(Subject-Oriented )
根据分析内容采集相关数据进行计算
每个分析方向就是一个主题
集成的(Integrated)
将相关主题的数据收集在一起进行计算,形成一个大的宽表
销售主题开发
订单表,订单商品表,订单评价,退款订单表
非易失的(Non-Volatile)
数仓数据不容易丢失,也不会进行删除和修改
时变的(Time-Variant )
随着分析需求的改变,数仓中的数据也在不断变化,随着时间推移,统计的字段计算数据也在发生变化
用户表 用户名,用户性别,用户年龄,用户地址,用户手机号
七、数据仓库开发流程
设计主题计算需求
数据分析师或者数据产品经理
数据来源
Mysql中的业务数据
文件数据 excel文件,csv文件,json,log
采集数据源数据
kettle
sqoop
datax
代码采集
对采集的数据进行清洗转化,将处理的后的数据写入到hdfs中
数据采集时单独岗位
ETL开发工程师
数据的计算
mapreduce --> hiveSQL
spark
flink
数据计算和结果保存属于数仓开发岗
将计算的结果数据存储到指定位置
hdfs
habse
es
Mysql
数据计算和结果保存属于数仓开发岗
对结果数据进行BI展示
fineBI
powerBI
superset
BI工程师

八、数仓分层
将数据的计算过程拆分成多个部分就是数仓分层
分层实现就是创建不同数据库
数仓最基本的三个分层
ODS(old data service)保存原始数据,采集清洗后的数据会被写入ods层
create databases ods;
DW(Data WareHouse)
数仓开发层,对数据进行计算
create databases dw;
APP(application)结果数据层
不同主题下的数据保存在对应表目录下
create databases app;
对dw层可以进行分层的拆分
dwb 基础数据 在这一层进行数据的过滤
dwd 数据详情层 进行数据的关联
对数据的计算流程拆分后,形式一个完成数据开发流程,在流程中的每个关节都可以单独进行开发
select gender,avg(age) from tb1 join tb2 where dt = 2021-10-10 group by gender 1-数据的过滤 insert into tb1_where select * from tb1 where dt = 2021-10-10 insert into tb2_where select * from tb2 where dt = 2021-10-10 insert into tb1_where select * from tb1 where age > 20 insert into tb2_where select * from tb2 where name='张三' 2-关联表数据据 -- 新的表中保存了关联后的所有数据 insert into tb1_tb2_where select * from tb1_where join tb2_where 3-数据分组计算 select gender,avg(age) from tb1_tb2_where group by gender select city,avg(age) from tb1_tb2_where group by city
九、ETL和ELT
extract 数据抽取
transform 数据清洗转化
load 数据的导入
ETL 属于数据采集工作 通过采集工具采集的对应的数据内容,对内容清洗转化,在将清洗转化后的数据写入hdfs
ELT是将etl的开发流程进行了调整,使用采集工具采集数据,将数据直接写入hdfs,清洗转化过程可以使用hiveSQL在数仓中执行