一、垂直拆分
1、场景概述:
在业务系统中,由于用户与订单每天都会产生大量的数据,单台服务器的数据存储及处理能力是有限的,可以对数据库表进行进行垂直分库操作。将商品相关的表拆分到一个数据库服务器,订单表拆分到一个数据库服务器,用户及省市区表拆分到一个服务器。
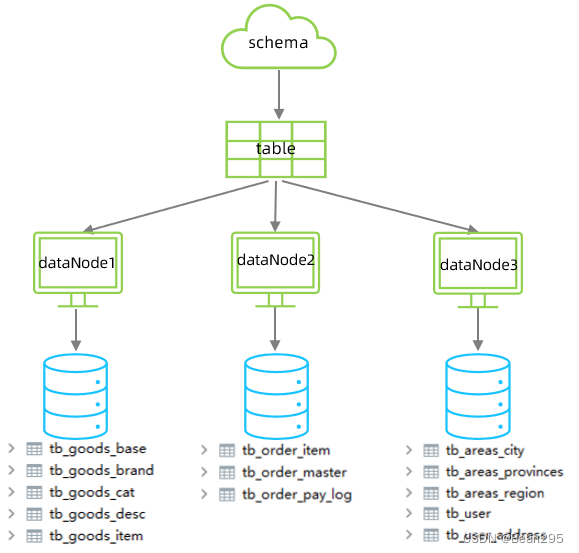
2、配置:
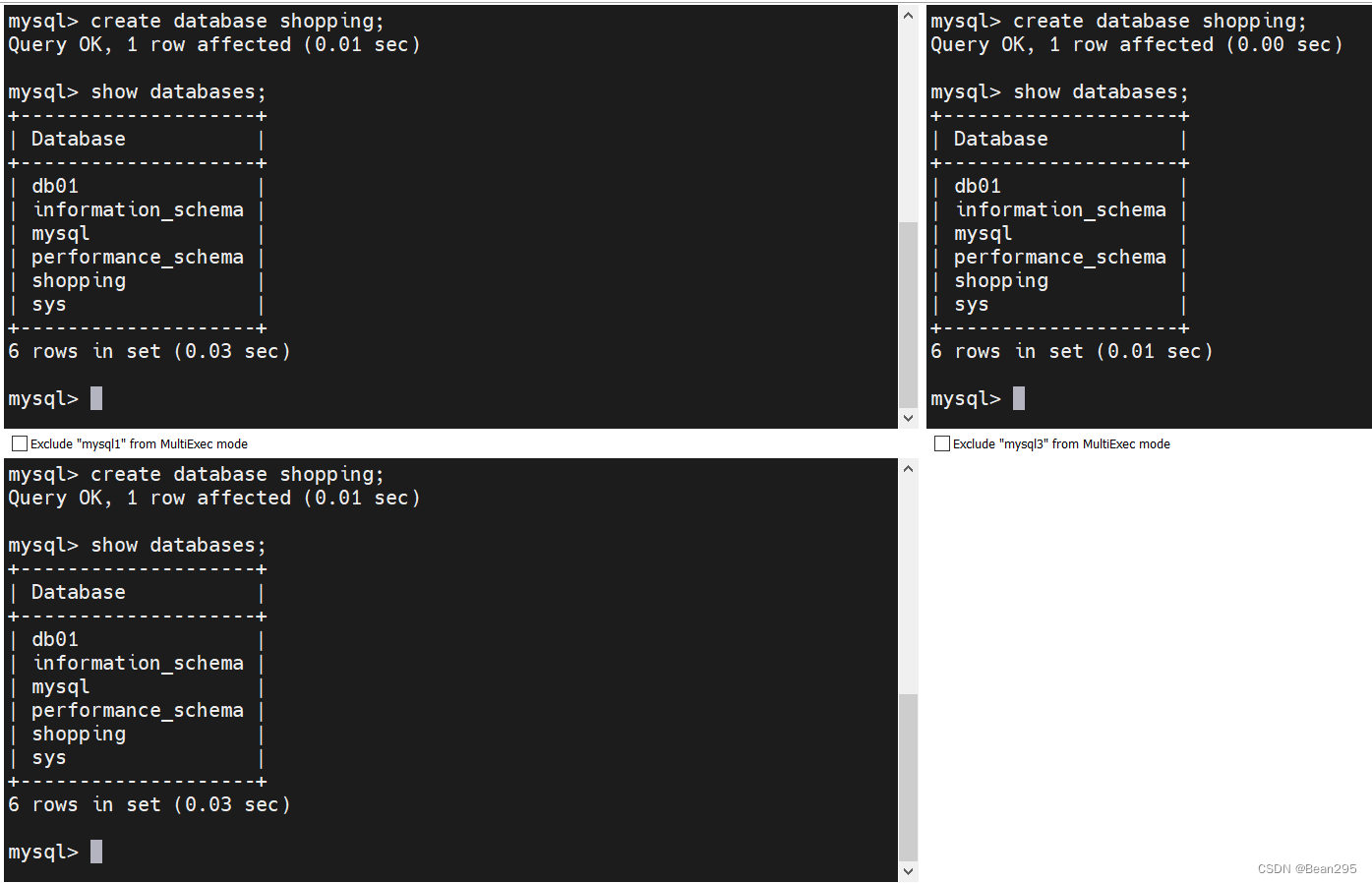
分别在三台数据库服务器中创建shopping库。
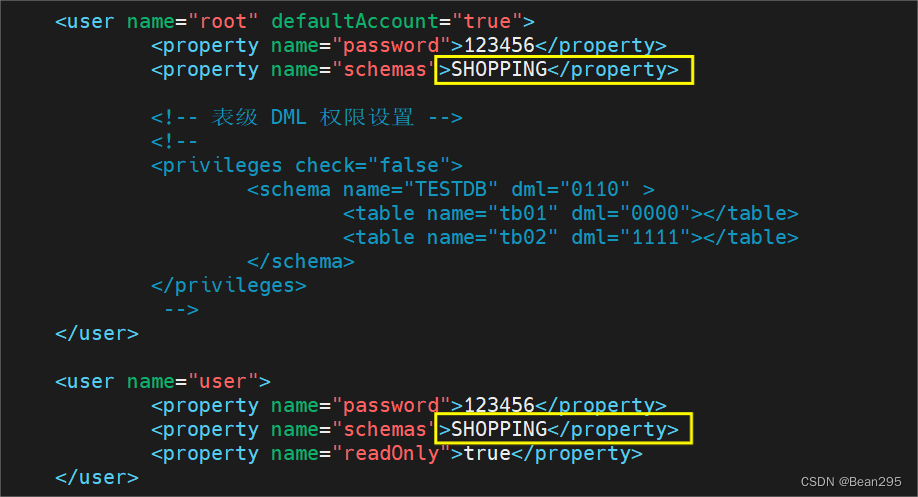
(1) 配置 schema.xml:
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_goods_base" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_brand" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_cat" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id" />
<table name="tb_goods_item" dataNode="dn1" primaryKey="id" />
<table name="tb_order_item" dataNode="dn2" primaryKey="id" />
<table name="tb order master" dataNode="dn2" primaryKey="order_id" />
<table name="tb_order_pay log" dataNode="dn2" primaryKey="out_trade_no" />
<table name="tb_user" dataNode="dn3" primaryKey="id" />
<table name="tb_user_address" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_provinces" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_city" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_region" dataNode="dn3" primaryKey="id" />
</schema>
<dataNode name="dn1" dataHost="dhost1" database="shopping" />
<dataNode name="dn2" dataHost="dhost2" database="shopping" />
<dataNode name="dn3" dataHost="dhost3" database="shopping" />

(2) 配置 server.xml:
3、测试:
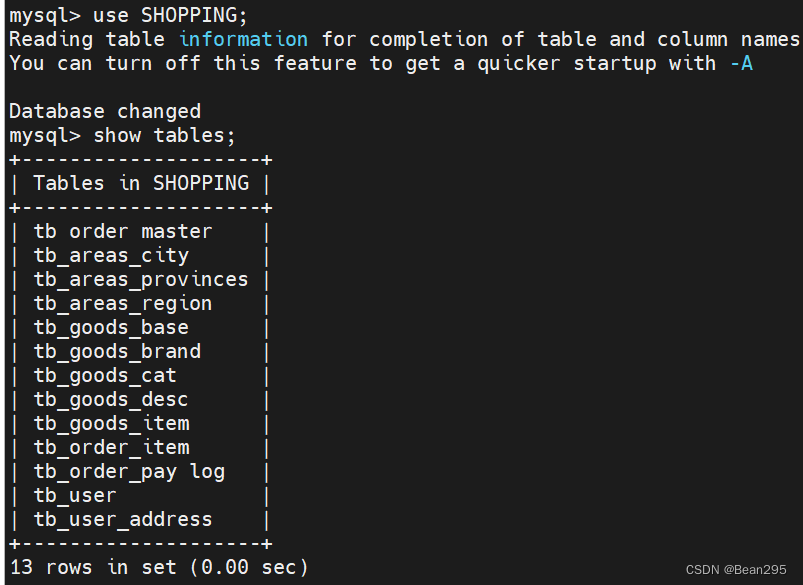
(1) 启动 mycat:
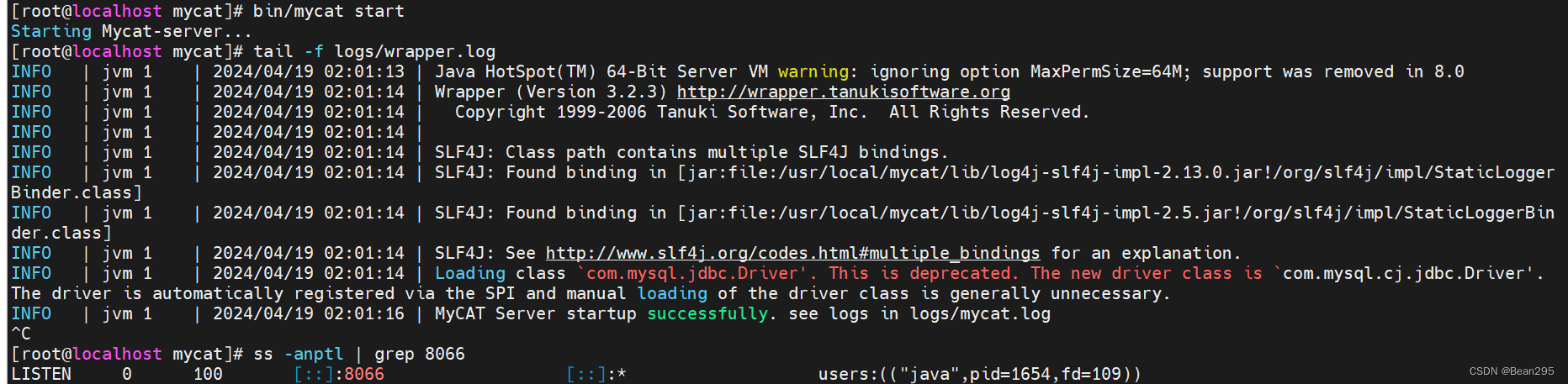

可以查看到所定义的逻辑表:
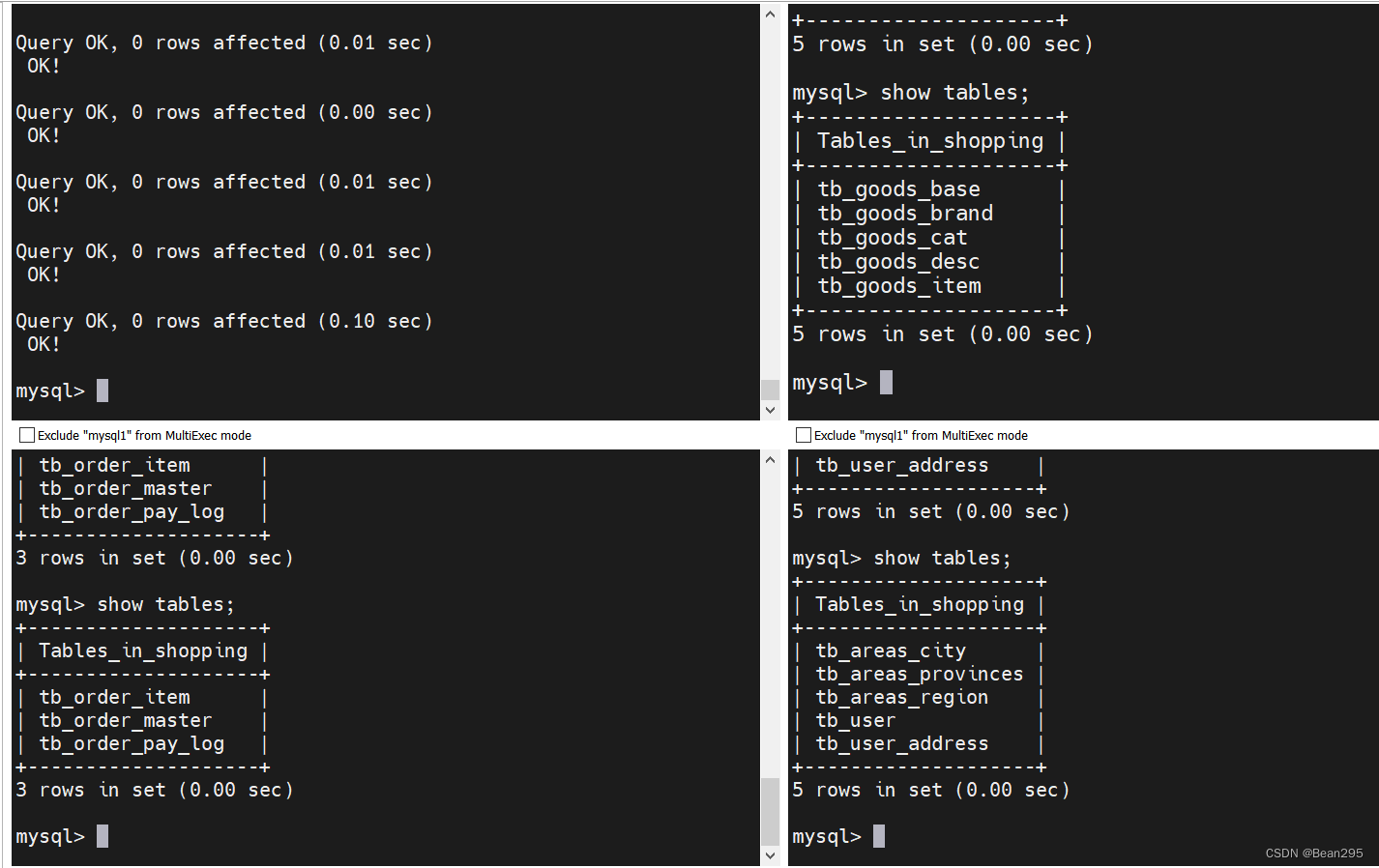
(2) 创建数据表并插入数据:
现在只是在mycat上创建了逻辑表,真实的数据库中还并未存在这些表。
在mycat中通过source指令导入表结构,以及对应的数据:
source /root/shopping-table.sql
source /root/shopping-insert.sql
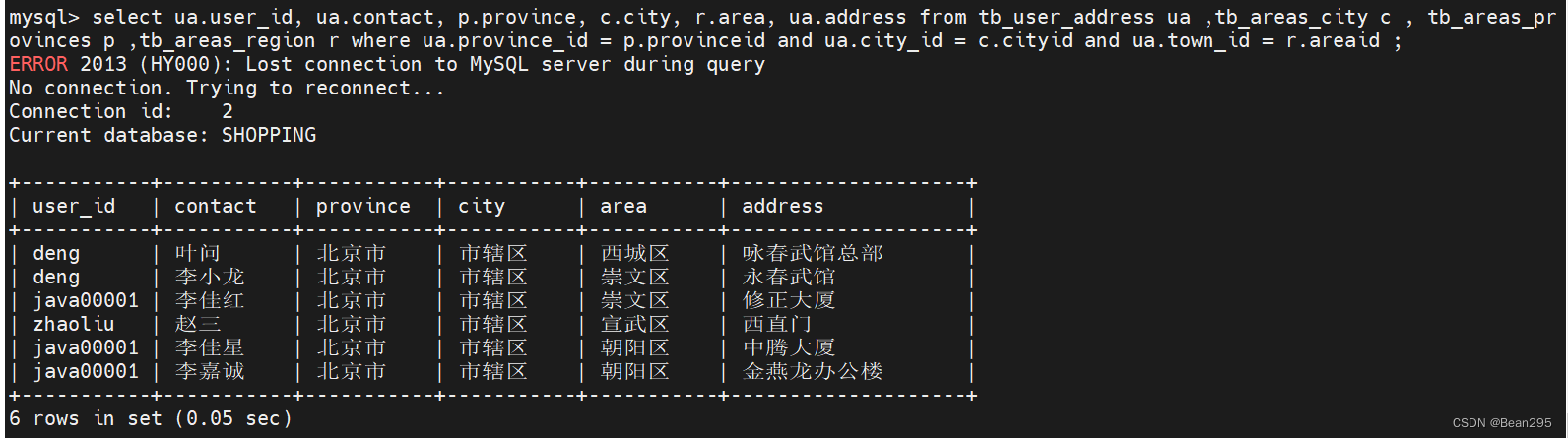
(3) 多表联查:
需求:查询用户的收件人及收件人地址信息(包含省、市、区)。
tb_user_address 表中关联的省市区都是id值,想要展示具体的信息,就需要多表查询。
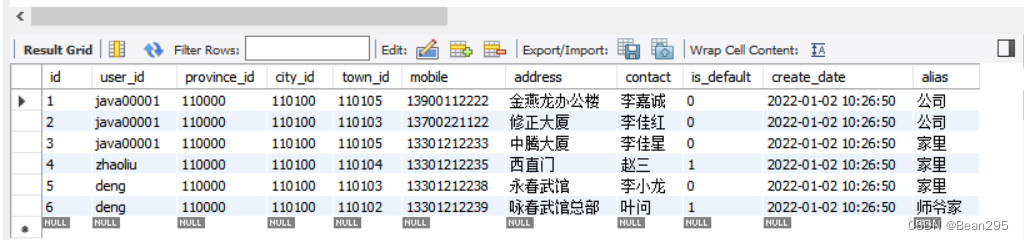
province_id、city_id、town_id 分别关联 tb_areas_provinces、tb_areas_city、tb_areas_region 三张表。
select ua.user_id, ua.contact, p.province, c.city, r.area, ua.address from tb_user_address ua ,tb_areas_city c , tb_areas_provinces p ,tb_areas_region r where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id = r.areaid ;
● tb_user_address ua ,tb_areas_city c , tb_areas_provinces p ,tb_areas_region r:给查询的表设置别名;
● select ua.user_id, ua.contact, p.province, c.city, r.area, ua.address:查询字段;
● where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id = r.areaid:联查条件。
(4) 全局表:
当多表联查的表分布在不同的分片服务器中时,mycat多表联查会失败,需要将多个业务模块中都使用的表设置为全局表。

● 修改 schema.xml:
将这三张表都放入到三个节点中,type="global" 设置为全局表。

● 重新设置表结构:
先停止mycat,并清空三个分片服务器shopping库下的所有表:

重启启动mycat,执行之前的两个sql脚本(创建表结构、插入数据)


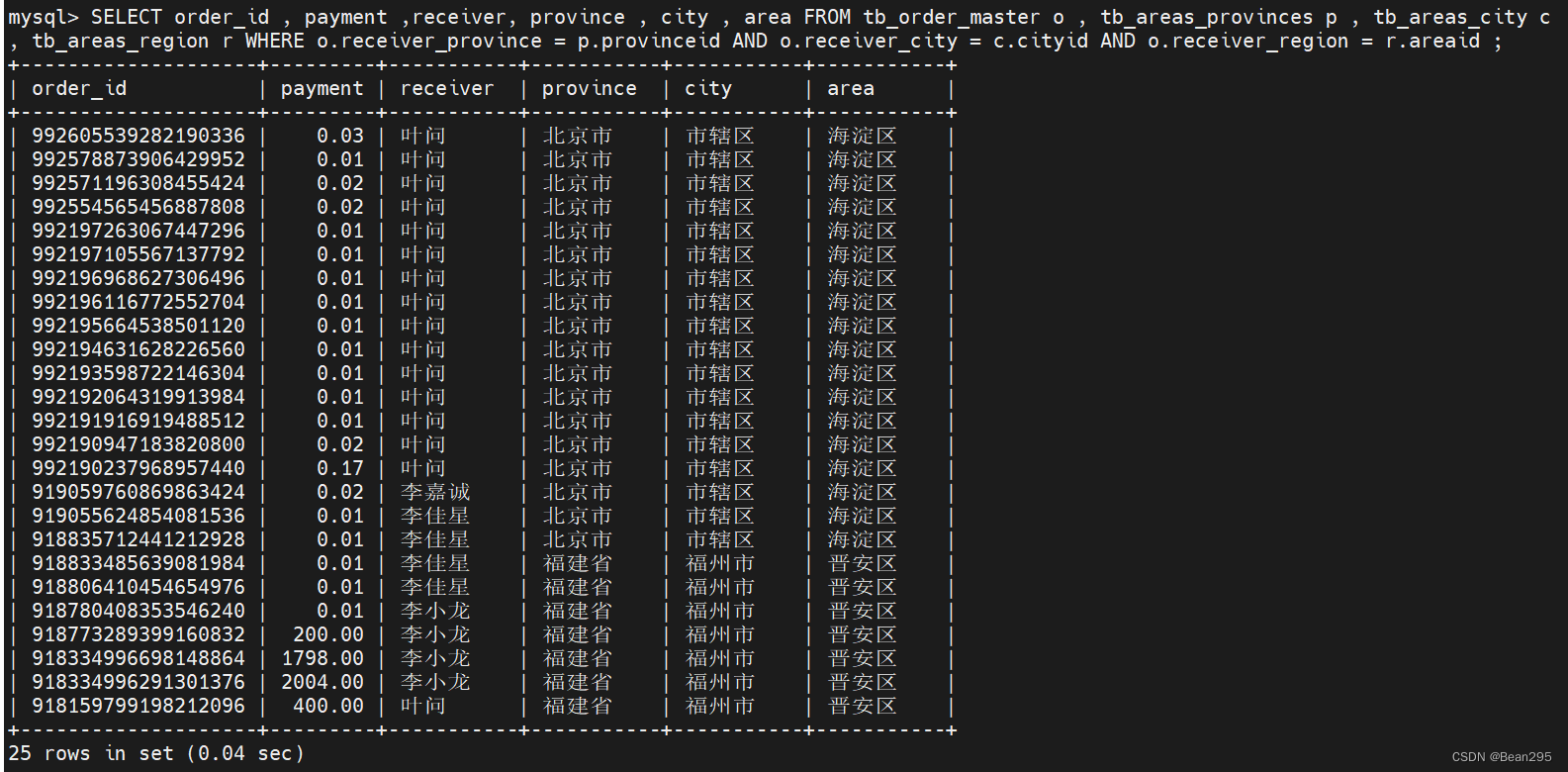
需求:查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o , tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND o.receiver_region = r.areaid ;
二、水平拆分
1、场景概述:
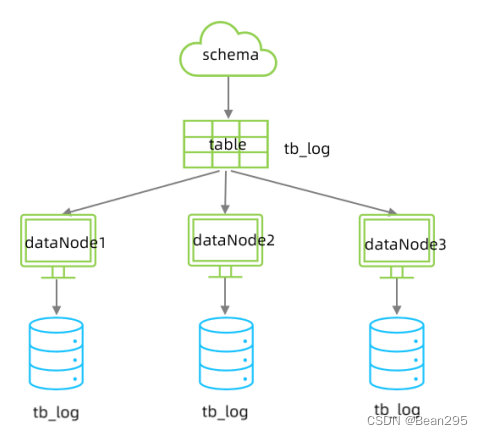
在业务系统中, 有一张表(日志表),业务系统每天都会产生大量的日志数据,单台服务器的数据存储及处理能力是有限的,可以对数据库表进行拆分。
2、配置:
先在三台数据库服务器中分表创建一个数据库itcast。
(1) 配置 schema.xml 和 server.xml:
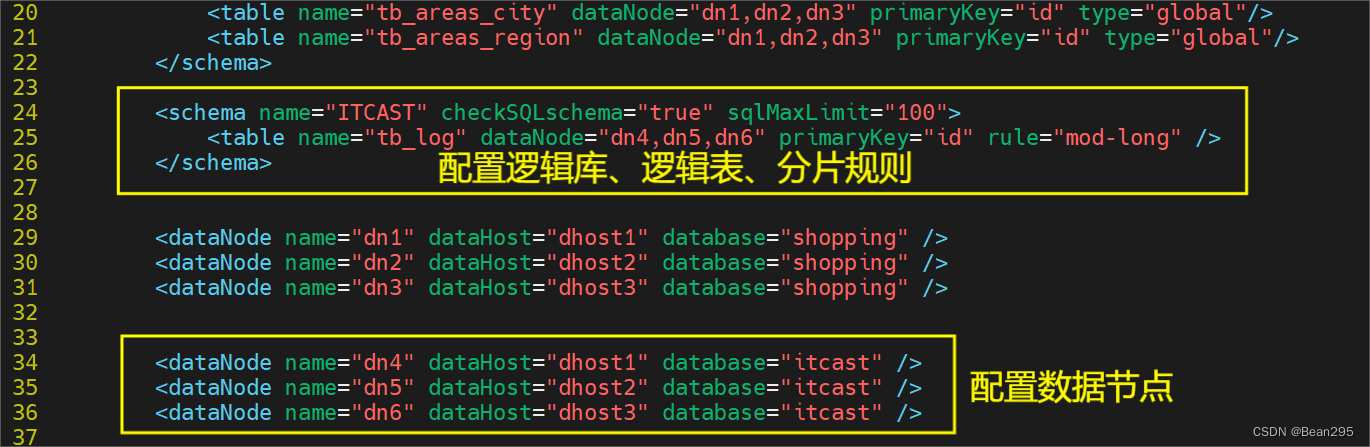
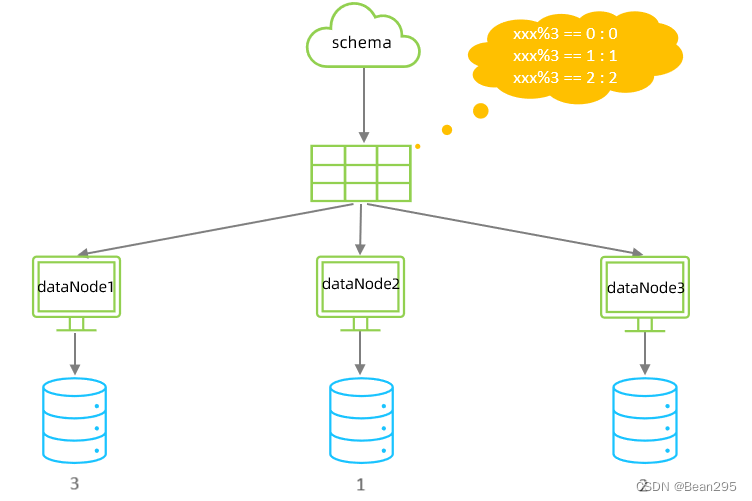
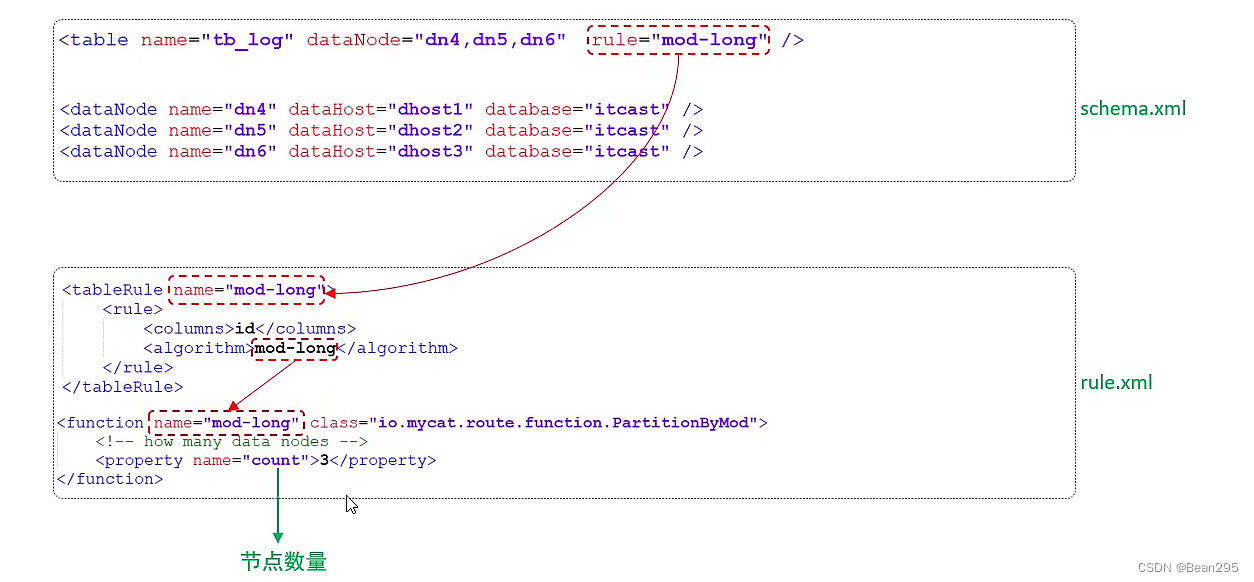
● mod-long:
根据主键id求模,有三个分片节点,则模3,将id分散在三个节点中。

(2) 测试:
重新启动mycat:
创建表结构,插入数据:
source /root/tb_log_table.sql
source /root/tb_log_insert.sql
三、分片规则
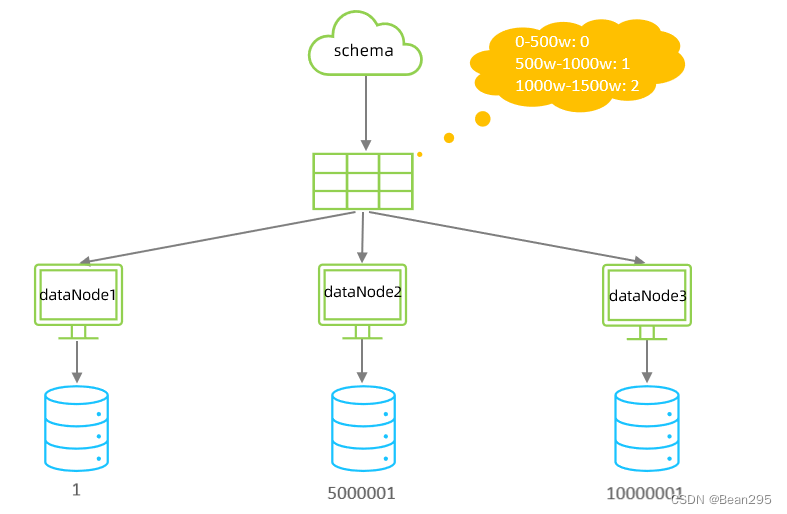
1、范围分片:
根据指定的字段及其配置的范围与数据节点的对应情况,来决定该数据属于哪一个分片。

2、取模分片:
根据指定的字段值与节点数量进行求模运算,根据运算结果决定该数据属于哪一个分片。
3、一致性hash分片:
(1) 介绍:
一致性哈希是指相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置。

(2) 测试:
① 修改 rule.xml:
设置分片数据库节点数量为3。

② 修改 schema.xml:
添加逻辑表和分片规则。

③ 启动mycat,创建表结构,插入数据:
插入表结构:
create table tb_order(
id varchar(100) not null primary key,
money int null,
content varchar(200) null
);

插入数据,查看数据分布情况:
INSERT INTO tb_order (id, money, content) VALUES ('b92fdaaf-6fc4-11ec-b831-482ae33c4a2d', 10, 'b92fdaf8-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93482b6-6fc4-11ec-b831-482ae33c4a2d', 20, 'b93482d5-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b937e246-6fc4-11ec-b831-482ae33c4a2d', 50, 'b937e25d-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93be2dd-6fc4-11ec-b831-482ae33c4a2d', 100, 'b93be2f9-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93f2d68-6fc4-11ec-b831-482ae33c4a2d', 130, 'b93f2d7d-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9451b98-6fc4-11ec-b831-482ae33c4a2d', 30, 'b9451bcc-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9488ec1-6fc4-11ec-b831-482ae33c4a2d', 560, 'b9488edb-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b94be6e6-6fc4-11ec-b831-482ae33c4a2d', 10, 'b94be6ff-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b94ee10d-6fc4-11ec-b831-482ae33c4a2d', 123, 'b94ee12c-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b952492a-6fc4-11ec-b831-482ae33c4a2d', 145, 'b9524945-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95553ac-6fc4-11ec-b831-482ae33c4a2d', 543, 'b95553c8-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9581cdd-6fc4-11ec-b831-482ae33c4a2d', 17, 'b9581cfa-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95afc0f-6fc4-11ec-b831-482ae33c4a2d', 18, 'b95afc2a-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95daa99-6fc4-11ec-b831-482ae33c4a2d', 134, 'b95daab2-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9667e3c-6fc4-11ec-b831-482ae33c4a2d', 156, 'b9667e60-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b96ab489-6fc4-11ec-b831-482ae33c4a2d', 175, 'b96ab4a5-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b96e2942-6fc4-11ec-b831-482ae33c4a2d', 180, 'b96e295b-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b97092ec-6fc4-11ec-b831-482ae33c4a2d', 123, 'b9709306-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b973727a-6fc4-11ec-b831-482ae33c4a2d', 230, 'b9737293-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b978840f-6fc4-11ec-b831-482ae33c4a2d', 560, 'b978843c-6fc4-11ec-b831-482ae33c4a2d');
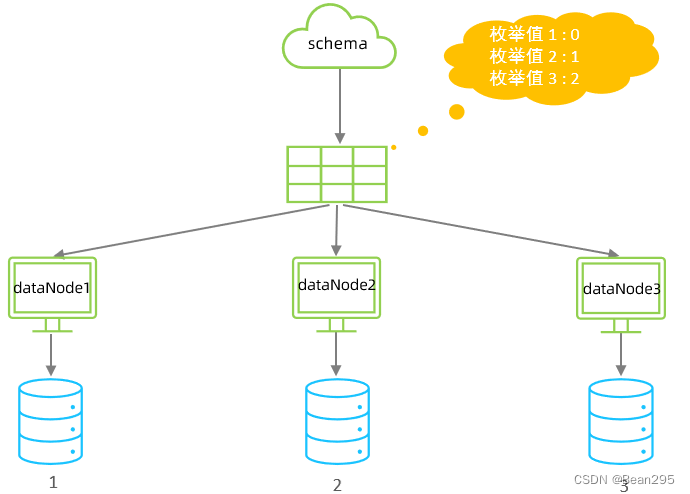
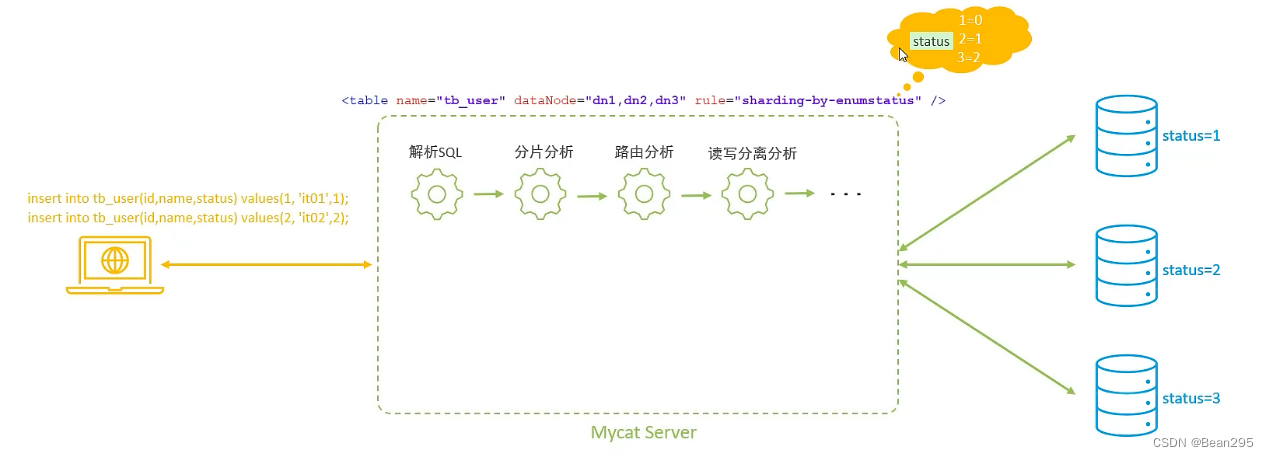
4、枚举分片:
(1) 介绍:
枚举分片适用于具有固定或有限数量枚举值作为分片依据的场景。这种分片方法基于预先定义好的枚举列表,将数据分配到不同的数据库或表中,确保每个枚举值对应的数据被存储在特定的分片上。
枚举分片常用于处理那些枚举类型的属性(如省份、城市、性别等)。

(2) 测试:
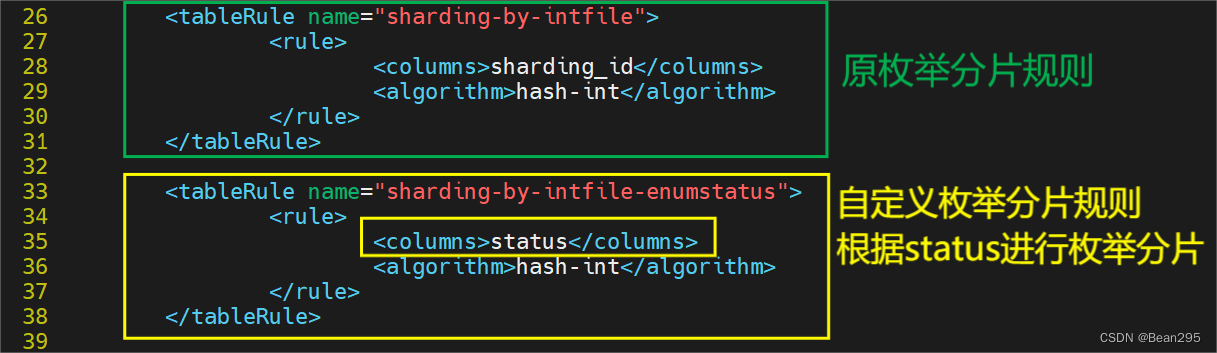
① 修改 rule.xml:
枚举函数:
partition-hash-int.txt 这个文本定义了枚举值与数据节点索引的对应情况,可根据具体的表修改文本。
根据status值进行枚举分片,状态为1分配到第一台数据库 (索引为0),状态为2分配到第二台数据库,状态为3分配到第三台数据库。
枚举值=数据节点索引

② 修改 schema.xml:
设置逻辑表和分片规则。

③ 启动mycat,创建表结构并插入数据:

创建表结构,插入数据:
CREATE TABLE tb_user (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未启用, 2: 已启用, 3: 已关闭',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;

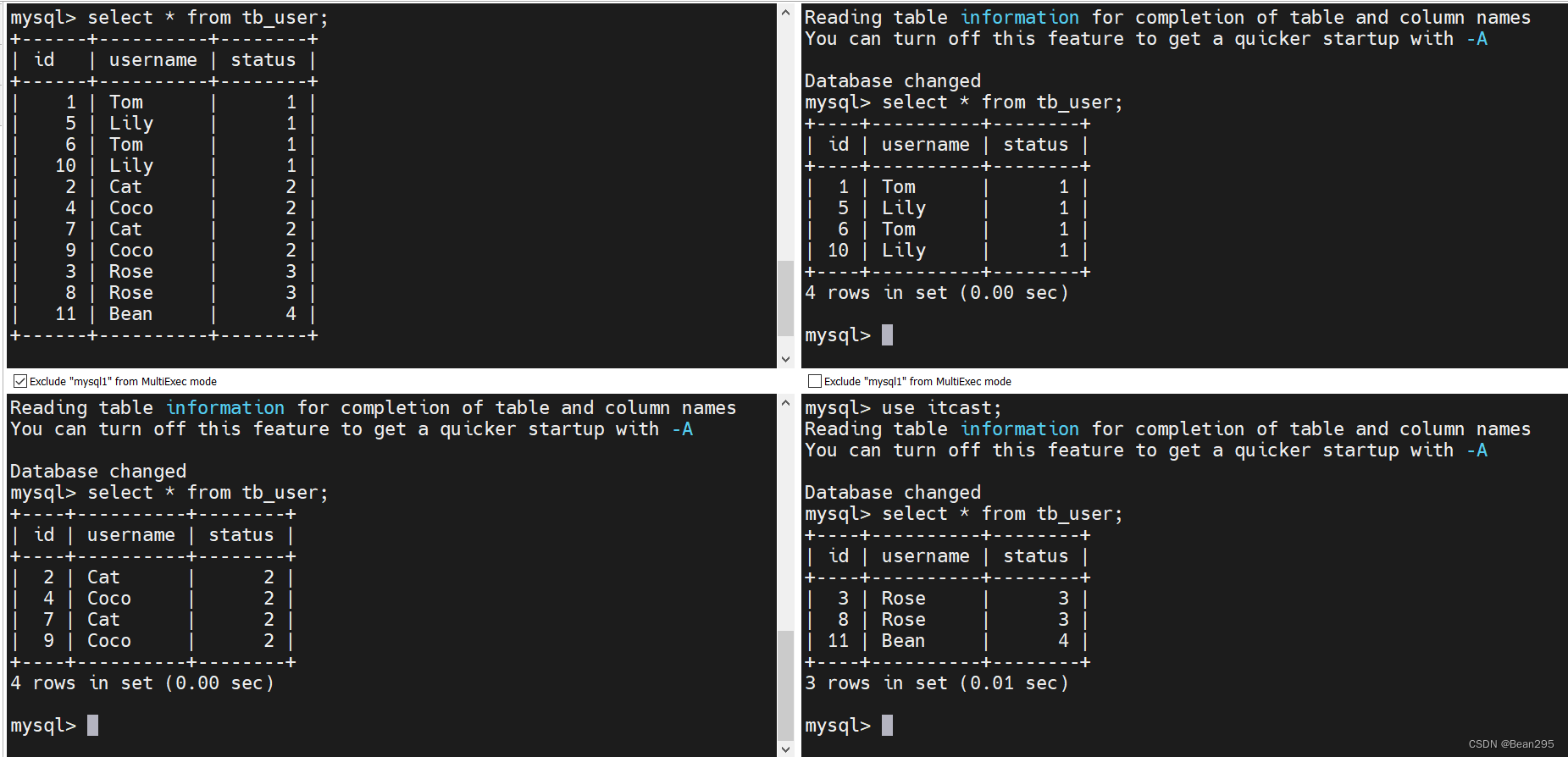
insert into tb_user (id,username ,status) values(1,'Tom',1);
insert into tb_user (id,username ,status) values(2,'Cat',2);
insert into tb_user (id,username ,status) values(3,'Rose',3);
insert into tb_user (id,username ,status) values(4,'Coco',2);
insert into tb_user (id,username ,status) values(5,'Lily',1);
insert into tb_user (id,username ,status) values(6,'Tom',1);
insert into tb_user (id,username ,status) values(7,'Cat',2);
insert into tb_user (id,username ,status) values(8,'Rose',3);
insert into tb_user (id,username ,status) values(9,'Coco',2);
insert into tb_user (id,username ,status) values(10,'Lily',1);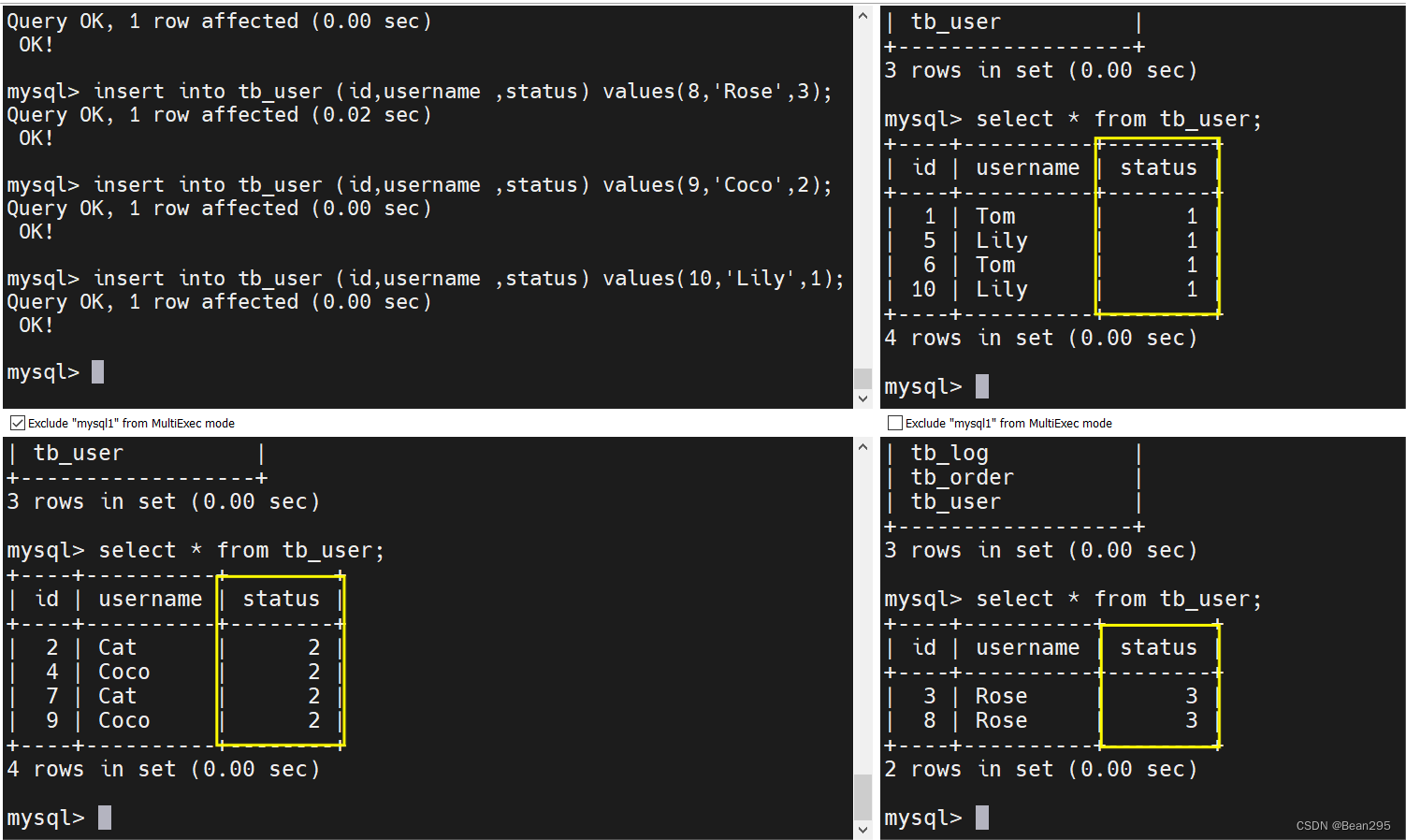
④ 默认节点:
如果枚举值不在预设的枚举值之中,则插入数据会报错,因此需要设置默认节点来存放这些数据。

在 rule.xml 中设置默认节点并重启mycat:
如果找不到枚举值与数据库节点的对应关系,则将该数据存储到索引值为2的数据库节点中。



5、应用指定算法:
(1) 介绍:
应用指定算法分片是指由应用程序自身直接控制和决定数据,按照特定算法分配到各个分片上的策略(定制化分片逻辑)。
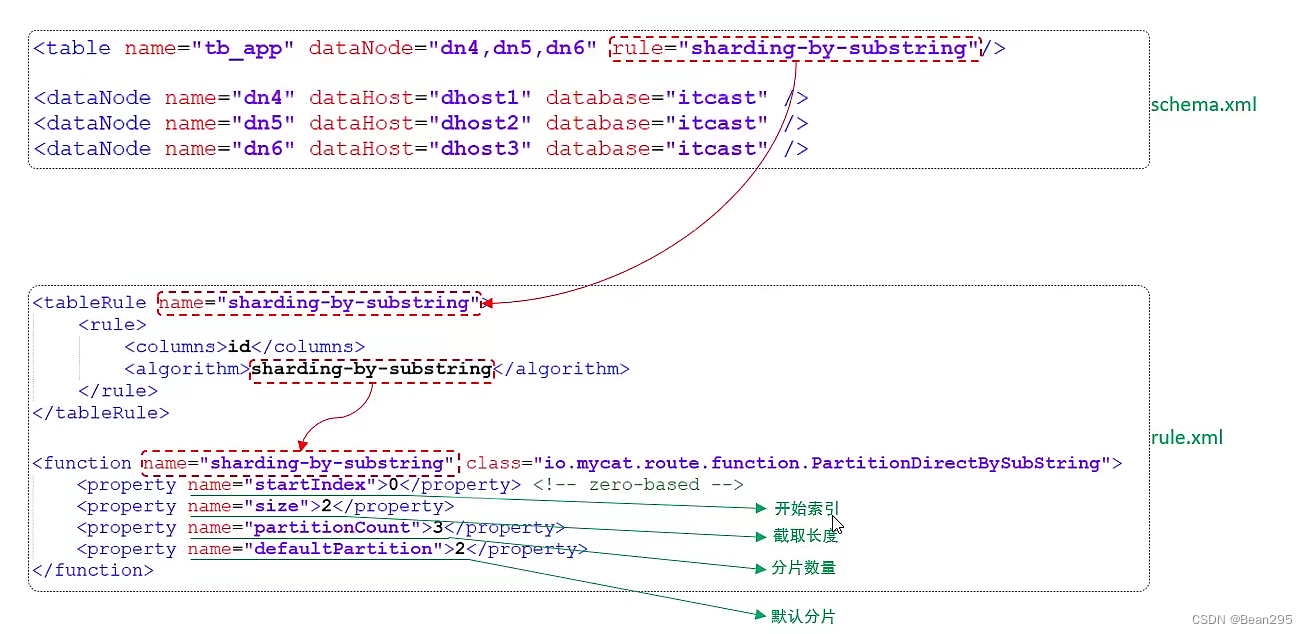
(2) 测试:
① 修改 rule.xml:
rule.xml 中的默认规则没有这一条,需要手动添加。
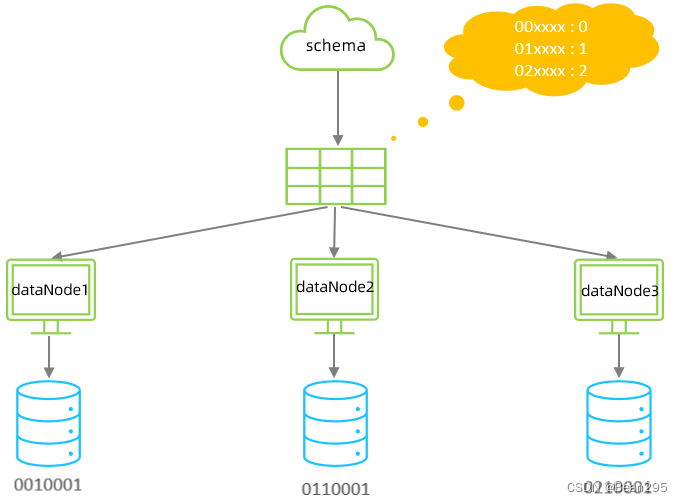
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">0</property>
</function>
"startIndex" 0:从索引为0处开始截取 (从头截取)
"size" 2:截取长度为2
"partitionCount":分片节点数
"defaultPartition":默认节点

<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>

② 修改 schema.xml:

③ 启动mycat,创建表结构,插入数据:
CREATE TABLE tb_app (
id varchar(10) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_app (id,name) values('0000001','Testx00001');
insert into tb_app (id,name) values('0100001','Test100001');
insert into tb_app (id,name) values('0100002','Test200001');
insert into tb_app (id,name) values('0200001','Test300001');
insert into tb_app (id,name) values('0200002','TesT400001');
insert into tb_app (id,name) values('0400002','TesT500001');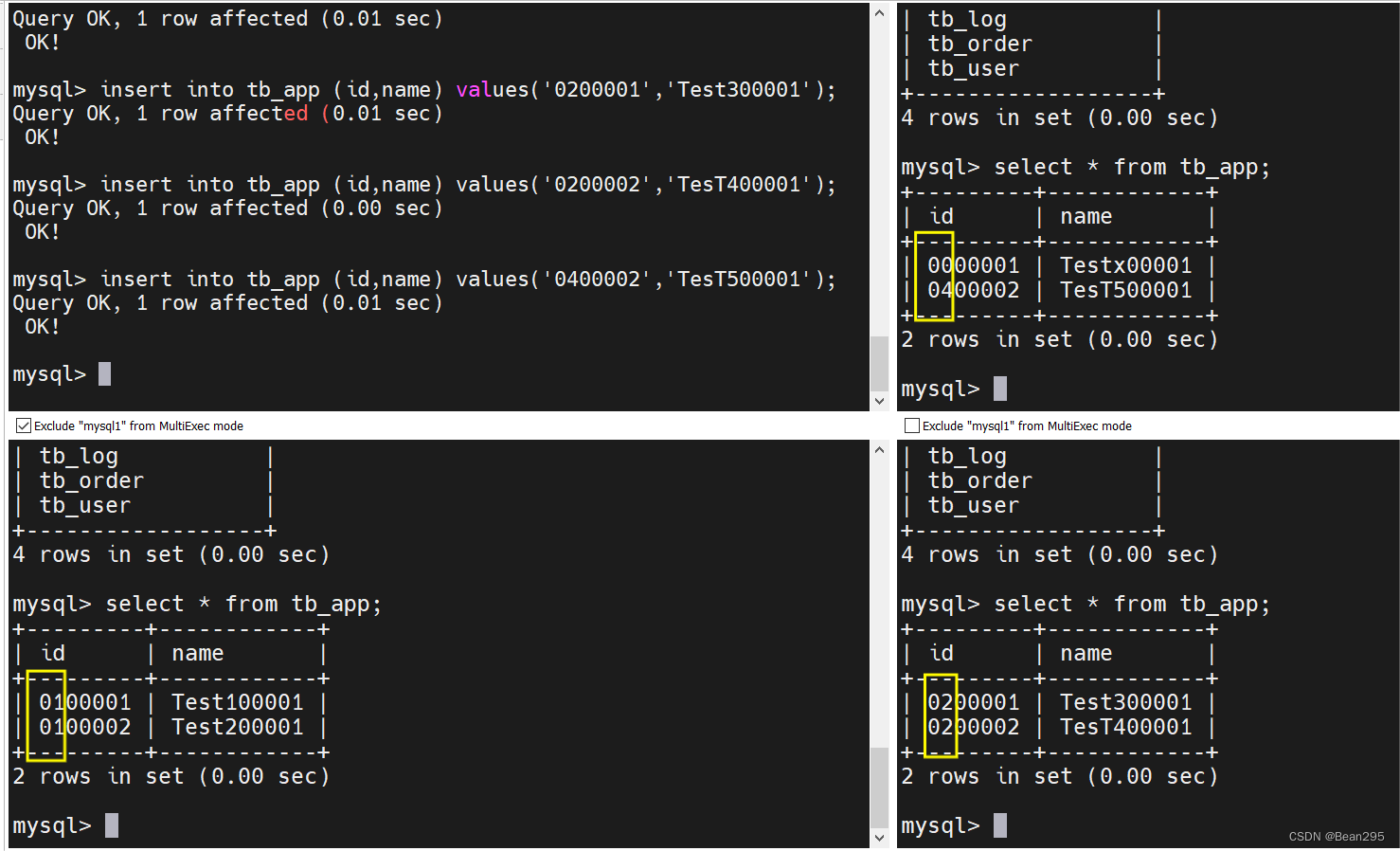
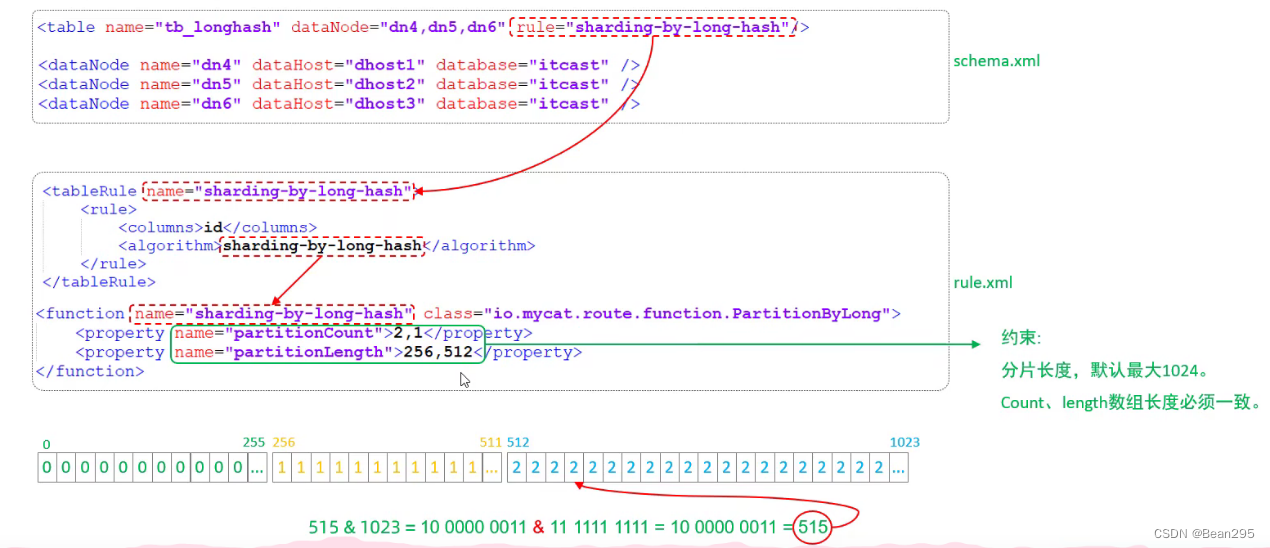
6、固定分片hash算法:
(1) 介绍:
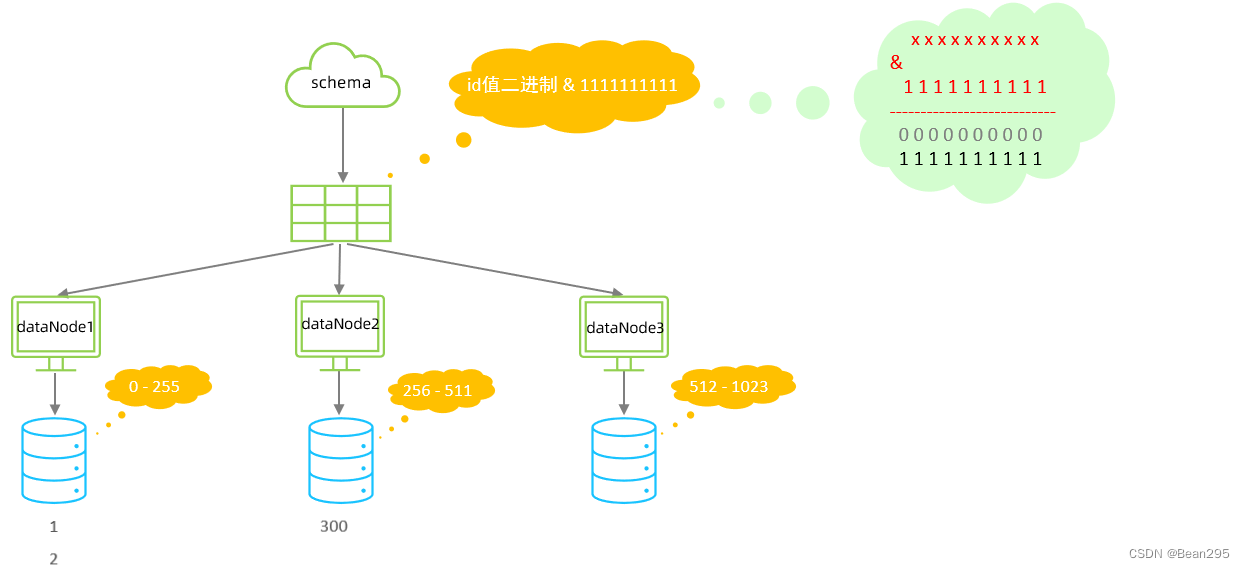
二进制的求模运算,例如,取 id 的二进制 10 位与 1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十进制,也就是位于0-1023之间。
● 位与(&)运算:两个操作数对应位置上的二进制位都是1,则结果位为1。否则,结果位为0。
(2) 特点:
① 与范围分片相比:范围分片指定的字段不能超过范围设定值 ;固定分片hash算法则没有范围限制;
② 与取模分片相比:取模分片如果节点数改变,重新取模后数据存储位置可能会改变 ;固定分片hash会将连续的值可能分配到相同的分片。
(3) 测试:
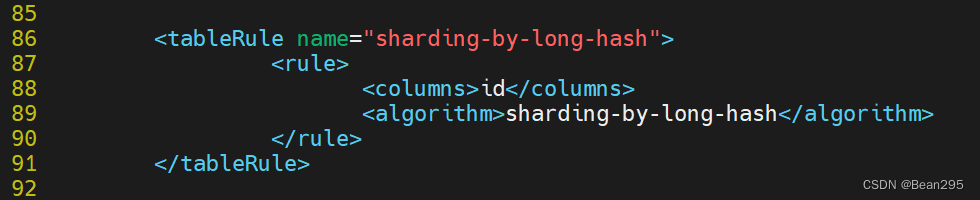
① 修改 rule.xml:
将原分片方式名"fun1"改成"sharding-by-long-hash" ;有三个节点,前两个节点长度为256,第三个节点长度为512。(固定分片hash算法可以均匀分配,也可以非均匀分配)

② 修改 schema.xml:

③ 启动mycat,创建表结构,插入数据:
CREATE TABLE tb_longhash (
id int(11) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
firstChar char(1) COMMENT '首字母',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_longhash (id,name,firstChar) values(1,'七匹狼','Q');
insert into tb_longhash (id,name,firstChar) values(2,'八匹狼','B');
insert into tb_longhash (id,name,firstChar) values(3,'九匹狼','J');
insert into tb_longhash (id,name,firstChar) values(4,'十匹狼','S');
insert into tb_longhash (id,name,firstChar) values(5,'六匹狼','L');
insert into tb_longhash (id,name,firstChar) values(6,'五匹狼','W');
insert into tb_longhash (id,name,firstChar) values(7,'四匹狼','S');
insert into tb_longhash (id,name,firstChar) values(8,'三匹狼','S');
insert into tb_longhash (id,name,firstChar) values(9,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(269,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(889,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(1024,'两匹狼','L');
7、字符串hash算法:
(1) 介绍:
截取字符串中的指定位置的子字符串, 进行hash算法,算出分片。
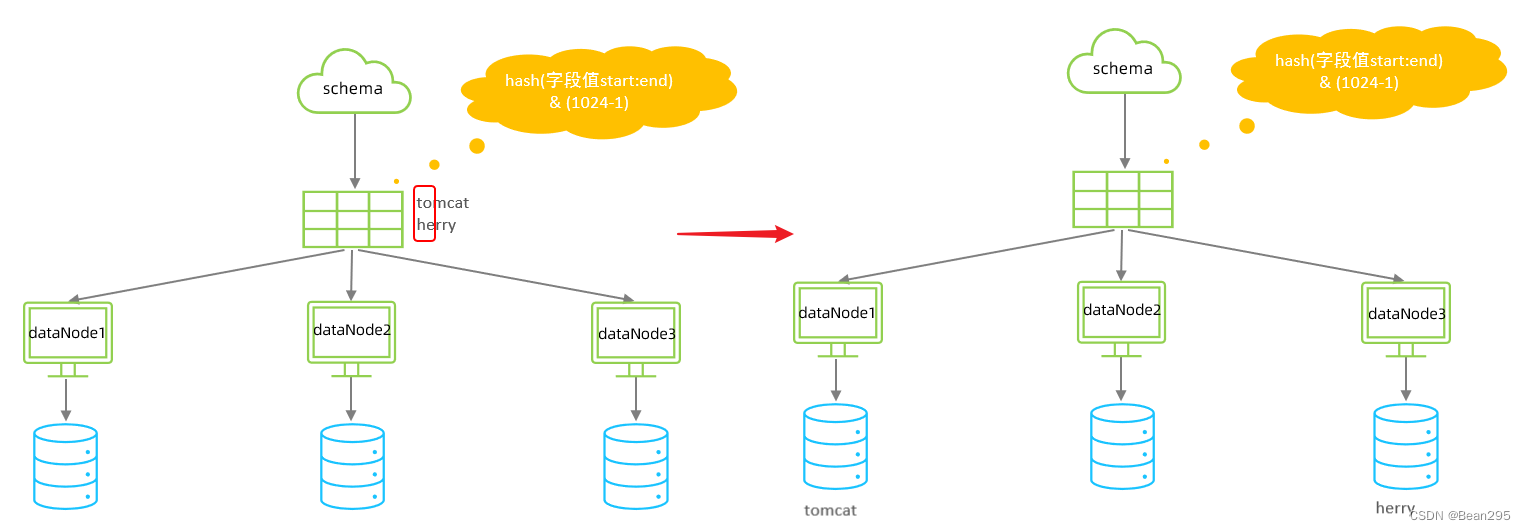

(2) 测试:
① 修改 rule.xml:
一共有两个分片节点,每个分片节点长度为512,截取从索引0到索引2的指定字符串进行hash。
<function name="sharding-by-stringhash" class="io.mycat.route.function.PartitionByString">
<property name="partitionLength">512</property> <!-- zero-based -->
<property name="partitionCount">2</property>
<property name="hashSlice">0:2</property>
</function>

<tableRule name="sharding-by-stringhash">
<rule>
<columns>name</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>

② 修改 schema.xml:

③ 启动mycat,创建表结构,插入数据:

create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());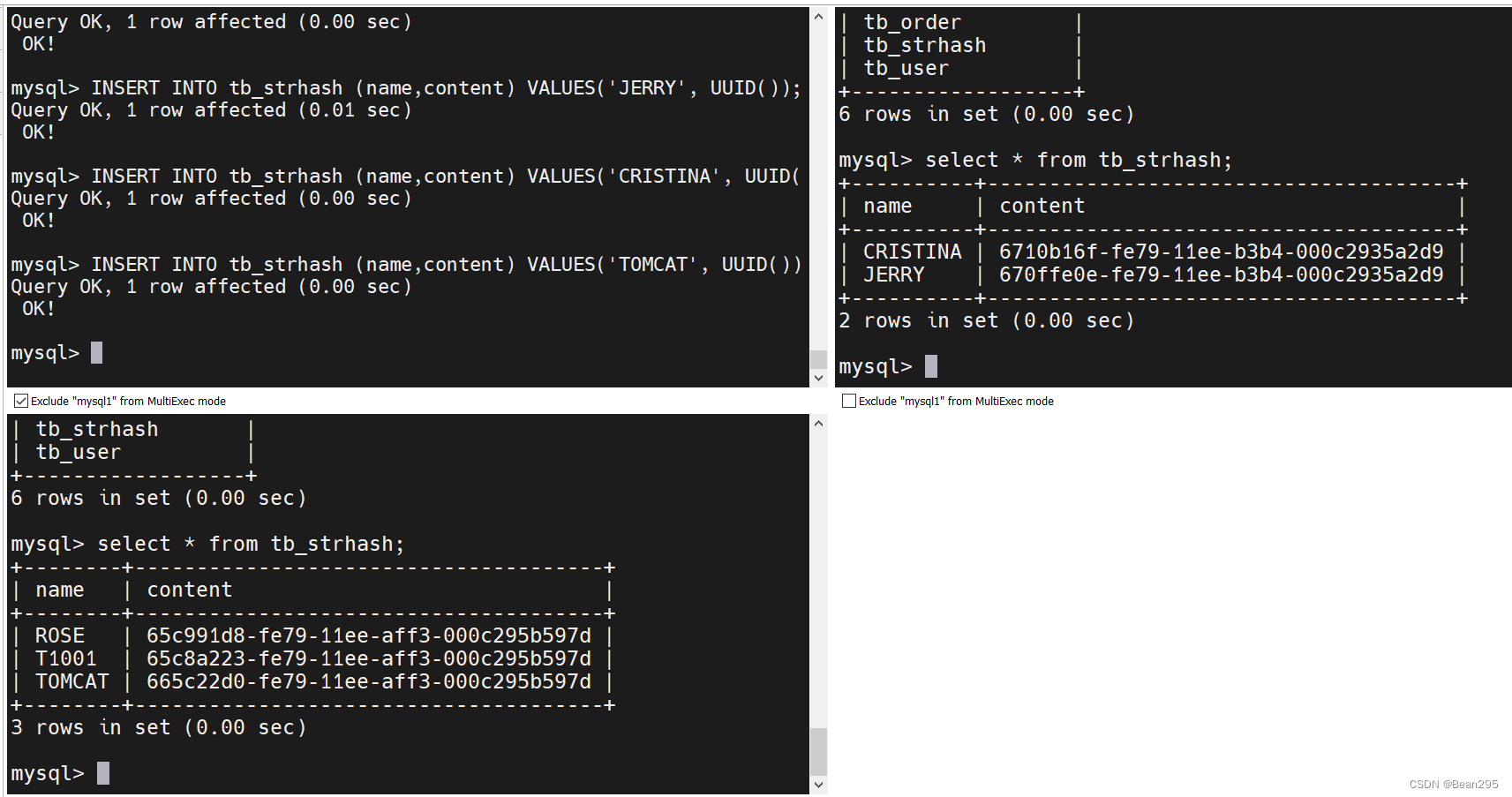
8、按天分片算法:
(1) 介绍:
按天分片算法是将大量数据根据其时间按天进行分割,并将这些分割后的数据分布存储在不同的物理数据节点中。
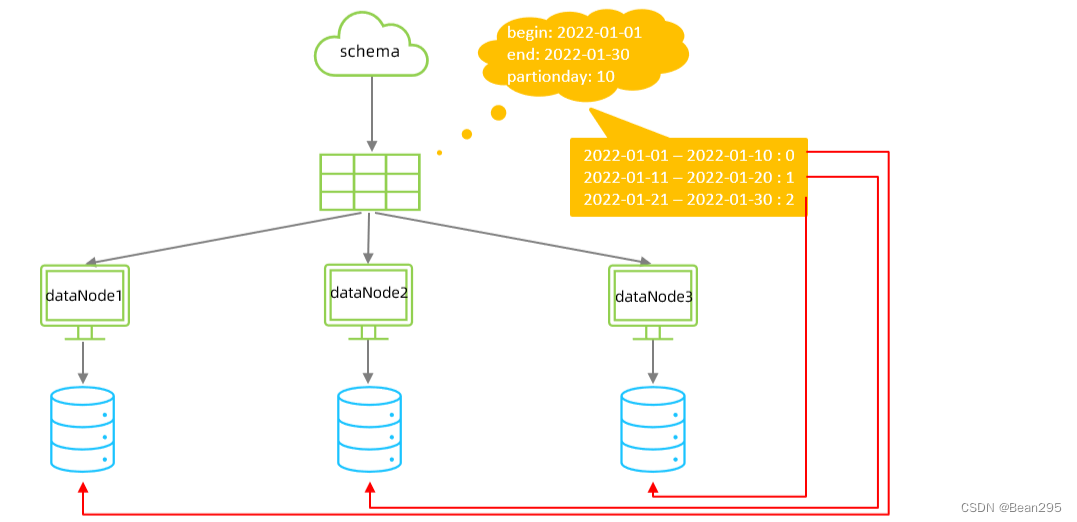
到达结束时间后会,重复开始分片插入:例如2022-01-31的数据会插入到dn4节点中,按照预设的分片方式继续分配数据。
(2) 测试:
① 修改 rule.xml:
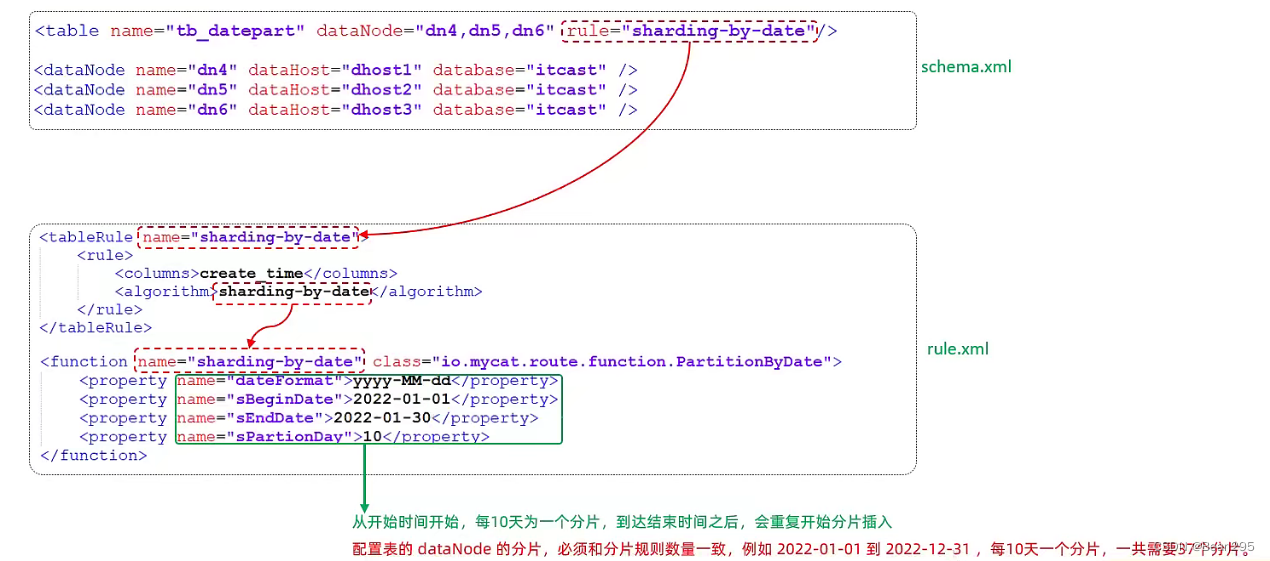
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2022-01-01</property>
<property name="sEndDate">2022-01-30</property>
<property name="sPartionDay">10</property>
</function>
dateFormat:日期格式 ;sBeginDate、sEndDate:开始、结束日期 ;
sPartionDay:分片时间间隔,以10天作为一个分片。

<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>

② 修改 schema.xml:

③ 启动mycat,创建表结构,插入数据:

create table tb_datepart(
id bigint not null comment 'ID' primary key,
name varchar(100) null comment '姓名',
create_time date null
);
insert into tb_datepart(id,name ,create_time) values(1,'Tom','2022-01-01');
insert into tb_datepart(id,name ,create_time) values(2,'Cat','2022-01-10');
insert into tb_datepart(id,name ,create_time) values(3,'Rose','2022-01-11');
insert into tb_datepart(id,name ,create_time) values(4,'Coco','2022-01-20');
insert into tb_datepart(id,name ,create_time) values(5,'Rose2','2022-01-21');
insert into tb_datepart(id,name ,create_time) values(6,'Coco2','2022-01-30');
insert into tb_datepart(id,name ,create_time) values(7,'Coco3','2022-01-31');
insert into tb_datepart(id,name ,create_time) values(8,'Coco4','2022-02-11');
insert into tb_datepart(id,name ,create_time) values(9,'Coco5','2022-02-21');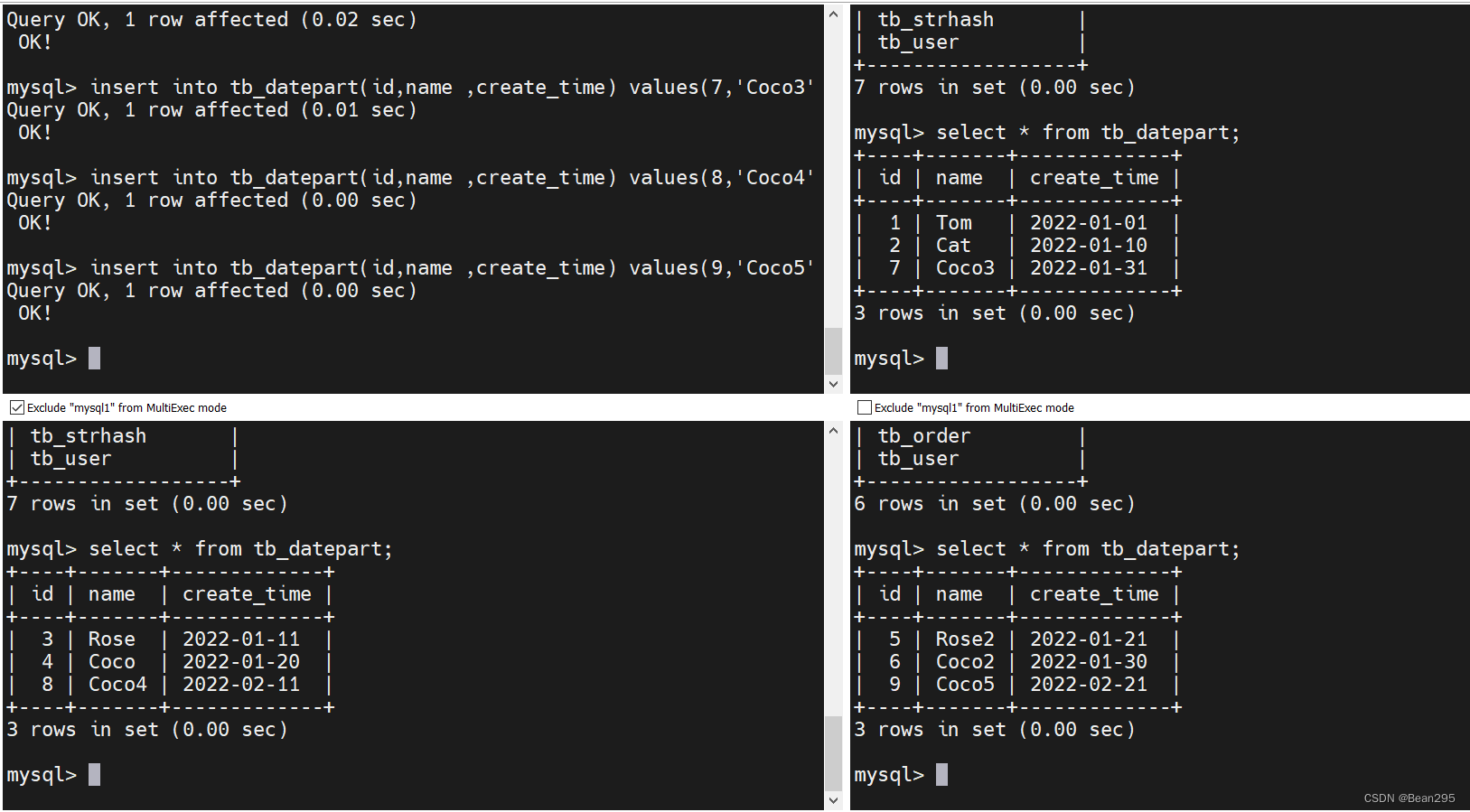
9、按自然月分片算法:
(1) 介绍:
按照月份来分片, 每个自然月为一个分片。


(2) 测试:
① 修改 rule.xml:
partbymonth 在默认规则集中已存在,修改 sBeginDate、sEndDate 即可。


② 修改 schema.xml:

③ 启动mycat,创建表结构,插入数据:

create table tb_monthpart(
id bigint not null comment 'ID' primary key,
name varchar(100) null comment '姓名',
create_time date null
);
insert into tb_monthpart(id,name ,create_time) values(1,'Tom','2022-01-01');
insert into tb_monthpart(id,name ,create_time) values(2,'Cat','2022-01-10');
insert into tb_monthpart(id,name ,create_time) values(3,'Rose','2022-01-31');
insert into tb_monthpart(id,name ,create_time) values(4,'Coco','2022-02-20');
insert into tb_monthpart(id,name ,create_time) values(5,'Rose2','2022-02-25');
insert into tb_monthpart(id,name ,create_time) values(6,'Coco2','2022-03-10');
insert into tb_monthpart(id,name ,create_time) values(7,'Coco3','2022-03-31');
insert into tb_monthpart(id,name ,create_time) values(8,'Coco4','2022-04-10');
insert into tb_monthpart(id,name ,create_time) values(9,'Coco5','2022-04-30');
四、MyCat 管理及监控
1、mycat 原理:
(1) 插入数据:
客户端输入insert语句时,mycat server首先会解析SQL语句,解析为insert操作 ;接着分析涉及的分片字段以及分片规则是什么 ;分片之后再根据路由分析将数据路由到对应的节点。
(2) 查询数据:
当客户端执行select查询操作时,mycat server解析不到分片字段,会将该命令路由给所有数据节点 ;数据节点将自己所存储的数据返回给mycat server ;mycat server再对数据进行合并处理,返回给客户端。

2、mycat 管理及监控工具:
(1) 介绍:
在MyCat的使用过程中,MyCat官方提供了一个管理监控平台MyCat-Web(MyCat-eye)。
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白。帮 Mycat 分担统计任务和配置管理任务。
Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节点。Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮件告警等模块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等。为优化 SQL 提供依据。
(2) 命令行管理:
① Mycat默认开通2个端口,可以在server.xml中进行修改:
8066 数据访问端口,即进行 DML 和 DDL 操作。
9066 数据库管理端口,即 mycat 服务管理控制功能,用于管理mycat的整个集群状态。
② 连接MyCat的管理控制台:
mysql -h 10.1.1.10 -P 9066 -uroot -p123456
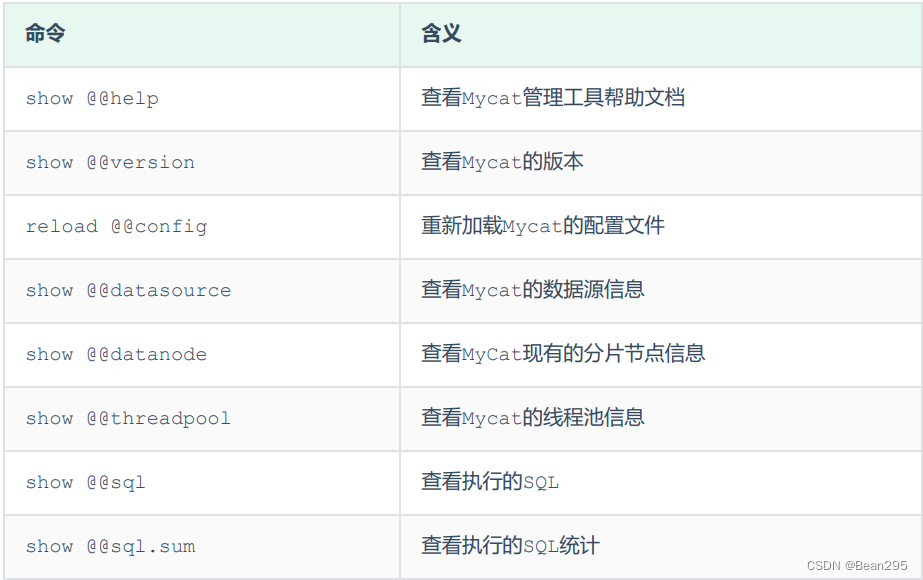
(3) web 界面管理:
① 安装 zookeeper:
Mycat-eye运行过程中需要依赖zookeeper,因此需要先安装zookeeper。
● 安装zookeeper:
tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local/
mv zookeeper-3.4.6/ zookeeper/
cd /usr/local/zookeeper
mkdir data #存放zookeeper数据的文件夹
● 修改zookeeper配置文件:
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改数据目录即可:

● 启动zookeeper:

② 安装Mycat-web:
tar -zxvf Mycat-web.tar.gz -C /usr/local/

● 关联mycat-web与zookeeper:
cd mycat-web/
vim WEB-INF/classes/mycat.properties
此处配置了zookeeper的地址为本机的2181端口,如果zookeeper与mycat不在同一台服务器,则要进行修改。

● 启动mycat-web:

③ 访问mycat-web:
http://mycat-webIP:8082/mycat