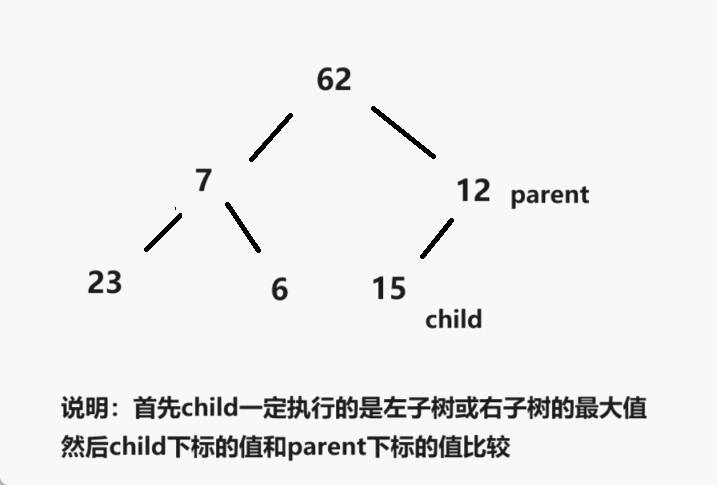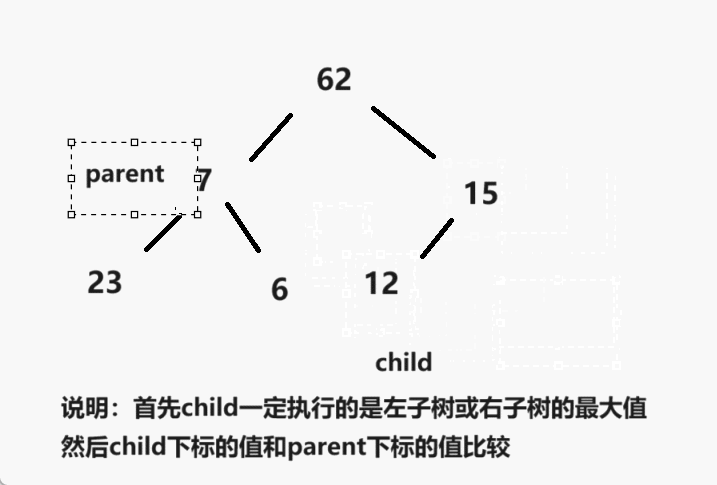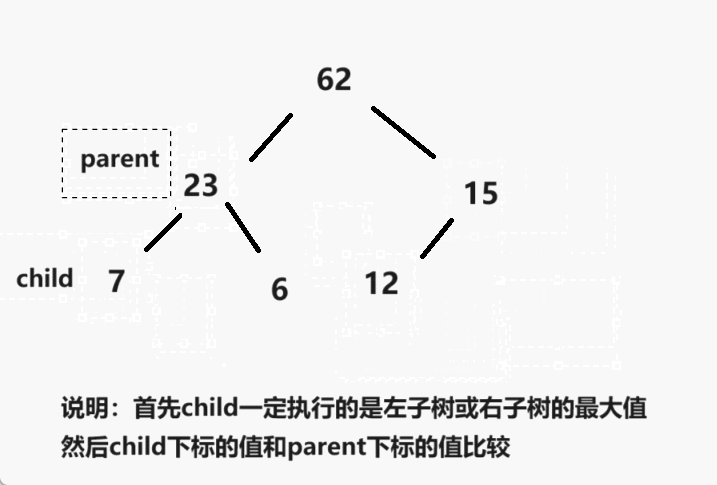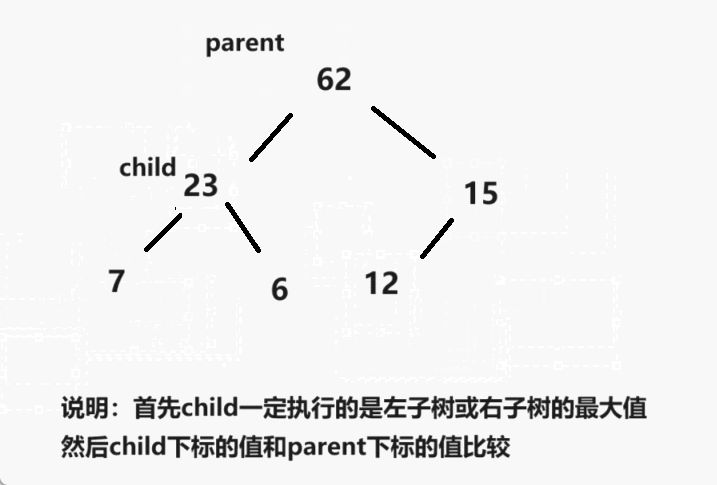
一、简介
| 算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 排序方式 | 稳定性 |
|---|---|---|---|---|---|---|
| 堆排序 | O( N N N log 2 N \log_{2}N log2N)) | O( N N N log 2 N \log_{2}N log2N)) | O( N N N log 2 N \log_{2}N log2N)) | O(1) | In-place | 不稳定 |
稳定:如果A原本在B前面,而A=B,排序之后A仍然在B的前面;
不稳定:如果A原本在B的前面,而A=B,排序之后A可能会出现在B的后面;
时间复杂度: 描述一个算法执行所耗费的时间;
空间复杂度:描述一个算法执行所需内存的大小;
n:数据规模;
k:“桶”的个数;
In-place:占用常数内存,不占用额外内存;
Out-place:占用额外内存。
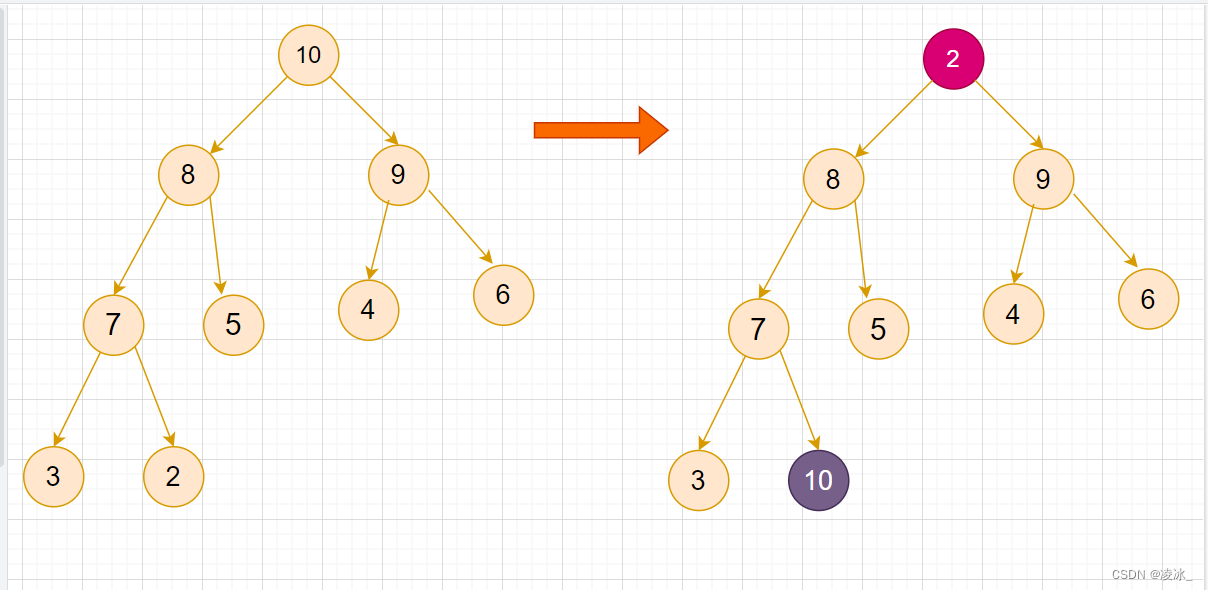
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
堆排序的平均时间复杂度为 Ο(nlogn)。

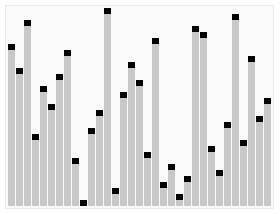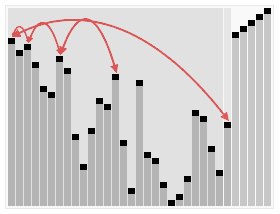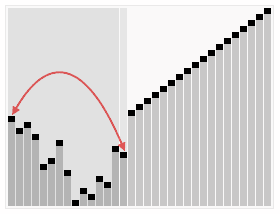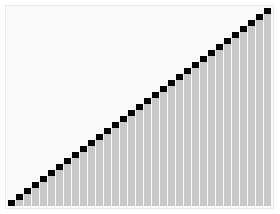
算法步驟:
- 1.创建一个堆 H[0……n-1];
- 2.把堆首(最大值)和堆尾互换;
- 3.把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
- 4.重复步骤2 ,直到堆的尺寸为 1。
二、代码实现
public class HeapSort {
public static void main(String[] args) {
int[] arr = {12, 11, 15, 50, 7, 65, 3, 99,0};
System.out.println("---排序前: " + Arrays.toString(arr));
heapSort(arr);
System.out.println("堆排序从小到大: " + Arrays.toString(arr));
heapSort2(arr);
System.out.println("堆排序从大到小: " + Arrays.toString(arr));
}
private static int heapLen;
public static void heapSort(int[] arr) {
heapLen = arr.length;
for (int i = heapLen - 1; i >= 0; i--) {
heapify(arr, i);
}
for (int i = heapLen - 1; i > 0; i--) {
swap(arr, 0, heapLen - 1);
heapLen--;
heapify(arr, 0);
}
}
private static void heapify(int[] arr, int idx) {
int left = idx * 2 + 1, right = idx * 2 + 2, largest = idx;
if (left < heapLen && arr[left] > arr[largest]) {
largest = left;
}
if (right < heapLen && arr[right] > arr[largest]) {
largest = right;
}
if (largest != idx) {
swap(arr, largest, idx);
heapify(arr, largest);
}
}
private static void swap(int[] arr, int idx1, int idx2) {
int tmp = arr[idx1];
arr[idx1] = arr[idx2];
arr[idx2] = tmp;
}
private static void heapSort2(int[] arr) {
heapLen = arr.length;
for (int i = heapLen - 1; i >= 0; i--) {
heapify2(arr, i);
}
for (int i = heapLen - 1; i > 0; i--) {
swap(arr, 0, heapLen - 1);
heapLen--;
heapify2(arr, 0);
}
}
private static void heapify2(int[] arr, int idx) {
int left = idx * 2 + 1, right = idx * 2 + 2, largest = idx;
if (left < heapLen && arr[left] < arr[largest]) {
largest = left;
}
if (right < heapLen && arr[right] < arr[largest]) {
largest = right;
}
if (largest != idx) {
swap(arr, largest, idx);
heapify2(arr, largest);
}
}
}

三、应用场景
稳定性:
堆排序是不稳定的算法,它不满足稳定算法的定义。它在交换数据的时候,是比较父结点和子节点之间的数据,所以,即便是存在两个数值相等的兄弟节点,它们的相对顺序在排序也可能发生变化。
应用场景:
堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况,适合超大数据量
大数据量的排序:堆排序适用于大数据量的排序,因为其时间复杂度为O(nlogn),效率较高。在处理大规模数据时,堆排序可以提供比较快速的排序结果。实时系统中的排序:由于堆排序的时间复杂度稳定且较低,适合在实时系统中进行排序操作。在需要快速排序的实时系统中,堆排序可以提供高效的排序解决方案。优先队列的实现:堆数据结构本身就是一种优先队列的实现方式,堆排序可以用于实现优先队列。在需要按照优先级对元素进行排序和访问的场景中,堆排序可以发挥作用。外部排序:堆排序也适用于外部排序,即对大规模数据进行排序时,数据无法全部加载到内存中,需要在磁盘上进行排序。堆排序可以在外部排序中提供高效的排序算法。
参考链接:
十大经典排序算法(Java实现)