这个是基于视频 https://www.bilibili.com/video/BV17t4218761,可以了解一下大模型里面的一些技术和最近的发展,基本都是2022你那以来的发展,比较新。然后本文需要一定的基础,比如知道啥是语言模型,知道深度学习以及怎么训练之类的。
如何炼成ChatGPT
先预训练一个生成语言模型,以自监督方式,也就是给定前面的单词预测下一个单词。得到模型A。
有监督微调,也就是给定问题和答案,对1中学习的预训练模型A进行微调。得到模型B。这叫做Fine-tuning,特点是涉及在模型头部引入新参数的情况(例如加一个分类器来做句子的情感分析,正向还是负面的情感),且都存在小样本场景过拟合的问题
2里面有一个问题,那就是需要标注数据,每一个问题,人类都要搞一个答案,所以有了强化学习的解决方案。具体来说,再训练一个模型C,这个模型学习如何给一个(问题,答案)打分,至于说给多少分,也是需要人类标注数据的,人类需要标注(问题,答案,打分),也就是说一个问题可能会有多个答案,好的不好的答案都有,但打分不同,这个模型C训练好了之后,就可以用来监督模型D了
在模型A的基础上,输入一个问题,模型A会输出一个答案,这个答案和问题一起交给模型C,我们可以得到一个得分,这个得分会反馈给模型A,从而模型A不断学习,想要提高得分,得到模型D。这个叫做强化学习,此时模型C叫做奖励模型。这种优化模型A的方式好像叫做instruction-tuning.
如何调教ChatGPT
- 小样本提示:给若干个问题,答案的示范,然后再问你的问题。
- 思维链chain of thought。先给一个示范:即给一个问题,自己给出答案,并且给出中间步骤是如何一步一步得到这个答案的,然后再问你想要问的问题。
- 分步骤思考,在问题后面加上一句:请你分步思考。
如何武装ChatGPT
1.检索增强生成:有些数据ChatGPT没有训练过,这个时候你问它它肯定不会,所以我们需要的就是给模型一个文档,然后让它根据文档来回答问题。
2.程序辅助语言模型:类似的,ChatGPT肯定也没有训练过一些比较冷门的数学计算,比如9283*31231.231,这个时候也要借助外部工具,不过不是文档了,而是计算器。这里不是你想的那样,调用一个在线计算器API,而是将计算的问题翻译成一段python代码,然后自己执行这段代码,得到计算结果。
3.推理行动结合:这个感觉就是思维链,甚至2其实也是思维链,只是这里的行动指的是访问外部API了,比如浏览器。推理就还是思维链,行动是根据推理的,然后行动之后有结果,这个结果又会进行推理,一直这样进行下去,直到模型认为回答完毕了(推理得到了)用户的问题。
其中3如下:

一些大模型的其他方向
这里来自于视频https://www.bilibili.com/video/BV1hM41157ZF。



prompt tuning
这部分是来自https://zhuanlan.zhihu.com/p/624178660,讲得很好。
至于论文的话不知道是不是这一篇:The Power of Scale for Parameter-Efficient Prompt Tuning(21年4月)。
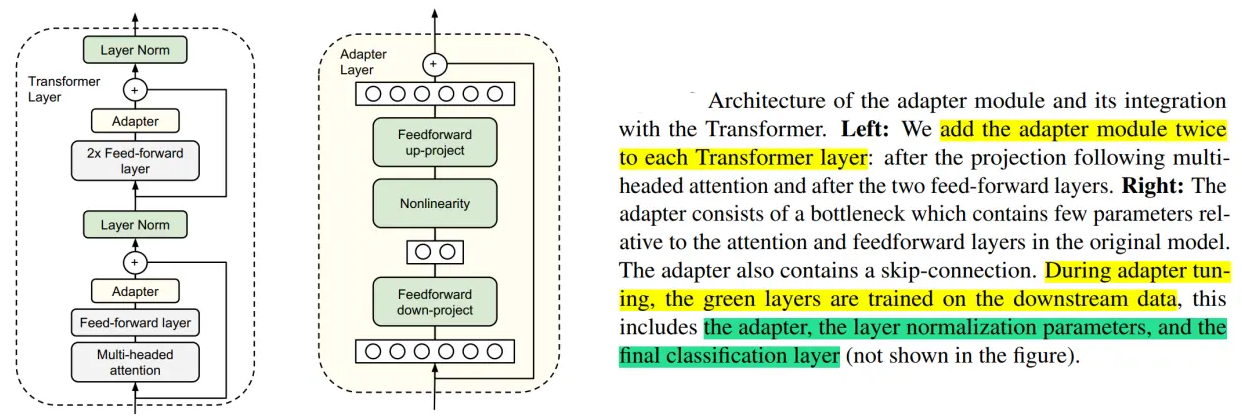
我们以二分类的情感分析作为例子,描述Prompt-tuning的工作原理。给定一个句子[CLS] I like the Disney films very much. [SEP] 传统的Fine-tuning方法是将其通过BERT的Transformer获得 [CLS]表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative),因此需要一定量的训练数据来训练。
而Prompt-Tuning则执行如下步骤:
构建模板(Template Construction):通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有[MASK]标记的模板。例如It was [MASK].,并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器(在huggingface中为BertForMaskedLM),即可直接得到[MASK]预测的各个token的概率分布;
标签词映射(Label Word Verbalizer):因为[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。
此时会有读者思考,不同的句子应该有不同的template和label word,没错,因为每个句子可能期望预测出来的label word都不同,因此如何最大化的寻找当前任务更加合适的template和label word是Prompt-tuning非常重要的挑战。 - 训练:根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题
Prompt tuning:提供示例实现few shot/zero shot, 或者给出前半句激发语音模型的补全能力(在没精调的模型上也有一定效果);
Instruction tuning: 通过给出明显的指令/指示, 让模型理解并做出正确的action。激发语言模型的理解能力(必须对模型精调,让模型知道这种指令模式)。
Instruction tuning
Google Research在2021年的论文《Finetuned Language Models Are Zero-Shot Learners》中提出了instruction-tuning。这个是21年9月。
Instruction的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
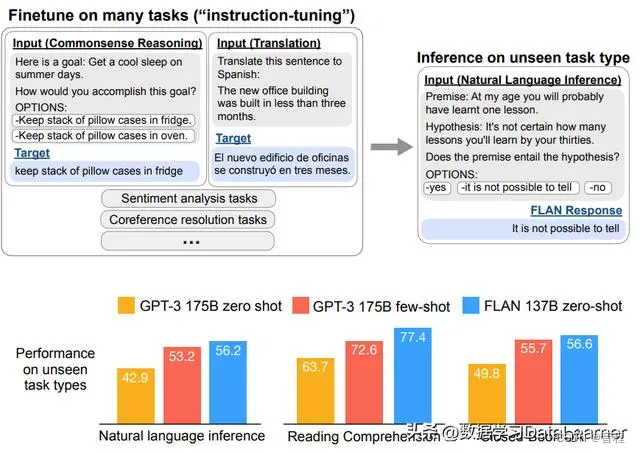
可以看到,必须精调,(input, target)有监督训练。啥是指令,我觉得就是那个问题。
所以和Instruction tuning和Prompt tuning的区别到底是什么?我没咋看出来。我的猜想是:Prompt tuning是给问题,然后mask答案,让模型回答Mask。这个在预训练模型的基础上可以直接运行,也可以再给一些(问题,答案)来进行训练微调。而Instruction tuning是。。。怎么感觉这么像。一个是21年4月提出的,一个是21年9月提出的,合理怀疑一下有没有可能只是同一个东西,不同名字,引用都是好几千。