本文详细介绍了机器学习中的微调技术,特别是在预训练模型上进行微调的方法和技术。文章首先解释了什么是微调,即在预训练模型的基础上,通过特定任务的数据进行有监督训练,以提高模型在该任务上的性能。随后,详细介绍了微调的一般步骤,包括预训练模型的选择、数据准备、构建任务特定的模型头、参数初始化、微调训练、调整超参数、评估和验证,以及可能的后续微调。
文中还详细探讨了参数高效微调(PEFT),一种在保持预训练模型的大部分参数不变的前提下,通过训练少量参数来适应下游任务的策略。介绍了几种主要的PEFT方法,包括适配器(Adapters)、稀疏微调、低秩近似和正则化技术等,以及如何通过这些技术减少计算和存储成本。
此外,文章还涉及了微调中的实际操作问题,如微调数据的构建、如何缓解模型遗忘通用能力的策略、常见的微调问题及其解决方案,包括如何处理大规模数据输入导致的OOM错误。
最后,探讨了非全量(优化)微调技术,即只更新模型的一部分参数来提高效率的策略。文中列举了多种微调技术,包括Prefix Tuning、Prompt Tuning、Adapter Tuning等,并提供了相关的代码示例和实际应用场景,旨在帮助读者更好地理解和实施这些高效的微调策略。
微调问题
一、微调基础问题
什么是微调
微调(Fine-tuning)是一种迁移学习的方法,用于在一个预训练模型的基础上,通过在特定任务的数据上进行有监督训练,来适应该任务的要求并提高模型性能。微调利用了预训练模型在大规模通用数据上学习到的语言知识和表示能力,将其迁移到特定任务上。
微调的一般步骤
预训练模型选择: 选择一个在大规模数据上进行预训练的模型作为基础模型。例如,可以选择一种预训练的语言模型,如BERT、GPT等。
数据准备: 准备用于微调的特定任务数据集。这些数据集应包含任务相关的样本和相应的标签或目标。确保数据集与任务的特定领域或问题相关。
构建任务特定的模型头: 根据任务的要求,构建一个特定的模型头(task-specific head)。模型头是添加到预训练模型之上的额外层或结构,用于根据任务要求进行输出预测或分类。例如,对于文本分类任务,可以添加一个全连接层和softmax激活函数。
参数初始化: 将预训练模型的参数作为初始参数加载到微调模型中。这些参数可以被视为模型已经学习到的通用语言表示。
微调训练: 使用特定任务的数据集对模型进行有监督训练。这包括将任务数据输入到模型中,计算损失函数,并通过反向传播和优化算法(如梯度下降)更新模型参数。在微调过程中,只有模型头的参数会被更新,而预训练模型的参数会保持不变。
调整超参数: 微调过程中,可以根据需要调整学习率、批量大小、训练迭代次数等超参数,以达到更好的性能。
评估和验证: 在微调完成后,使用验证集或测试集对微调模型进行评估,以评估其在特定任务上的性能。可以使用各种指标,如准确率、精确率、召回率等。
可选的后续微调: 根据实际情况,可以选择在特定任务的数据上进行进一步的微调迭代,以进一步提高模型性能。
微调的关键是在预训练模型的基础上进行训练,从而将模型的知识迁移到特定任务上。通过这种方式,可以在较少的数据和计算资源下,快速构建和训练高性能的模型。
参数高效微调(PEFT)
Parameter-Efficient Fine-Tuning(PEFT) 是一种微调策略,旨在仅训练少量参数使模型适应到下游任务。对大规模PLM(pre-trained language models )进行微调的成本往往高得令人望而却步。在这方面,PEFT方法只微调了少量(额外的)模型参数,从而大大降低了计算和存储成本。最近最先进的PEFT技术实现了与完全微调相当的性能。
PEFT通过冻结预训练模型的某些层,并仅微调特定于下游任务的最后几层来实现这种效率。这样,模型就可以适应新的任务,计算开销更少,标记的例子也更少。尽管PEFT是一个相对较新的概念,但自从引入迁移学习以来,更新最后一层模型已经在计算机视觉领域得到了实践。即使在NLP中,静态和非静态词嵌入的实验也很早就进行了。
参数高效微调旨在提高预训练模型(如BERT和RoBERTa)在各种下游任务上的性能,包括情感分析、命名实体识别和问答。它在数据和计算资源有限的低资源设置中实现了这一点。它只修改模型参数的一小部分,并且不容易过度拟合。
参数高效的微调在计算资源有限或涉及大型预训练模型的情况下特别有用。在这种情况下,PEFT可以在不牺牲性能的情况下提供一种更有效的方法来微调模型。然而,需要注意的是,PEFT有时可能会达到与完全微调不同的性能水平,特别是在预训练模型需要进行重大修改才能在新任务上表现良好的情况下。
微调和参数高效微调是机器学习中用于提高预训练模型在特定任务上的性能的两种方法。
微调就是把一个预先训练好的模型用新的数据在一个新的任务上进一步训练它。整个预训练模型通常在微调中进行训练,包括它的所有层和参数。这个过程在计算上非常昂贵且耗时,特别是对于大型模型。
另一方面,参数高效微调是一种专注于只训练预训练模型参数的子集的微调方法。这种方法包括为新任务识别最重要的参数,并且只在训练期间更新这些参数。这样,PEFT可以显著减少微调所需的计算量。
三、高效微调技术分类
可以粗略分为以下三大类:
1、增加额外参数(A)
(1)类适配器(Adapter-like)方法
(2)软提示(Soft prompts)方法
2、选取一部分参数更新(S)
3、引入重参数化(R)
参数高效微调技术方法
选择性层调整(Selective Layer Tuning):可以只微调层的一个子集,而不是微调模型的所有层。这减少了需要更新的参数数量。
适配器(Adapters):适配器层是插入预训练模型层之间的小型神经网络。在微调过程中,只训练这些适配器层,保持预先训练的参数冻结。通过这种方式,适配器学习将预先训练的模型提取的特征适应新任务。
稀疏微调(Sparse Fine-Tuning):传统的微调会略微调整所有参数,但稀疏微调只涉及更改模型参数的一个子集。这通常是基于一些标准来完成的,这些标准标识了与新任务最相关的参数。
低秩近似(Low-Rank Approximations):另一种策略是用一个参数较少但在任务中表现相似的模型来近似微调后的模型。
正则化技术(Regularization Techniques):可以将正则化项添加到损失函数中,以阻止参数发生较大变化,从而以更“参数高效”的方式有效地微调模型。
任务特定的头(Task-specific Heads):有时,在预先训练的模型架构中添加一个任务特定的层或“头”,只对这个头进行微调,从而减少需要学习的参数数量。
高效微调技术存在的一些问题
参数计算口径不一致:参数计算可以分为三类:可训练参数的数量、微调模型与原始模型相比改变的参数的数量、微调模型和原始模型之间差异的等级。例如,DiffPruning更新0.5%的参数,但是实际参与训练的参数量是200%。这为比较带来了困难。尽管可训练的参数量是最可靠的存储高效指标,但是也不完美。 Ladder-side Tuning使用一个单独的小网络,参数量高于LoRA或BitFit,但是因为反向传播不经过主网络,其消耗的内存反而更小。
缺乏模型大小的考虑:已有工作表明,大模型在微调中需要更新的参数量更小(无论是以百分比相对而论还是以绝对数量而论),因此(基)模型大小在比较不同PEFT方法时也要考虑到。
缺乏测量基准和评价标准:不同方法所使用的的模型/数据集组合都不一样,评价指标也不一样,难以得到有意义的结论。
代码实现可读性差:很多开源代码都是简单拷贝Transformer代码库,然后进行小修小补。这些拷贝也不使用git fork,难以找出改了哪里。即便是能找到,可复用性也比较差(通常指定某个Transformer版本,没有说明如何脱离已有代码库复用这些方法)。
实践规范
明确指出参数数量类型。
使用不同大小的模型进行评估。
和类似方法进行比较。
标准化PEFT测量基准。
重视代码清晰度,以最小化进行实现。
二、微调要考虑的问题和数据选取
微调时要考虑的因素
模型的大小
批次大小
输入序列的长度
计算平台和优化
微调(SFT) 后效果不好的原因
数据偏移
非典型标注
过拟合
缺乏多样性
SFT 指令微调数据 如何构建
原始数据->标注数据->划分数据->数据预处理->格式转化->模型微调->模型评估
领域:模型数据选取(Continue PreTrain )
领域相关数据->领域专家标注->伪标签->数据质量控制->数据预处理
领域:如何缓解模型遗忘通用能力
保留通用数据
增量学习
预训练和微调
强化学习
领域适应技术:使用领域适应技术,如领域自适应(Domain Adaptation)和领域对抗训练(Domain Adversarial Training),帮助模型在不同领域之间进行迁移学习,从而减少遗忘通用能力的问题。
数据重采样
常见问题问答
预训练和微调哪个阶段注入知识的
预训练和微调两个阶段都可以注入知识,但它们注入知识的方式和范围略有不同。
预训练:注入了通用的语言知识,并可以迁移到各种下游任务中
微调:注入的是与任务相关的知识和信息
想让模型学习某个领域或行业的知识,是应该预训练还是应该微调
微调:微调过程可以使模型更好地理解和处理与特定领域相关的文本数据,从而提高模型在该领域任务上的性能。
多轮对话任务如何微调模型
数据准备->构建输入输出格式->模型选择->模型微调(初始化-损失函数-反向传播和参数更新-重复)-超参数调优-评估和测试
注意:除了常规的微调方法,还可以采用一些特定的技巧,如引入对话历史的注意力机制、使用特定的对话策略进行训练等,
微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
数据分布差异
参数更新冲突
解决:
经验回放
弹性权重共享
增量学习
多任务学习
预训练和SFT的区别
预训练的目标是通过无监督学习从大规模的文本语料库中学习语言模型的表示能力和语言知识。
有监督微调的目标是在特定的任务上进行训练,例如文本分类、命名实体识别等。在有监督微调中,模型会利用预训练阶段学到的语言表示和知识,通过有监督的方式调整模型参数,以适应特定任务的要求。
预训练:无标签文本数据进行训练
微调:有监督的方式进行训练
数据输入格式要求
输入数据应以文本形式提供,每个样本对应一行。
对于分类任务,每个样本应包含文本和标签,可以使用制表符或逗号将文本和标签分隔开。
对于生成任务,每个样本只需包含文本即可。
对于序列标注任务,每个样本应包含文本和对应的标签序列,可以使用制表符或逗号将文本和标签序列分隔开。
数据集应以常见的文件格式(如文本文件、CSV文件、JSON文件等)保存,并确保数据的格式与模型输入的要求一致。
样本量规模增大,训练出现OOM错
减少批量大小
分布式训练
内存优化技术
混合精度训练(Mixed Precision Training) 可以减少模型参数的内存占用;
使用梯度累积(Gradient Accumulation) 可以减少每个训练步骤中的内存需求。
减少模型规模
增加硬件资源
数据处理和加载优化
三、非全量(优化)微调技术
背景:全量微调占用了非常大的空间。
四大类大模型微调技术:
增加额外参数:Prefix tuning, prompt tuning
指定更新一部分参数:BitFit
重参数化微调:LoRA,AdaptLoRA,QLoRA
混合高效微调:UniPELT
Prompt微调
Prefix Tuning
Prefix Tuning提出固定预训练LM,为LM添加可训练,任务特定的前缀,
在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。
Prompt Tuning
通过反向传播更新参数来学习prompts,而不是人工设计prompts;同时冻结模型原始权重,只训练prompts参数。
P-Tuning
背景:大模型的Prompt构造方式严重影响下游任务的效果。
方法:设计了一种连续可微的virtual token(同Prefix-Tuning类似)。将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
注意:但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。
P-Tuning v2
背景:P-Tuning和Prompt Tuning缺乏模型参数规模和任务通用性
方法:该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层
注意:移除重参数化的编码器;针对不同任务采用不同的提示长度;引入多任务学习;回归传统的分类标签范式,而不是映射器。
– P-Tuning v2是一种在不同规模和任务中都可与微调相媲美的提示方法。
BitFit
是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。
Adapter-tuning微调方案
背景:训练下游任务时进行全量微调变得昂贵且耗时
Adapter Tuning
Adapter 的出现缓解了上述问题 Adapter 在预训练模型每层中插入用于下游任务的参数(针对每个下游任务,仅增加3.6%的参数),在微调时将模型主体冻结,仅训练特定于任务的参数,从而减少了训练时的算力开销。
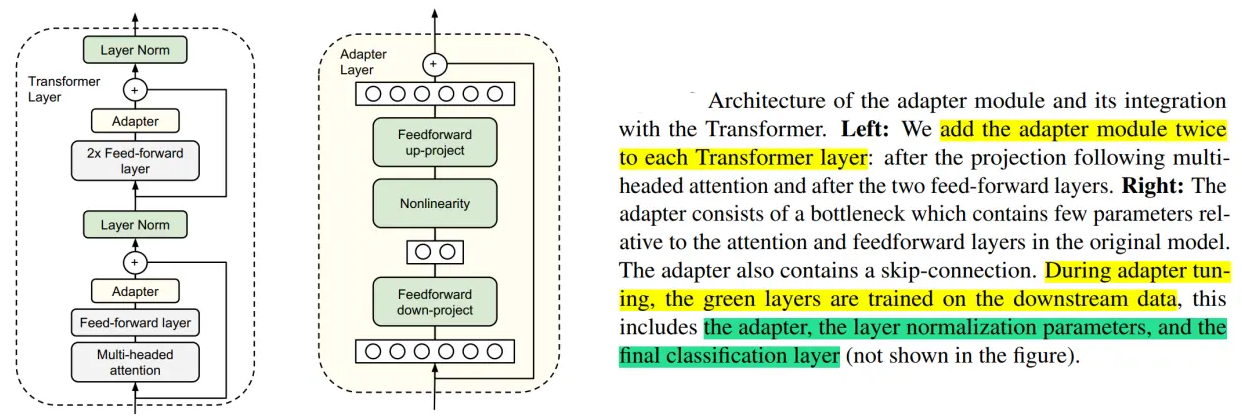
每个 Adapter 模块主要由两个前馈(Feedforward)子层组成,第一个前馈子层(down-project)将Transformer块的输出作为输入,将原始输入维度d(高维特征)投影到m(低维特征),通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d。然后,中间通过一个非线形层。在输出阶段,通过第二个前馈子层(up-project)还原输入维度,将m(低维特征)重新映射回d(原来的高维特征),作为Adapter模块的输出。同时,通过一个skip connection来将Adapter的输入重新加到最终的输出中去,这样可以保证,即便 Adapter 一开始的参数初始化接近0,Adapter也由于skip connection的设置而接近于一个恒等映射,从而确保训练的有效性。
AdapterFusion
如果想要把来自多个任务的知识结合起来,是否可以考虑把多个任务的Adapter的参数结合起来
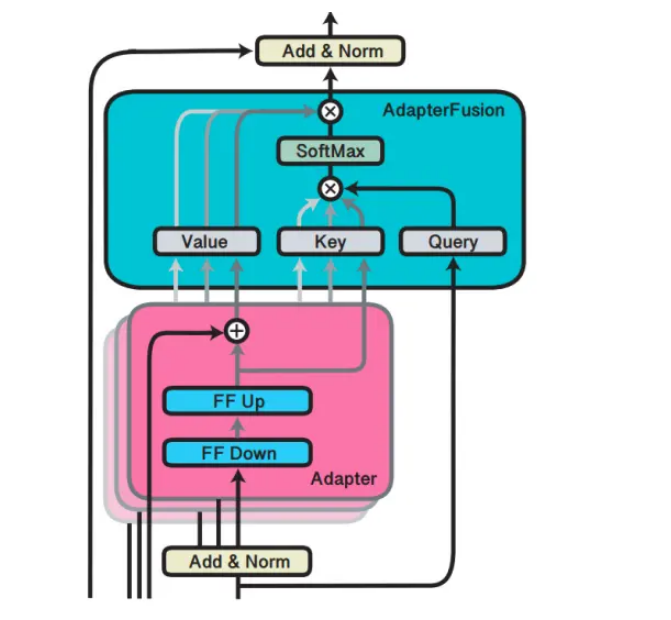
Adapter Fusion(论文:AdapterFusion:Non-Destructive Task Composition for Transfer Learning),一种融合多任务信息的Adapter的变体,在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。
知识提取阶段:在不同任务下引入各自的Adapter模块,用于学习特定任务的信息。
知识组合阶段:将预训练模型参数与特定于任务的Adapter参数固定,引入新参数(AdapterFusion)来学习组合多个Adapter中的知识,以提高模型在目标任务中的表现。
对于第一阶段,有两种训练方式,分别如下:
Single-Task Adapters(ST-A):对于N个任务,模型都分别独立进行优化,各个任务之间互不干扰,互不影响。
Multi-Task Adapters(MT-A):N个任务通过多任务学习的方式,进行联合优化。
AdapterDrop
背景:作者通过对Adapter的计算效率进行分析,发现与全量微调相比,Adapter在训练时快60%,但是在推理时慢4%-6%。
AdapterDrop(论文:AdapterDrop: On the Efficiency of Adapters in Transformers),在不影响任务性能的情况下,对Adapter动态高效的移除,尽可能的减少模型的参数量,提高模型在反向传播(训练)和正向传播(推理)时的效率。
AdapterDrop 通过从较低的 Transformer 层删除可变数量的Adaper来提升推理速度。
LoRA微调
核心公式:
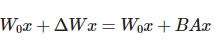
LoRA
方法通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
将BA加到W上可以消除推理延迟。
可以通过可插拔的形式切换到不同的任务。
设计的比较好,简单且效果好。
AdaLoRA
对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵
将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
QLoRA
使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
特点:
使用 QLoRA 微调模型,可以显著降低对于显存的要求。同时,模型训练的速度会慢于LoRA。
统一的框架
MAM Adapter
近年来提出了多种参数高效的迁移学习方法,这些方法仅微调少量(额外)参数即可获得强大的性能。虽然有效,但人们对为什么有效的关键要素以及各种高效微调方法之间的联系知之甚少。
一个在它们之间建立联系的统一框架。具体来说,将它们重新构建为对预训练模型中特定隐藏状态的修改,并定义一组设计维度,不同的方法沿着这些维度变化。
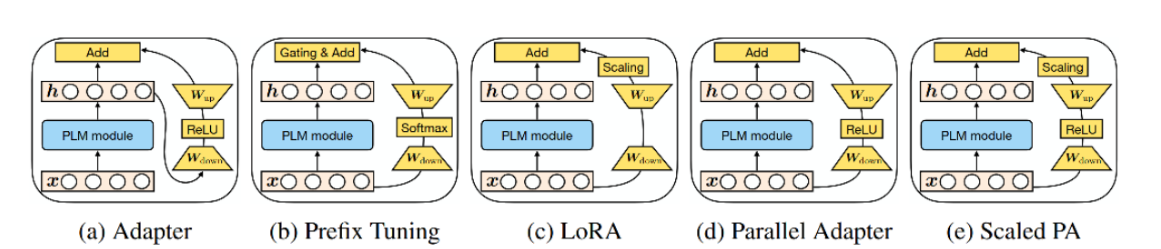
作者分解了当下最先进的参数高效迁移学习方法(Adapter、Prefix Tuning和LoRA)的设计,并提出了一种新方法MAM Adapter,一个在它们之间建立联系的统一框架。具体来说,将它们重新构建为对预训练模型中特定隐藏状态的修改,并定义一组设计维度,不同的方法沿着这些维度变化。
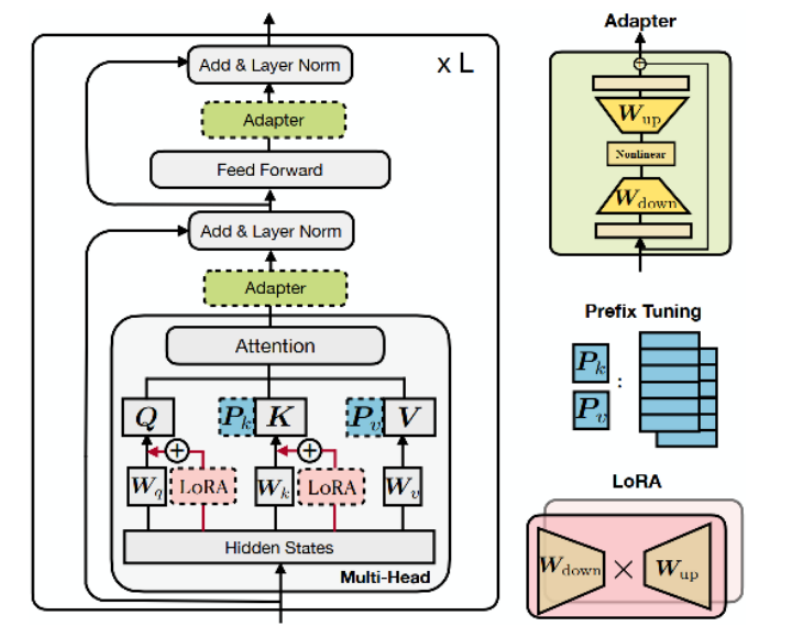
UniPELT
UniPELT方法,将不同的PELT方法作为子模块,并通过门控机制学习激活最适合当前数据或任务的方法。
UniPELT 仅用 100 个示例就在低数据场景中展示了相对于单个 LoRA、Adapter 和 Prefix Tuning 方法的显著改进。在更高数据的场景中,UniPELT 的性能与这些方法相当或更好。
四、总结
共有四类微调方法
增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体。
选取一部分参数更新,如:BitFit。
引入重参数化,如:LoRA、AdaLoRA、QLoRA。
混合高效微调,如:MAM Adapter、UniPELT。
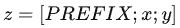






















![[leetcode]maximum-width-of-binary-tree](https://img-blog.csdnimg.cn/img_convert/10b145aa8aa6b5e15ee483c07f70370f.jpeg)