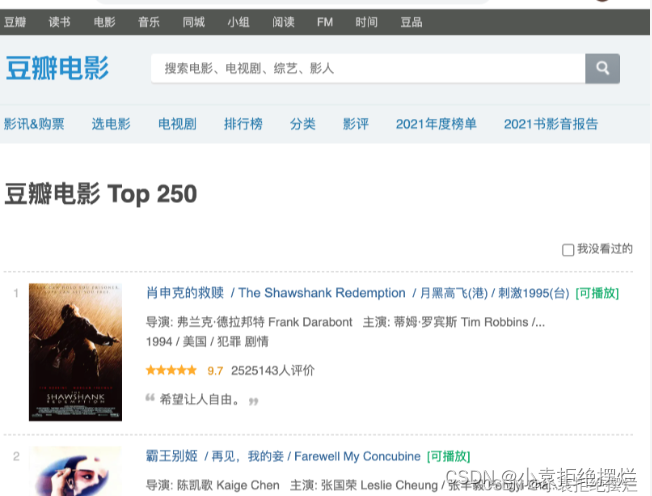
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name=scrapy.Field()
spider_title.py
import scrapy
from sy.items import SyItem
class SpiderTitleSpider(scrapy.Spider):
name = "spider_title"
allowed_domains = ["www.zongheng.com"]
start_urls = ["https://read.zongheng.com/chapter/1215341/68208370.html"]
def parse(self, response):
item = SyItem()
titles = [each.extract() for each in response.xpath('//*[@id="Jcontent"]/div/div[4]/p/text()')]
print(titles)
item['name']=titles
print(type(titles))
f=open('aa.txt','w')
for asd in titles:
f.write(asd+'\n')
return item