书生·浦语大模型实战营Day05LMDeploy 服务
LMDeploy服务(serve)
在第二章和第三章,我们都是在本地直接推理大模型,这种方式成为本地部署。在生产环境下,我们有时会将大模型封装为API接口服务,供客户端访问。

从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
- Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
启动API服务器
通过以下命令启动API服务器,推理internlm2-chat-1_8b模型:
lmdeploy serve api_server \
/root/internlm2-chat-1_8b \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)。
通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。
可以通过运行一下指令,查看更多参数及使用方法:
lmdeploy serve api_server -h
你也可以直接打开http://{host}:23333查看接口的具体使用说明,如下图所示。
注意,这一步由于Server在远程服务器上,所以本地需要做一下ssh转发才能直接访问。在你本地打开一个cmd窗口,输入命令如下:
# ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 你的ssh端口号
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 44350


- 作业:以API Server方式启动 lmdeploy,开启 W4A16量化,调整KV Cache的占用比例为0.4,分别使用命令行客户端与Gradio网页客户端与模型对话。
lmdeploy serve api_server \
/root/internlm2-chat-1_8b-4bit \
--model-format awq \
--cache-max-entry-count 0.4 \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1


命令行客户端连接API服务器

在前面,我们在终端里新开了一个API服务器。
本节中,我们要新建一个命令行客户端去连接API服务器。首先通过VS Code新建一个终端:
激活conda环境。
conda activate lmdeploy
运行命令行客户端:
lmdeploy serve api_client http://localhost:23333
运行后,可以通过命令行窗口直接与模型对话:

网页客户端连接API服务器

关闭刚刚的VSCode终端,但服务器端的终端不要关闭。
新建一个VSCode终端,激活conda环境。
conda activate lmdeploy
使用Gradio作为前端,启动网页客户端。
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
运行命令后,网页客户端启动。在电脑本地新建一个cmd终端,新开一个转发端口:
# ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p <你的ssh端口号>
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 44350
打开浏览器,访问地址http://127.0.0.1:6006



Python代码集成
在开发项目时,有时我们需要将大模型推理集成到Python代码里面。
Python代码集成运行1.8B模型
首先激活conda环境。
conda activate lmdeploy
新建Python源代码文件pipeline.py。
touch /root/pipeline.py
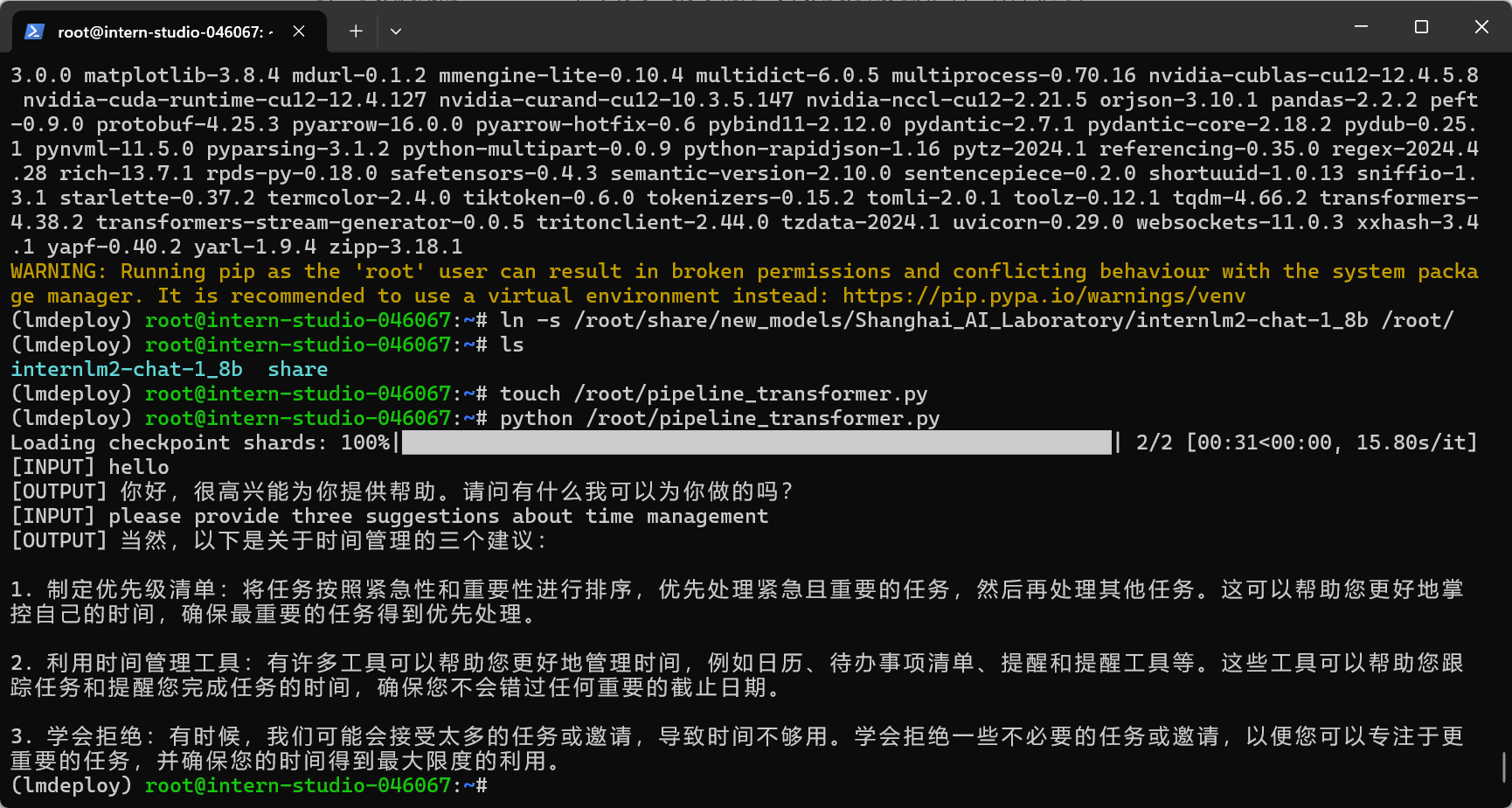
打开pipeline.py,填入以下内容。
from lmdeploy import pipeline
pipe = pipeline('/root/internlm2-chat-1_8b')
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
代码解读:\
- 第1行,引入lmdeploy的pipeline模块 \
- 第3行,从目录“./internlm2-chat-1_8b”加载HF模型 \
- 第4行,运行pipeline,这里采用了批处理的方式,用一个列表包含两个输入,lmdeploy同时推理两个输入,产生两个输出结果,结果返回给response \
- 第5行,输出response
保存后运行代码文件:
python /root/pipeline.py
- 作业:使用W4A16量化,调整KV Cache的占用比例为0.4,使用Python代码集成的方式运行internlm2-chat-1.8b模型。

向TurboMind后端传递参数
在第3章,我们通过向lmdeploy传递附加参数,实现模型的量化推理,及设置KV Cache最大占用比例。在Python代码中,可以通过创建TurbomindEngineConfig,向lmdeploy传递参数。
以设置KV Cache占用比例为例,新建python文件pipeline_kv.py。
touch /root/pipeline_kv.py
打开pipeline_kv.py,填入如下内容:
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)
pipe = pipeline('/root/internlm2-chat-1_8b',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
保存后运行python代码:
python /root/pipeline_kv.py
得到输出结果:


![[<span style='color:red;'>书生</span>·<span style='color:red;'>浦</span><span style='color:red;'>语</span><span style='color:red;'>大</span><span style='color:red;'>模型</span><span style='color:red;'>实战</span><span style='color:red;'>营</span>]——<span style='color:red;'>LMDeploy</span> 量化部署 LLM <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/8d577c3ced1b42588c295eb8f7ad0e7f.png)