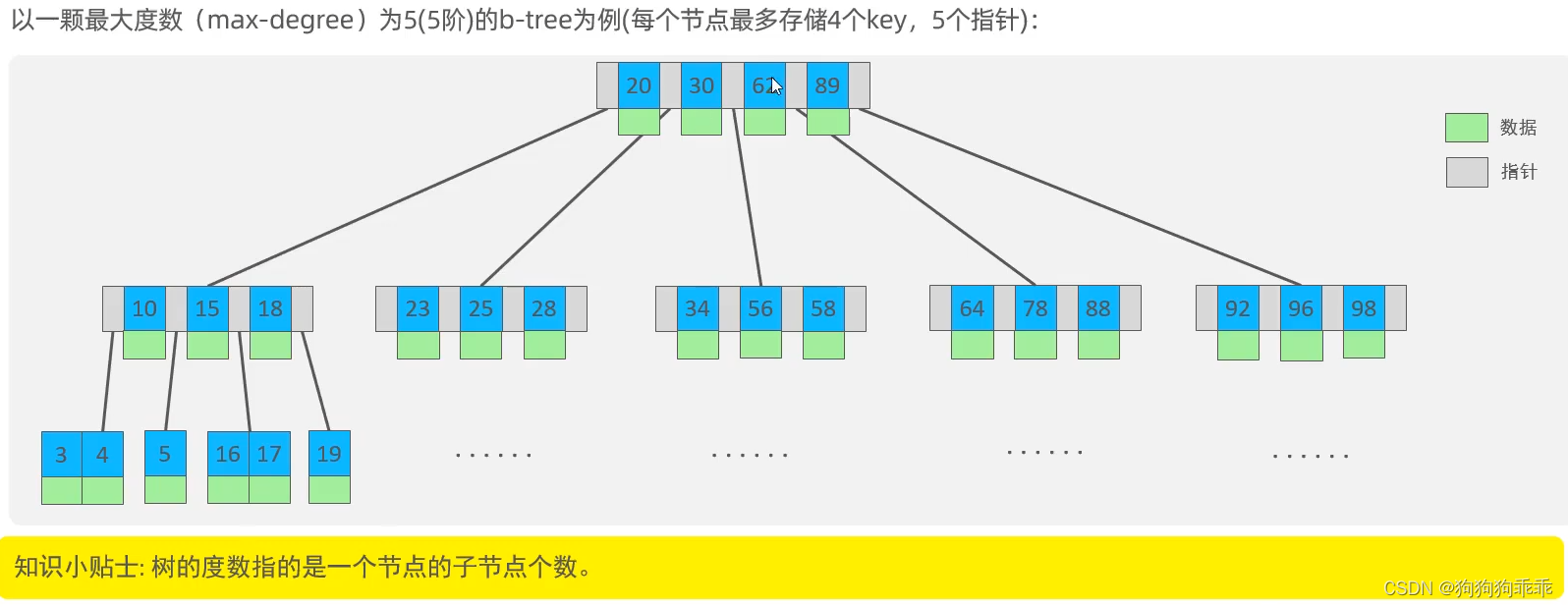
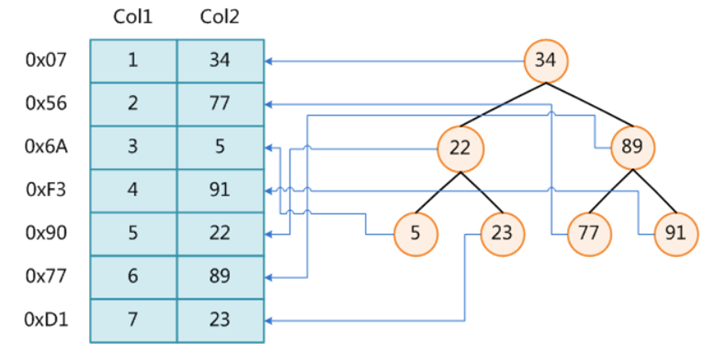
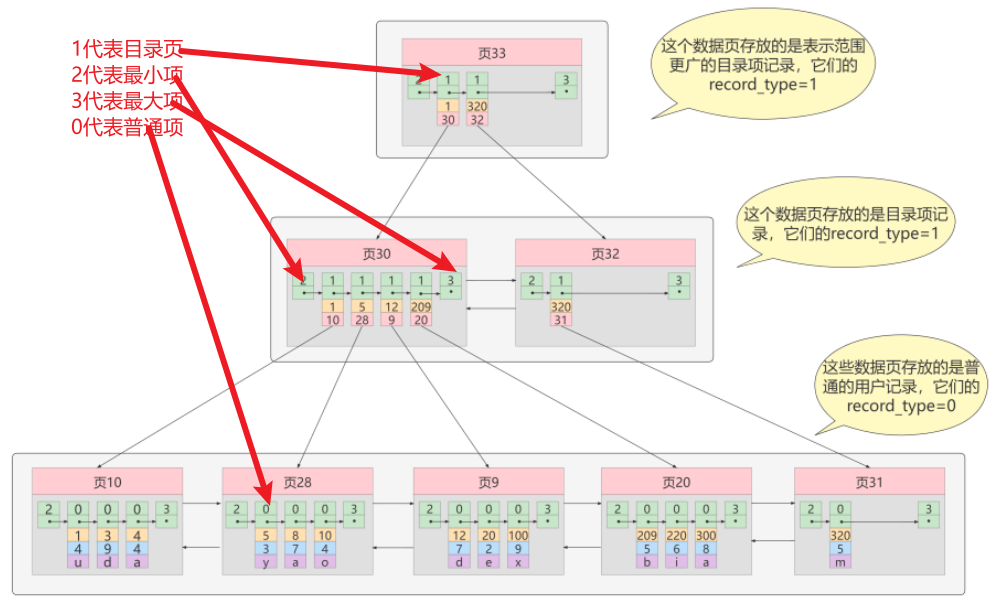
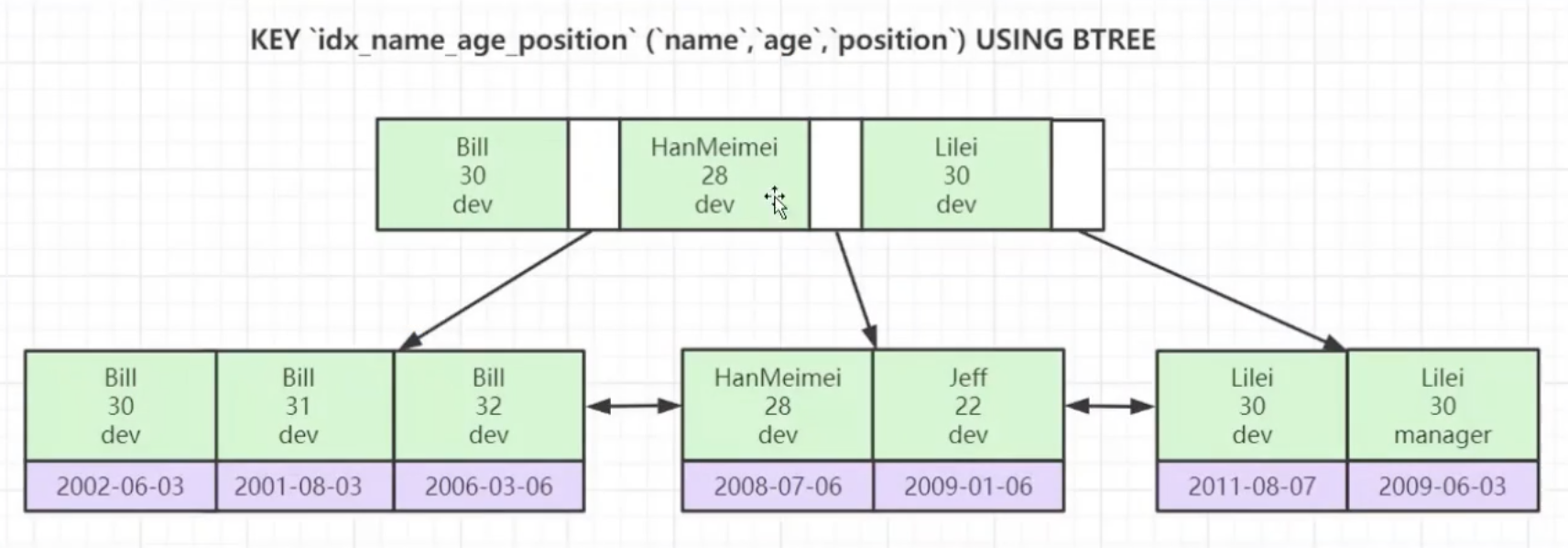
MySQL有哪些索引类型?
MySQL支持B+树索引、哈希索引、全文索引三种索引类型。
我比较常用的是B+树索引,因为它是InnoDB引擎默认使用的索引类型,支持排序、分组、范围查询、模糊查询等功能。
InnoDB引擎的所以数据结构是什么?
InnoDB存储引擎支持两种索引数据结构,B+树索引和FULLTEXT索引。
MySQL为什么使用B+树?
- B+树是多叉树,平衡二叉树、红黑树是二叉树,在同等数据量下,平衡二叉树、红黑树高度更高,磁盘IO次数更多,性能更差,而且它们会频繁执行再平衡过程,来保证树形结构平衡。
- 跳表和B+树相比,跳表在极端情况下会退化为链表,平衡性差,而数据库查询需要一个可预期的查询时间,并且跳表需要更多内存。
- B树和B+树相比,B树的数据存储在全部节点中,对查询范围不友好。非叶子结点存储了数据,导致内存中难以放下全部非叶子结点。如果内存放不下非叶子节点,那么就意味着查询非叶子结点的时候都需要磁盘IO。
- B+树与哈希表相比。哈希表索引不支持范围查询和排序操作,不支持联合索引最左匹配原则,如果重复键值比较多,还容易造成哈希碰撞导致效率进一步降低。
聚类索引和非聚类索引有什么区别?
聚类索引和非聚类索引最主要的区别是B+树叶子结点存放的内容不同。
存放的内容不同:
- 聚簇索引的B+树叶子结点存放的是主键值+完整的记录
- 非聚类索引的B+树叶子结点存放的是索引值+主键值
如果查询语句的查询条件用了二级索引,但是查询的数据不是主键值,也不是二级索引值,这时在二级索引找到主键后,就需要回表才能查到数据,需要扫描两次B+树。如果查询的数据是主键值时,因为只在二级索引就能查询到,这时就会用到覆盖索引,不需要回表,只需要扫描一次B+树。
insert 操作对 B+ 树结构的改变是怎么样的?
B+ 树的数据都是有序的,所以
- 如果我们使用主键是顺序递增,那么每次插入的新数据就会顺序插入到叶子结点最右边的节点里,如果该页面满了,就会自动开辟一个新页面,将数据插入到新页面。因此每次插入一条新纪录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
- 如果我们使用主键不是顺序递增,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这时候为了保证B+树的有序性,要移动其他数据来满足新数据的插入。如果该页面满了,就发生页分裂,这时候要从一个页面复制数据到另一个页面,目的时保证后一个数据页中的所有行主键值比前一个数据页中主键值大,也分裂可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
所以,在设计主键的时候,最好采用自增的方式,或者顺序递增主键值。
假如一张表有两千万的数据,B+树的高度是多少?怎么算的?
假设
非叶子节点内指向其他页的数量为 x
叶子节点内能容纳的数据行数为 y
B+ 树的层数为 z
表总数会等于 x 的 z-1 次方与 y 的乘积
具体要看数据库表的字段多不多,以及字段类型,假设一行记录是1KB大小,那么2000万的数据表,B+树大概是三层高度。
MySQL数据页的大小是16KB,去掉一些头信息,大概有15KB是可以存储数据。
在索引页中主要记录的是主键与页号,假设是主键id类型是bigint,那就是8字节,页号固定为4字节,那么索引页中一条数据也就是12byte,那么一个索引页可以存储 15 * 1024 / 12 ≈ 1280 个页号。
叶子节点中存放的是真正的行数据,这个影响的因素就会多很多,比如字段的类型,字段的数量。每行数据占用空间越大,页中所放的行数量就会越少假设一条行数据1KB来算,那么一页就能存下15条。
根据公式 Total = x(z-1) * y,已知 x = 1280, y = 15, 假设 B+ 树是三层,那就是z = 3, Total = (1280 ^2) * 15 = 24576000 (约 2.45kw)