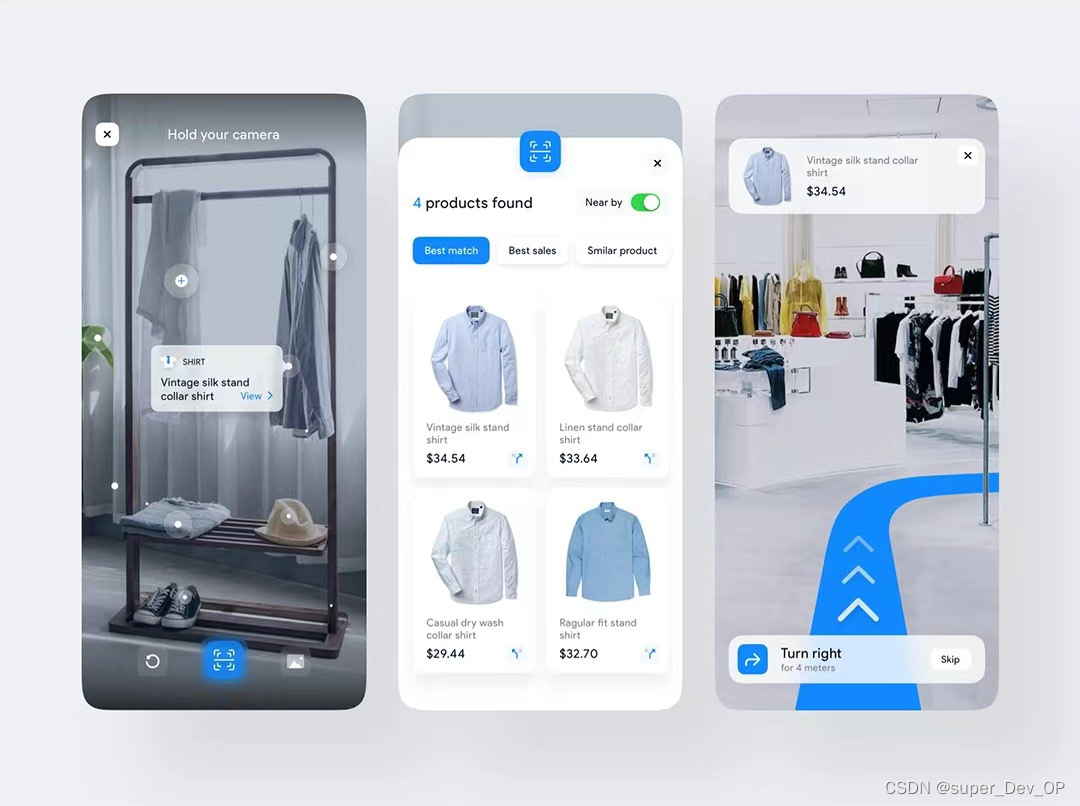
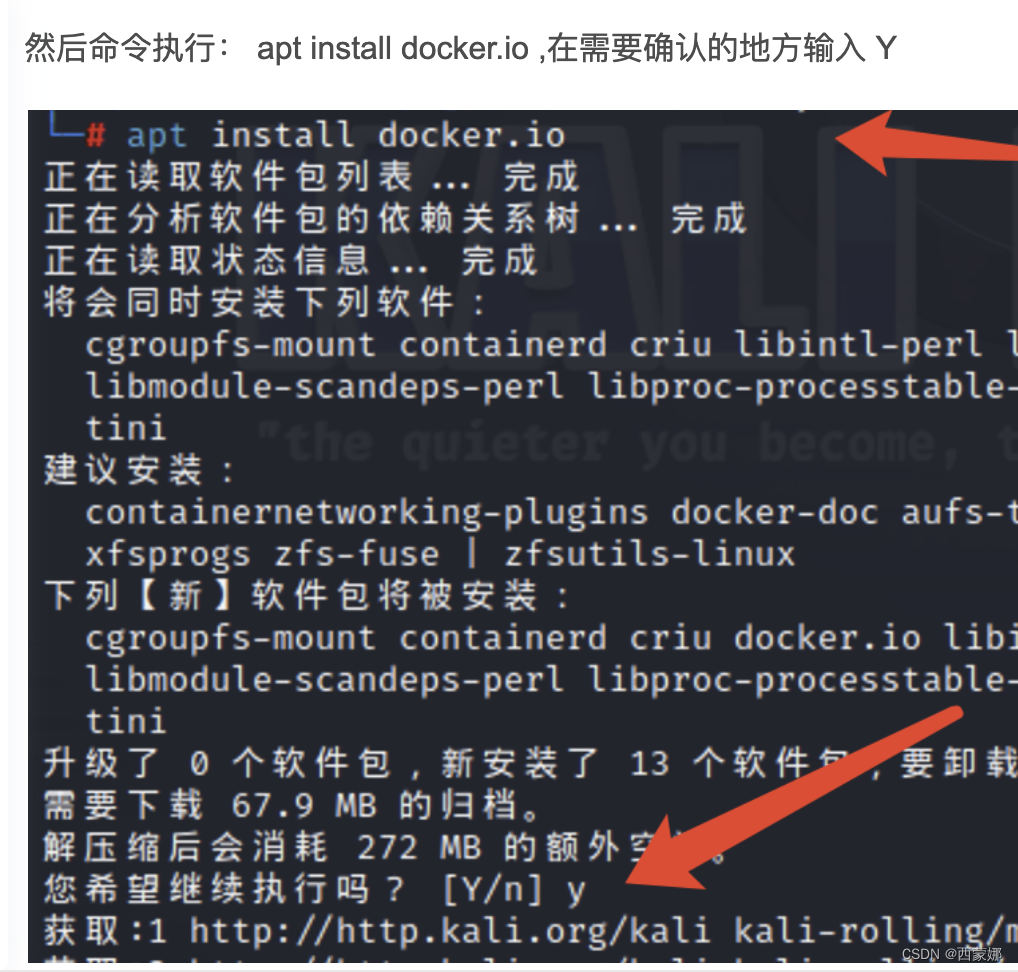
个人主页:丷从心·
系列专栏:编译原理

2.1|高级程序语言的词构成特性
预定义词
- 关键词
- 算术运算词
- 比较运算词
- 逻辑运算词
- 标点符号词
自定义词
变量
常量
数值类常量
- 整数
- 实数
字符类常量
- 字符常量
- 字符串常量
长度优先原则
- 当词法分析中遇到“
<=”时,基于长度优先原则,词法分析的结果是“<=”这一个词
2.2|词法的描述
C语言的词法
变量的正则表达式
letter -> ['A'~'Z'] ∪ ['a'~'z']
digit -> ['0'~'9']
id -> (letter ∪ '_') · (letter ∪ digit ∪ '_')*
数值常量的正则表达式
digits -> digit+
optionalFraction -> '.' · digits
optionalExponent -> 'E' · ('+' ∪ '-')? · digits
numberConst -> integerConst · optionalFraction? · optionalExponent?
预定义词的正则表达式
reservedLexeme -> 'i' · 'n' · 't' ∪ '+' ∪ '<' · '=' ∪ '&' · '&' ∪ ';'
字符类常量的正则表达式
stringConst -> '‘' · (character - '’') · '’' ∪ '“' · (character - '”')* · '”'
注释的正则表达式
singleRowNote -> '/' · '/' · (character - cr - lf)* · cr · lf
multiRowNoteContent1 -> (character - '*')* · ('*')+
multiRowNoteContent2 -> (character - '*' - '/') · (character - '*')* · ('*')+
multiRowNoteContent -> multiRowNoteContent1 · multiRowNoteContent2*
multiRowNote -> '/' · '*' · multiRowNoteContent · '/'
note -> singleRowNote ∪ multiRowNote
- 对于多行注释,将开头标志
/*以后的内容分为两部分,一部分是以*结尾的字符串(取名为multiRowNoteContent),一部分是字符/ multiRowNoteContent中肯定不含*/子串,对multiRowNoteContent从左到右扫描,当发现*字符后面不再为*字符时,就进行一次切分,经此切分后,给其中第一个子字符串取名为multiRowNoteContent1,其他的子字符串取名为multiRowNoteContent2
空格的正则表达式
blankSpace -> (空格字符)+
回车换行的正则表达式
crlf -> (cr · lf)+
C语言的词法
lexeme -> reservedLexeme ∪ id ∪ numberConst ∪ stringConst ∪ note ∪ blankSpace ∪ crlf
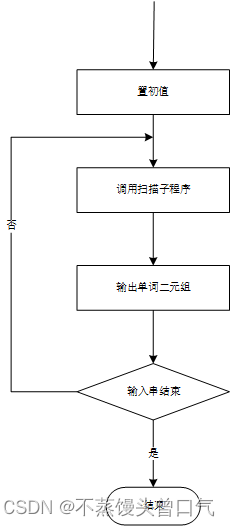
词法分析的实现框架
- 词法分析器要对输入字符序列从头到尾逐一扫描,将其切分成一个词序列
- 会用到两个指针:起始指针
pStart和当前指针pCurrent,初始时,指针pStart和pCurrent都指向输入字符序列的第一个字符 - 如果当前串是正则表达式所指集合中的元素,就对
pCurrent指针后移一步,接着继续进行判断,直至当前串不为正则表达式所指集合中的元素,这时就解析出一个词 - 将解析出的词输出,然后解析下一个词,把
pCurrent的值赋给pStart,这个过程不断进行下去,直至pStart和pCurrent都指向输入字符序列末尾的结束字符
正则表达式的含义
- 正则表达式相当于面向对象中的类,它所指集合中的元素相当于类的实例对象
2.3|基于状态转换图的词法分析
基于状态转换图的匹配判断算法
bool match(char inputString[], int inputSize) {
int currentState = 0;
int currentIndex = 0;
wihle(currentIndex < inputSize) {
currentState = getNextStateInGraph(currentState, inputString[currentIndex]);
if(currentState == -1)
return false;
else
currentIndex++;
}
if(getStateTypeInGraph(currentState) == MATCH)
return true;
else
return false;
}
C语言词法正则表达式lexeme的状态转换图
基于状态转换图的词法分析算法
Lexeme* getNextLexeme() {
int currentState = 0;
startIndex = currentIndex;
while(currentIndex < inputSize) {
int nextState = getNextStateInGraph(currentState, input[currentIndex]);
if(nextState == -1) {
if(getTypeInGraph(currentState) == MATCH) {
category = getCategoryInGraph(currentState);
if(category == ID | INTEGER_CONST | FLOAT_CONST | SCIENTIFIC_CONST | CHAR_CONST | STRING_CONST | NUMERIC_OPERATOR | LOGIC_OPERATOR | COMPARE_OPERATOR | OTHER_RESERVED)
return new Lexeme(startIndex, currentIndex - 1, category);
else {
startIndex = currentIndex;
currentState = 0;
}
}
else {
raise exception('源代码有词法错误');
}
}
else {
currentState = nextState;
currentIndex++;
}
}
}