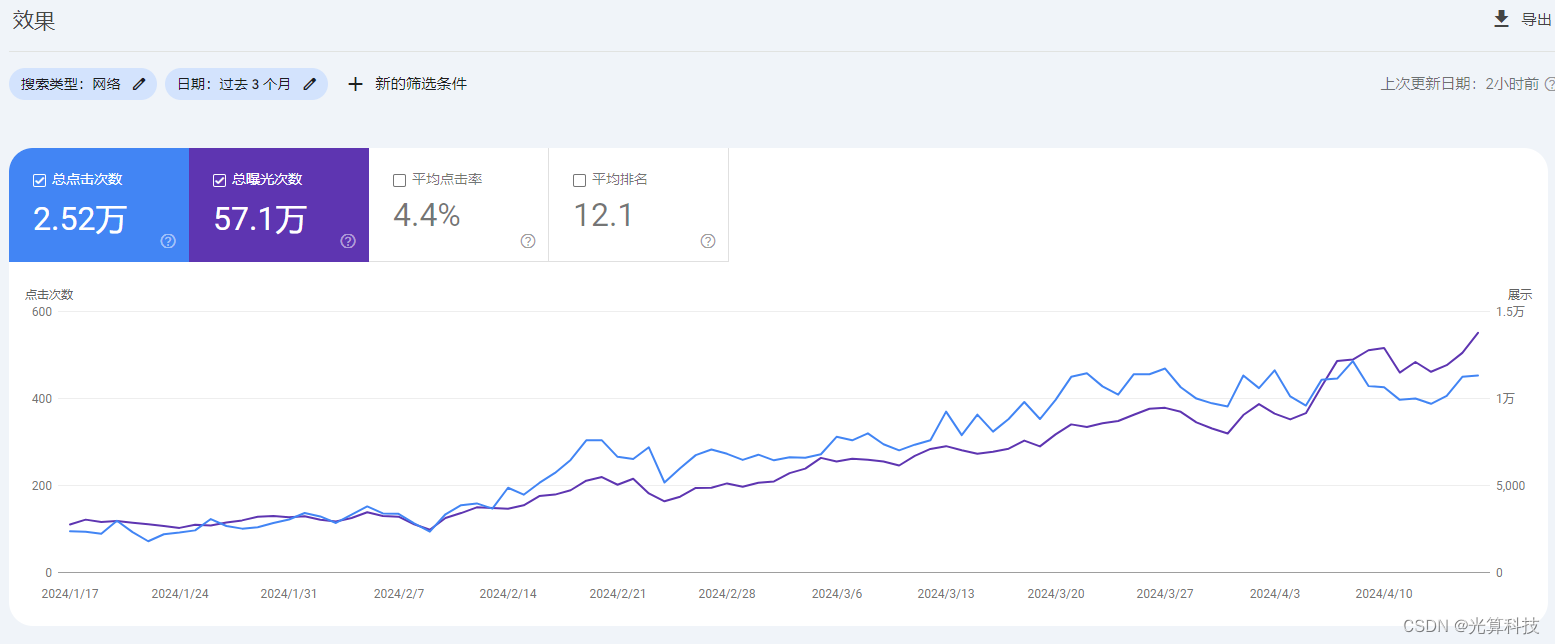
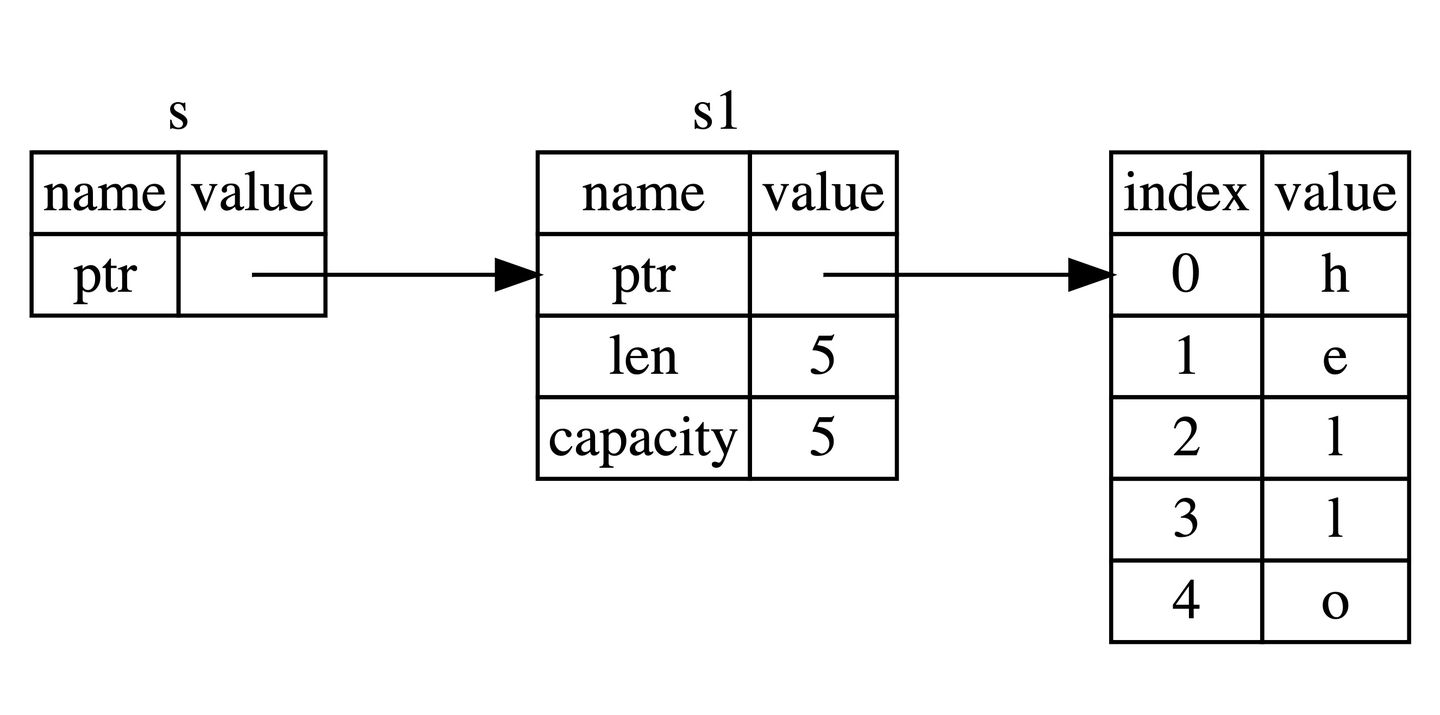
爬取2345天气数据
方法: 利用Selenium 库,用于模拟浏览器操作,获取每个页面的源码,毕竟,有源码不愁数据。
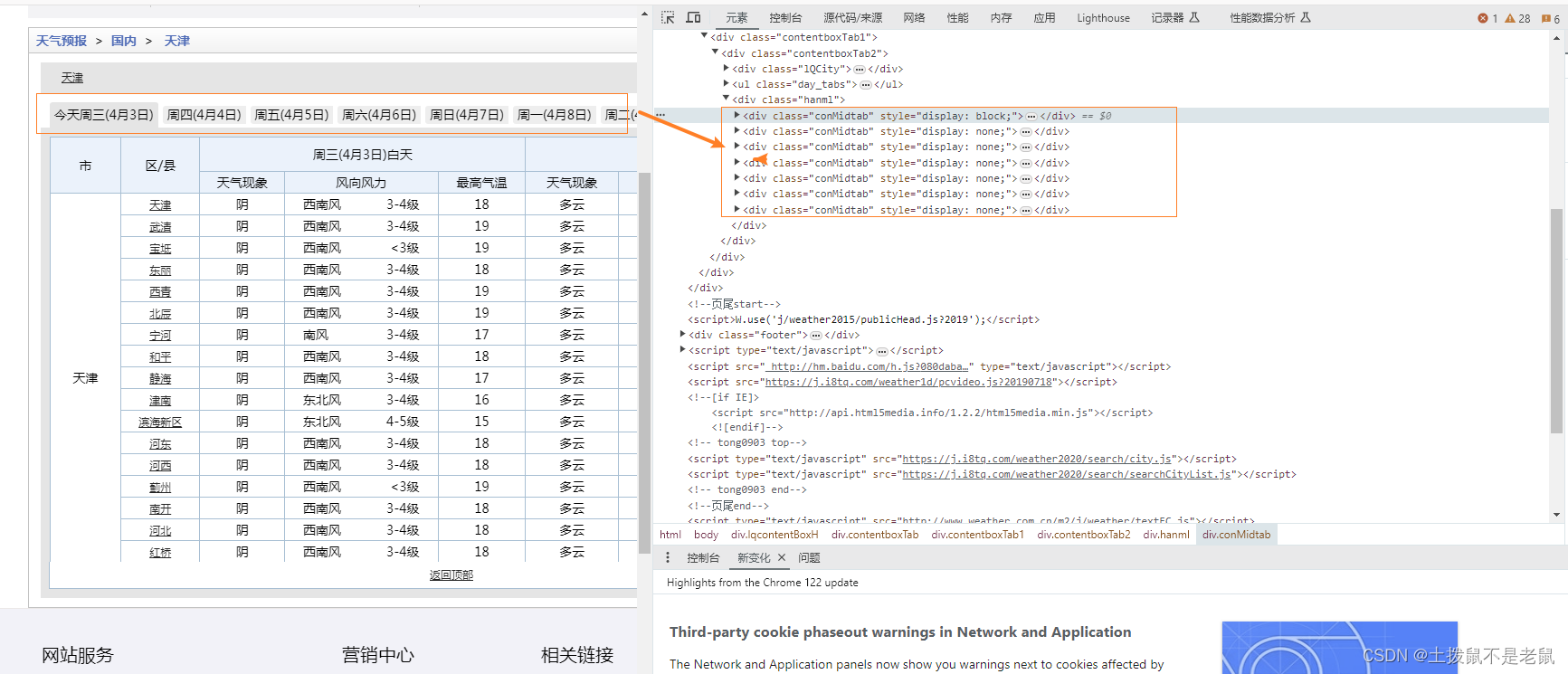
一、分析页面内容
- 可以看到页面只会展示每个月份的数据,无法同时爬取多个月份的值
- 想要爬取每个月份数据,需要点击“上个月” 按钮
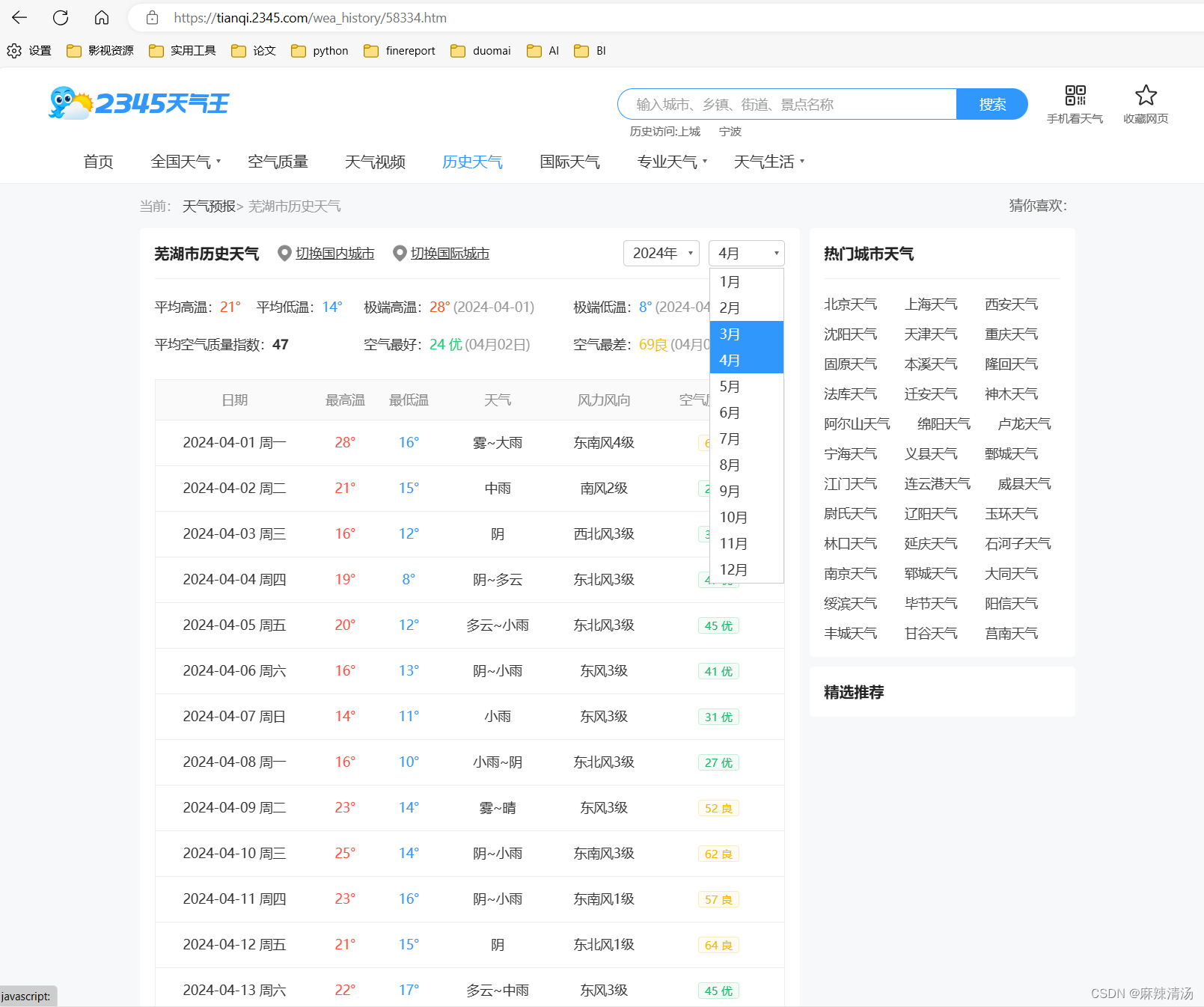
二、代码实现
- 首先将模拟浏览器登陆页面
确保浏览器是谷歌浏览器
from selenium import webdriver # 导入 Selenium 库,用于模拟浏览器操作
import requests # 导入 requests 库,用于发送 HTTP 请求
from bs4 import BeautifulSoup # 导入 BeautifulSoup 库,用于解析 HTML
import html.parser # 导入 html.parser 模块
import time # 导入 time 模块,用于暂停执行
import pandas as pd # 导入 pandas 库,用于数据处理和分析
import undetected_chromedriver as uc
import random
# 创建 ChromeOptions 对象并设置浏览器选项
options = uc.ChromeOptions()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=444x133")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
# options.add_argument("--blink-settings=imagesEnabled=false") # 不加载图片
# options.add_argument("--headless") # 无界面模式
driver = uc.Chrome(options)
url = 'https://tianqi.2345.com/wea_history/58334.html' # 目标网页的 URL
driver.get(url) # 打开目标网页,使用浏览器访问
如果是edge浏览器的话
from selenium import webdriver
# 在这里导入浏览器设置相关的类
from selenium.webdriver.edge.options import Options
# 无可视化界面设置 #
edge_options = Options()
# 使用无头模式
# edge_options.add_argument('--headless')
# 禁用GPU,防止无头模式出现莫名的BUG
edge_options.add_argument('--disable-gpu')
# 将参数传给浏览器
browser = webdriver.Edge(options=edge_options)
url = 'https://tianqi.2345.com/wea_history/58334.html' # 目标网页的 URL
browser.get(url)
- 获取每个月的数据,然后点击上个月
data = [] # 创建一个空数组,用于存储标签文本
for i in range(1, 21): # 循环从 1 到 20(共 20 个月的数据)
page_content = driver.page_source # 获取当前页面的源代码
soup = BeautifulSoup(page_content, 'html.parser') # 将页面源代码解析为 Beautiful Soup 对象
weather = soup.find('table') # 找到页面中的 table 标签
for row in weather.find_all('tr'): # 遍历 table 中的所有 tr 标签
print(row)
for td in row.find_all('td'): # 遍历 tr 标签中的所有 td 标签
data.append(td.text) # 将 td 标签的文本添加到数据数组中
print(td.text)
element = driver.find_element('id', 'js_prevMonth') # 找到 ID 为 js_prevMonth 的元素
time.sleep(2) # 暂停 2 秒,以便网页加载完成
element.click() # 点击上个月按钮
time.sleep(2) # 暂停 2 秒,以便网页加载完成
new_data = [data[i:i + 6] for i in range(0, len(data), 6)] # 将数据按行分组,每行包含 6 个元素
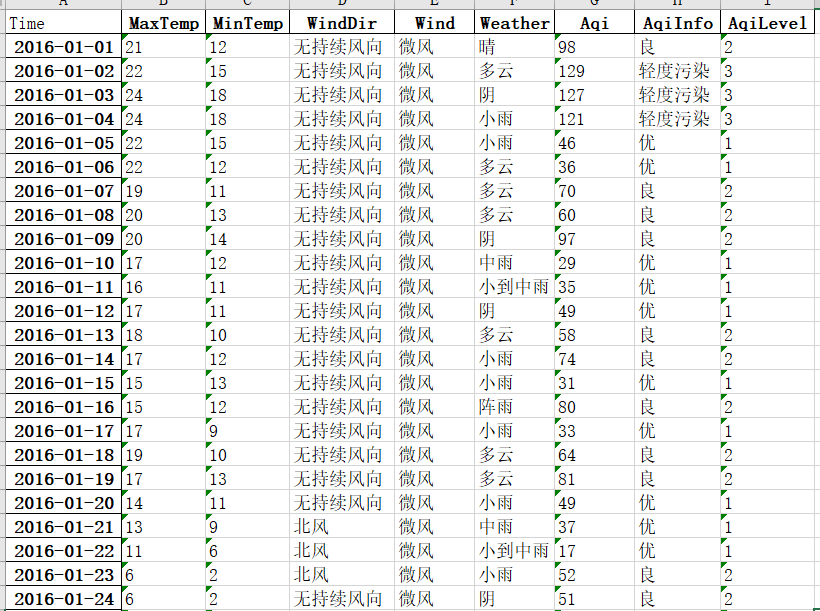
df = pd.DataFrame(new_data,columns=['日期', '最高温', '最低温', '天气', '风力风向', '空气质量指数']) # 创建一个 DataFrame,并指定列名
df[['日期', '星期']] = df['日期'].str.split(' ', expand=True) # 将日期列拆分为日期和星期两列
df[['空气质量指数', '空气质量']] = df['空气质量指数'].str.split(' ', expand=True) # 将空气质量指数列拆分为数值和质量两列
df = df.reindex(columns=['日期', '星期', '最高温', '最低温', '天气', '风力风向', '空气质量指数', '空气质量']) # 重新排列 DataFrame 的列顺序
df.to_excel('天气数据.xlsx', index=False) # 将 DataFrame 写入 Excel 文件,指定文件名