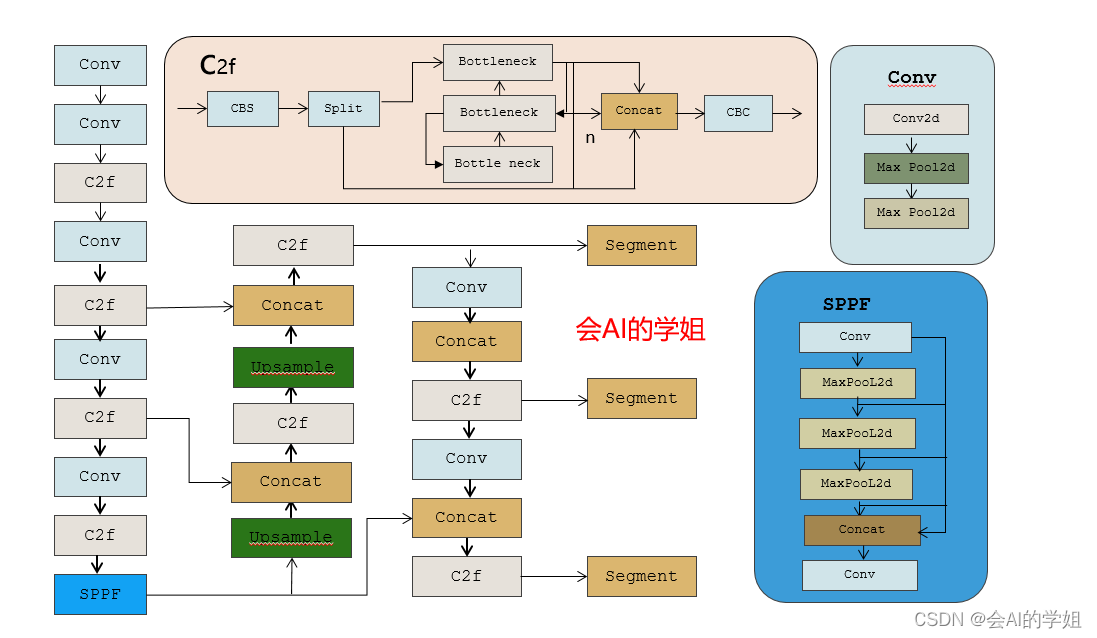
目录
③ 修改ultralytics/utils/torch_utils.py文件
一 MobileNetV3

官方论文地址:https://arxiv.org/pdf/1905.02244v5.pdf
官方代码地址:https://gitcode.com/Shubhamai/pytorchmobilenet/blob/main/MobileNetV3.py
本论文中提出了基于互补搜索技术和新颖架构设计相结合的下一代mobilenet。MobileNetV3通过硬件感知网络架构搜索(NAS)和NetAdapt算法的结合来调整优化,适应移动电话CPU,然后通过新的架构设计(反转残差结构、线性瓶颈层)进行改进。本文开始探索自动搜索算法和网络设计如何协同工作,以利用互补的方法提高整体技术水平。通过这个过程,创建了两个新的MobileNet模型:MobileNetV3-Large和MobileNetV3-Small,它们分别针对高资源和低资源用例。然后将这些模型应用于目标检测和语义分割任务。对于语义分割(或任何密集像素预测)的任务,提出了一种新的高效分割解码器:精简空间金字塔池化(LR-ASPP)。在移动分类、检测和分割方面取得了最新的成果。
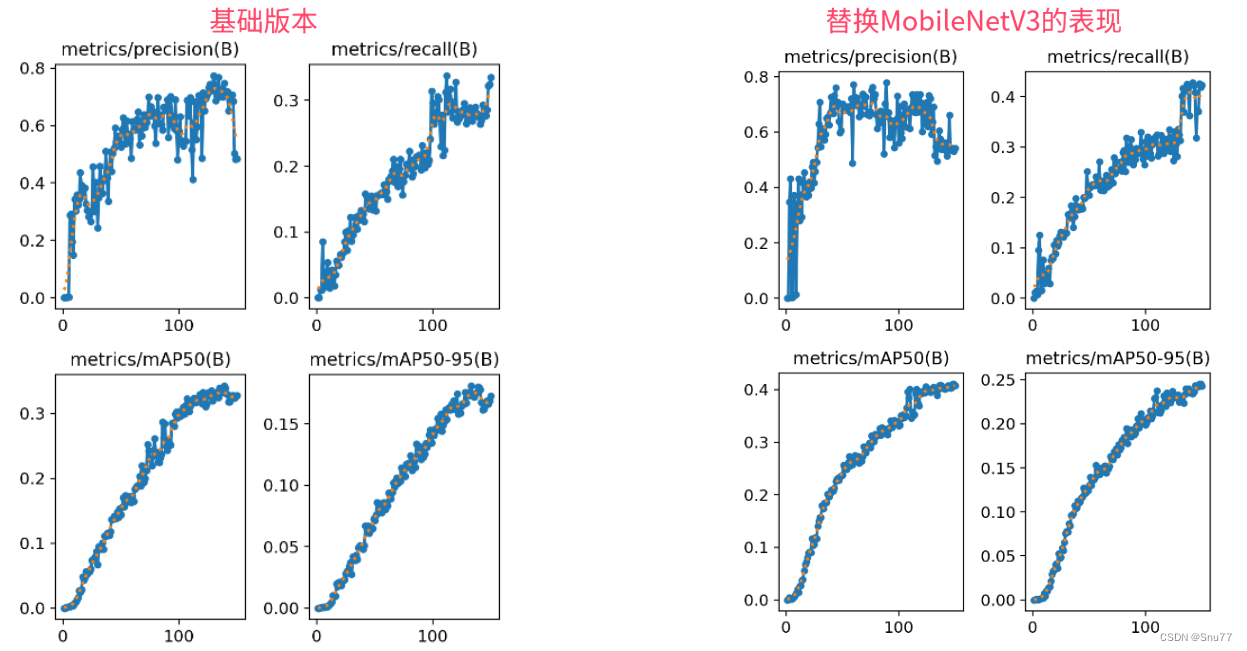
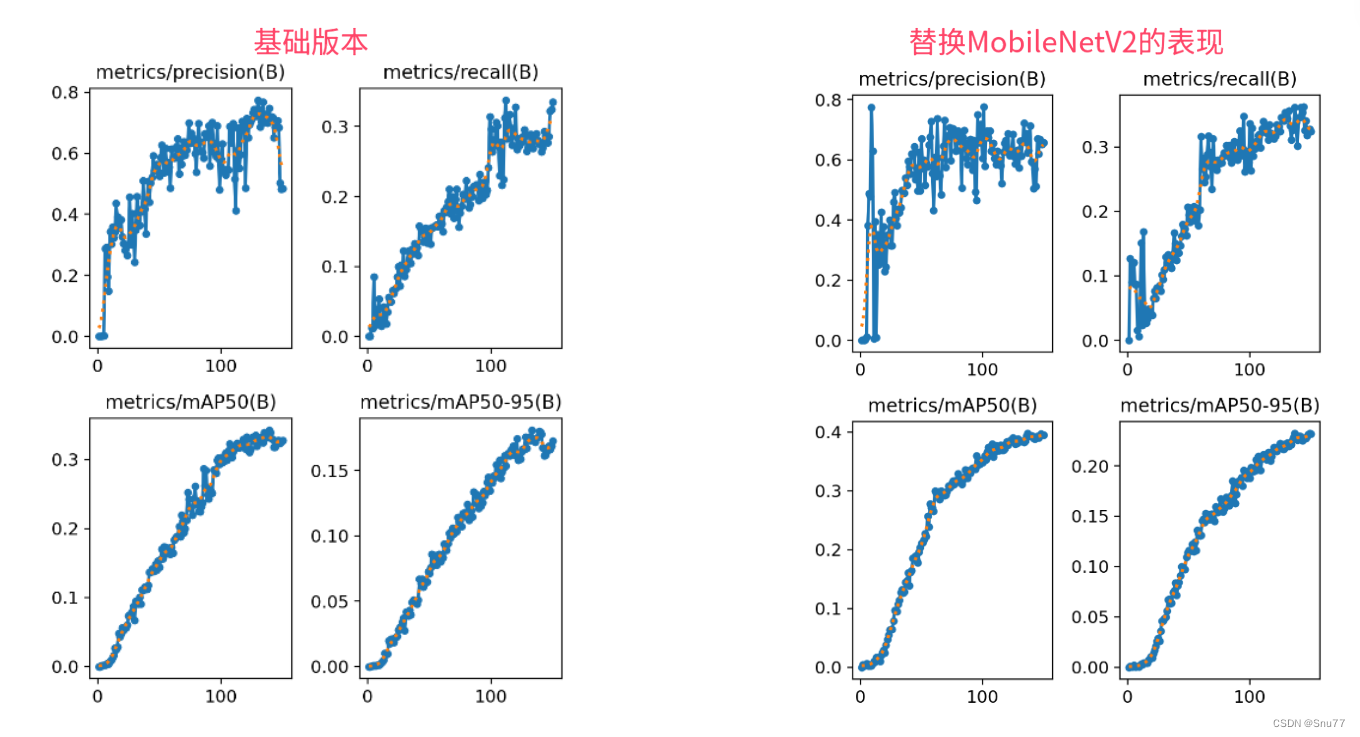
与MobileNetV2相比,MobileNetV3-Large在减少延迟(减少了20%)的同时,在ImageNet分类上的准确率提高了3.2%。与具有相似可比延迟的MobileNetV2模型相比,MobileNetV3-Small的准确率提高了6.6%,MobileNetV3-Large检测速度超过25%,与MobileNetV2在COCO检测上的精度大致相同。在相似的城市景观分割任务,准确度相近的情况下,MobileNetV3-Large LR-ASPP比MobileNetV2 R-ASPP快34%。
1 面向块搜索的平台感知NAS和NetAdapt
网络搜索已经证明自己是发现和优化网络架构的一个非常强大的工具。对于MobileNetV3,使用平台感知NAS通过优化每个网络块来搜索全局的网络结构。然后,使用NetAdapt算法搜索每层filter的数量。这些技术是互补的,可以结合起来有效地找到针对给定硬件平台的优化模型。
采用了一种平台感知的神经结构方法来寻找全局网络结构。使用相同的基于rnn的控制器和相同的分解分层搜索空间,对于目标延迟约为80ms的大型移动模型,我们发现与[43]Mnasnet: Platform-aware neural architecture search for mobile. 结果相似。简单地重用相同的MnasNet-A1[43]作为最初的大型移动模型,然后在其上应用NetAdapt和其他优化。对于小模型,准确率随延迟的变化更为显著;因此,需要一个较小的权重因子w = - 0.15来补偿不同延迟带来的较大精度变化。在这个新的权重因子w的增强下,从头开始一个新的架构搜索,以找到初始的种子模型,然后应用NetAdapt(它允许以顺序的方式对各个层进行微调,而不是试图进行粗略的推断而是全局架构)和其他优化来获得最终的MobileNetV3-Small模型。
2 反向残差和线性瓶颈
MobileNetV2层(反向残差和线性瓶颈)。每个块由狭窄的输入和输出(瓶颈)组成,它们不具有非线性,然后扩展到更高维度的空间并投影到输出。残差连接瓶颈(而不是扩展)。

MobileNetV2 + queeze-and-Excite。与此形成鲜明对比的是,对残差层施加压缩和激励操作。根据不同的层使用不同的非线性。

二 使用MobileNetV3助力YOLOv8
1 整体修改
① 添加MobileNetV3.py文件
在ultralytics/nn/modules目录下新建MobileNetV3.py文件,文件的内容如下:
"""A from-scratch implementation of MobileNetV3 paper ( for educational purposes ).
Paper
Searching for MobileNetV3 - https://arxiv.org/abs/1905.02244v5
author : shubham.aiengineer@gmail.com
"""
import torch
from torch import nn
from torchsummary import summary
__all__ = ['MobileNetV3']
class SqueezeExitationBlock(nn.Module):
def __init__(self, in_channels: int):
"""Constructor for SqueezeExitationBlock.
Args:
in_channels (int): Number of input channels.
"""
super().__init__()
self.pool1 = nn.AdaptiveAvgPool2d(1)
self.linear1 = nn.Linear(
in_channels, in_channels // 4
) # divide by 4 is mentioned in the paper, 5.3. Large squeeze-and-excite
self.act1 = nn.ReLU()
self.linear2 = nn.Linear(in_channels // 4, in_channels)
self.act2 = nn.Hardsigmoid()
def forward(self, x):
"""Forward pass for SqueezeExitationBlock."""
identity = x
x = self.pool1(x)
x = torch.flatten(x, 1)
x = self.linear1(x)
x = self.act1(x)
x = self.linear2(x)
x = self.act2(x)
x = identity * x[:, :, None, None]
return x
class ConvNormActivationBlock(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: list,
stride: int = 1,
padding: int = 0,
groups: int = 1,
bias: bool = False,
activation: torch.nn = nn.Hardswish,
):
"""Constructs a block containing a convolution, batch normalization and activation layer
Args:
in_channels (int): number of input channels
out_channels (int): number of output channels
kernel_size (list): size of the convolutional kernel
stride (int, optional): stride of the convolutional kernel. Defaults to 1.
padding (int, optional): padding of the convolutional kernel. Defaults to 0.
groups (int, optional): number of groups for depthwise seperable convolution. Defaults to 1.
bias (bool, optional): whether to use bias. Defaults to False.
activation (torch.nn, optional): activation function. Defaults to nn.Hardswish.
"""
super().__init__()
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.norm = nn.BatchNorm2d(out_channels)
self.activation = activation()
def forward(self, x):
"""Perform forward pass."""
x = self.conv(x)
x = self.norm(x)
x = self.activation(x)
return x
class InverseResidualBlock(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int,
expansion_size: int = 6,
stride: int = 1,
squeeze_exitation: bool = True,
activation: nn.Module = nn.Hardswish,
):
"""Constructs a inverse residual block
Args:
in_channels (int): number of input channels
out_channels (int): number of output channels
kernel_size (int): size of the convolutional kernel
expansion_size (int, optional): size of the expansion factor. Defaults to 6.
stride (int, optional): stride of the convolutional kernel. Defaults to 1.
squeeze_exitation (bool, optional): whether to add squeeze and exitation block or not. Defaults to True.
activation (nn.Module, optional): activation function. Defaults to nn.Hardswish.
"""
super().__init__()
self.residual = in_channels == out_channels and stride == 1
self.squeeze_exitation = squeeze_exitation
self.conv1 = (
ConvNormActivationBlock(
in_channels, expansion_size, (1, 1), activation=activation
)
if in_channels != expansion_size
else nn.Identity()
) # If it's not the first layer, then we need to add a 1x1 convolutional layer to expand the number of channels
self.depthwise_conv = ConvNormActivationBlock(
expansion_size,
expansion_size,
(kernel_size, kernel_size),
stride=stride,
padding=kernel_size // 2,
groups=expansion_size,
activation=activation,
)
if self.squeeze_exitation:
self.se = SqueezeExitationBlock(expansion_size)
self.conv2 = nn.Conv2d(
expansion_size, out_channels, (1, 1), bias=False
) # bias is false because we are using batch normalization, which already has bias
self.norm = nn.BatchNorm2d(out_channels)
def forward(self, x):
"""Perform forward pass."""
identity = x
x = self.conv1(x)
x = self.depthwise_conv(x)
if self.squeeze_exitation:
x = self.se(x)
x = self.conv2(x)
x = self.norm(x)
if self.residual:
x = x + identity
return x
class MobileNetV3(nn.Module):
def __init__(
self,
n_classes: int = 1000,
input_channel: int = 3,
config: str = "large",
dropout: float = 0.8,
):
"""Constructs MobileNetV3 architecture
Args:
`n_classes`: An integer count of output neuron in last layer, default 1000
`input_channel`: An integer value input channels in first conv layer, default is 3.
`config`: A string value indicating the configuration of MobileNetV3, either `large` or `small`, default is `large`.
`dropout` [0, 1] : A float parameter for dropout in last layer, between 0 and 1, default is 0.8.
"""
super().__init__()
# The configuration of MobileNetv3.
# input channels, kernel size, expension size, output channels, squeeze exitation, activation, stride
RE = nn.ReLU
HS = nn.Hardswish
configs_dict = {
"small": (
(16, 3, 16, 16, True, RE, 2),
(16, 3, 72, 24, False, RE, 2),
(24, 3, 88, 24, False, RE, 1),
(24, 5, 96, 40, True, HS, 2),
(40, 5, 240, 40, True, HS, 1),
(40, 5, 240, 40, True, HS, 1),
(40, 5, 120, 48, True, HS, 1),
(48, 5, 144, 48, True, HS, 1),
(48, 5, 288, 96, True, HS, 2),
(96, 5, 576, 96, True, HS, 1),
(96, 5, 576, 96, True, HS, 1),
),
"large": (
(16, 3, 16, 16, False, RE, 1),
(16, 3, 64, 24, False, RE, 2),
(24, 3, 72, 24, False, RE, 1),
(24, 5, 72, 40, True, RE, 2),
(40, 5, 120, 40, True, RE, 1),
(40, 5, 120, 40, True, RE, 1),
(40, 3, 240, 80, False, HS, 2),
(80, 3, 200, 80, False, HS, 1),
(80, 3, 184, 80, False, HS, 1),
(80, 3, 184, 80, False, HS, 1),
(80, 3, 480, 112, True, HS, 1),
(112, 3, 672, 112, True, HS, 1),
(112, 5, 672, 160, True, HS, 2),
(160, 5, 960, 160, True, HS, 1),
(160, 5, 960, 160, True, HS, 1),
),
}
self.model = nn.Sequential(
ConvNormActivationBlock(
input_channel, 16, (3, 3), stride=2, padding=1, activation=nn.Hardswish
),
)
for (
in_channels,
kernel_size,
expansion_size,
out_channels,
squeeze_exitation,
activation,
stride,
) in configs_dict[config]:
self.model.append(
InverseResidualBlock(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
expansion_size=expansion_size,
stride=stride,
squeeze_exitation=squeeze_exitation,
activation=activation,
)
)
hidden_channels = 576 if config == "small" else 960
_out_channel = 1024 if config == "small" else 1280
self.model.append(
ConvNormActivationBlock(
out_channels,
hidden_channels,
(1, 1),
bias=False,
activation=nn.Hardswish,
)
)
if config == 'small':
self.index = [16, 24, 48, 576]
else:
self.index = [24, 40, 112, 960]
self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def forward(self, x):
"""Perform forward pass."""
results = [None, None, None, None]
for model in self.model:
x = model(x)
if x.size(1) in self.index:
position = self.index.index(x.size(1)) # Find the position in the index list
results[position] = x
# results.append(x)
return results
if __name__ == "__main__":
# Generating Sample image
image_size = (1, 3, 640, 640)
image = torch.rand(*image_size)
# Model
mobilenet_v3 = MobileNetV3(config="large")
# summary(
# mobilenet_v3,
# input_data=image,
# col_names=["input_size", "output_size", "num_params"],
# device="cpu",
# depth=2,
# )
out = mobilenet_v3(image)
print(out)② 修改ultralytics/nn/tasks.py文件
具体的修改内容如下图所示:

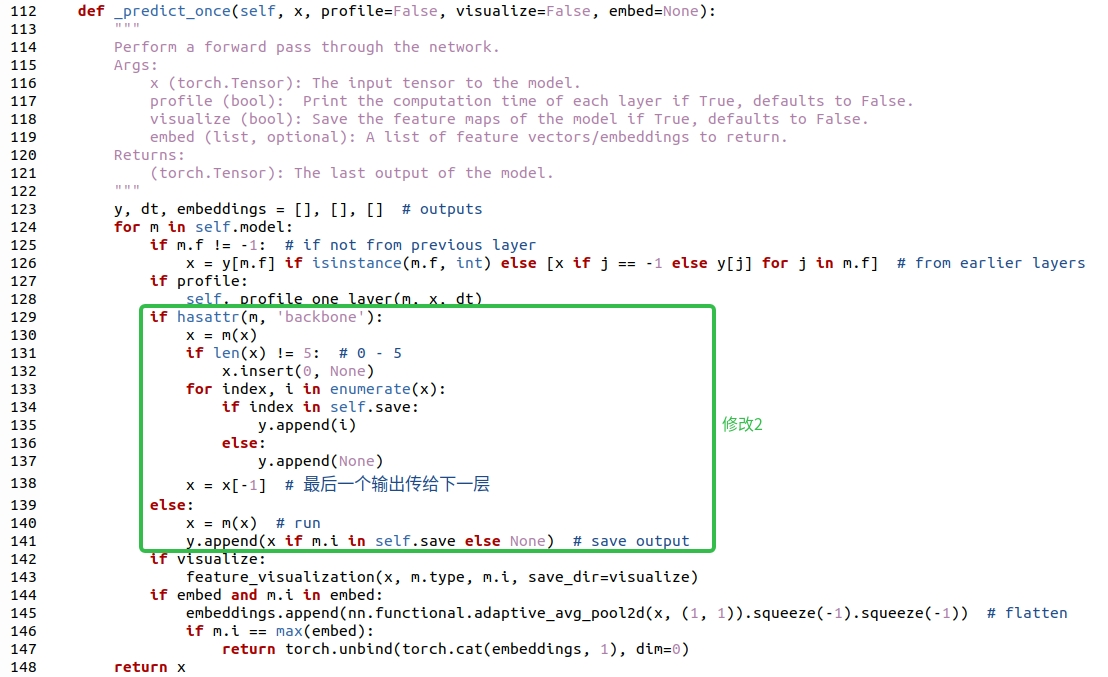




③ 修改ultralytics/utils/torch_utils.py文件

2 配置文件
yolov8_MobileNetV3.yaml 的内容与原版对比:

3 训练
上述修改完毕后,开始训练吧!🌺🌺🌺
训练示例:
yolo task=detect mode=train model=cfg/models/v8/yolov8_MobileNetV3.yaml data=cfg/datasets/coco128.yaml epochs=100 batch=16 device=cpu project=yolov8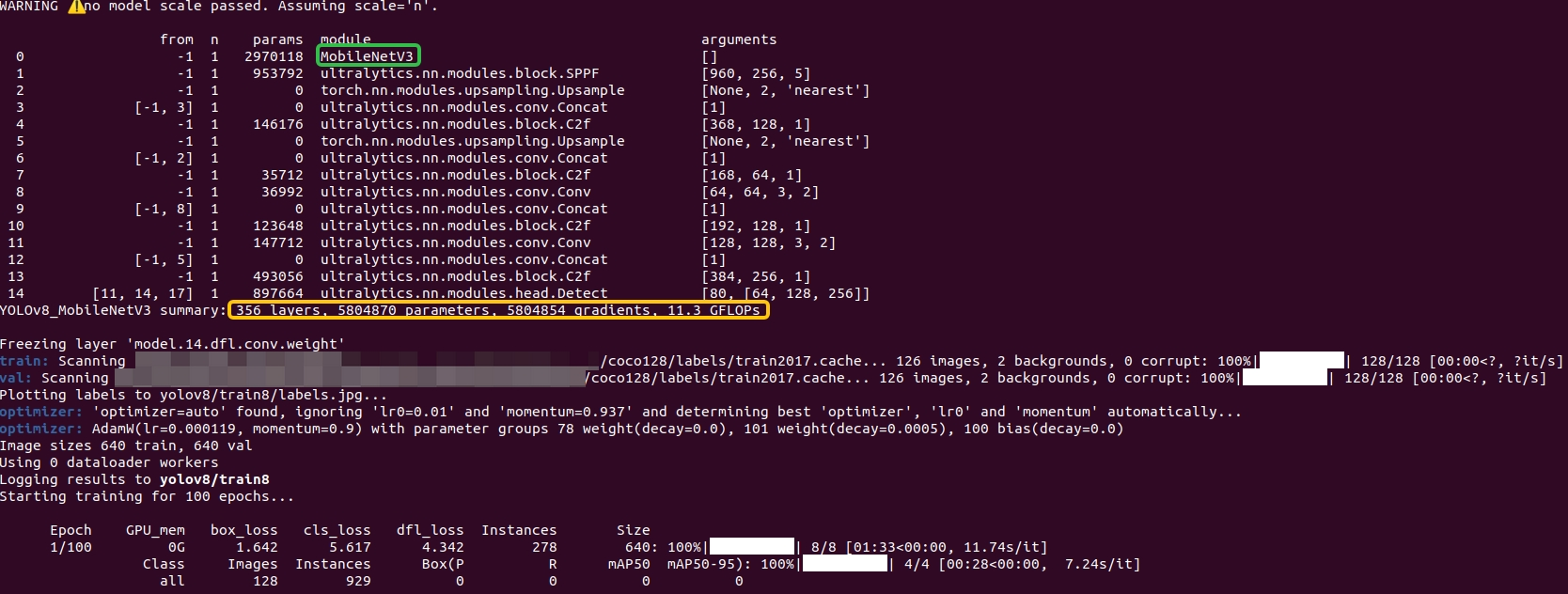
其他
如果觉得替换部分内容不方便的话,可以直接复制下述文件对应替换原始py文件的内容:
- 修改后的task.py
# Ultralytics YOLO 🚀, AGPL-3.0 license
import contextlib
from copy import deepcopy
from pathlib import Path
import torch
import torch.nn as nn
from ultralytics.nn.modules import (
AIFI,
C1,
C2,
C3,
C3TR,
OBB,
SPP,
SPPELAN,
SPPF,
ADown,
Bottleneck,
BottleneckCSP,
C2f,
C2fAttn,
C3Ghost,
C3x,
CBFuse,
CBLinear,
Classify,
Concat,
Conv,
Conv2,
ConvTranspose,
Detect,
DWConv,
DWConvTranspose2d,
Focus,
GhostBottleneck,
GhostConv,
HGBlock,
HGStem,
ImagePoolingAttn,
Pose,
RepC3,
RepConv,
RepNCSPELAN4,
ResNetLayer,
RTDETRDecoder,
Segment,
Silence,
WorldDetect,
)
from ultralytics.utils import DEFAULT_CFG_DICT, DEFAULT_CFG_KEYS, LOGGER, colorstr, emojis, yaml_load
from ultralytics.utils.checks import check_requirements, check_suffix, check_yaml
from ultralytics.utils.loss import v8ClassificationLoss, v8DetectionLoss, v8OBBLoss, v8PoseLoss, v8SegmentationLoss
from ultralytics.utils.plotting import feature_visualization
from ultralytics.utils.torch_utils import (
fuse_conv_and_bn,
fuse_deconv_and_bn,
initialize_weights,
intersect_dicts,
make_divisible,
model_info,
scale_img,
time_sync,
)
from .modules.DynamicHead import Detect_DynamicHead #导入DynamicHead.py中的检测头
from .modules.OREPA import OREPA #导入OREPA
from .modules.BiFPN import Bi_FPN #导入Bi_FPN
from .modules.MobileNetV3 import MobileNetV3 #导入MobileNetV3
try:
import thop
except ImportError:
thop = None
class BaseModel(nn.Module):
"""The BaseModel class serves as a base class for all the models in the Ultralytics YOLO family."""
def forward(self, x, *args, **kwargs):
"""
Forward pass of the model on a single scale. Wrapper for `_forward_once` method.
Args:
x (torch.Tensor | dict): The input image tensor or a dict including image tensor and gt labels.
Returns:
(torch.Tensor): The output of the network.
"""
if isinstance(x, dict): # for cases of training and validating while training.
return self.loss(x, *args, **kwargs)
return self.predict(x, *args, **kwargs)
def predict(self, x, profile=False, visualize=False, augment=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
augment (bool): Augment image during prediction, defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
if augment:
return self._predict_augment(x)
return self._predict_once(x, profile, visualize, embed)
def _predict_once(self, x, profile=False, visualize=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt, embeddings = [], [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
if len(x) != 5: # 0 - 5
x.insert(0, None)
for index, i in enumerate(x):
if index in self.save:
y.append(i)
else:
y.append(None)
x = x[-1] # 最后一个输出传给下一层
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x
def _predict_augment(self, x):
"""Perform augmentations on input image x and return augmented inference."""
LOGGER.warning(
f"WARNING ⚠️ {self.__class__.__name__} does not support augmented inference yet. "
f"Reverting to single-scale inference instead."
)
return self._predict_once(x)
def _profile_one_layer(self, m, x, dt):
"""
Profile the computation time and FLOPs of a single layer of the model on a given input. Appends the results to
the provided list.
Args:
m (nn.Module): The layer to be profiled.
x (torch.Tensor): The input data to the layer.
dt (list): A list to store the computation time of the layer.
Returns:
None
"""
c = m == self.model[-1] and isinstance(x, list) # is final layer list, copy input as inplace fix
flops = thop.profile(m, inputs=[x.copy() if c else x], verbose=False)[0] / 1e9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
LOGGER.info(f"{dt[-1]:10.2f} {flops:10.2f} {m.np:10.0f} {m.type}")
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
def fuse(self, verbose=True):
"""
Fuse the `Conv2d()` and `BatchNorm2d()` layers of the model into a single layer, in order to improve the
computation efficiency.
Returns:
(nn.Module): The fused model is returned.
"""
if not self.is_fused():
for m in self.model.modules():
if isinstance(m, (Conv, Conv2, DWConv)) and hasattr(m, "bn"):
if isinstance(m, Conv2):
m.fuse_convs()
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, "bn") # remove batchnorm
m.forward = m.forward_fuse # update forward
if isinstance(m, ConvTranspose) and hasattr(m, "bn"):
m.conv_transpose = fuse_deconv_and_bn(m.conv_transpose, m.bn)
delattr(m, "bn") # remove batchnorm
m.forward = m.forward_fuse # update forward
if isinstance(m, RepConv):
m.fuse_convs()
m.forward = m.forward_fuse # update forward
self.info(verbose=verbose)
return self
def is_fused(self, thresh=10):
"""
Check if the model has less than a certain threshold of BatchNorm layers.
Args:
thresh (int, optional): The threshold number of BatchNorm layers. Default is 10.
Returns:
(bool): True if the number of BatchNorm layers in the model is less than the threshold, False otherwise.
"""
bn = tuple(v for k, v in nn.__dict__.items() if "Norm" in k) # normalization layers, i.e. BatchNorm2d()
return sum(isinstance(v, bn) for v in self.modules()) < thresh # True if < 'thresh' BatchNorm layers in model
def info(self, detailed=False, verbose=True, imgsz=640):
"""
Prints model information.
Args:
detailed (bool): if True, prints out detailed information about the model. Defaults to False
verbose (bool): if True, prints out the model information. Defaults to False
imgsz (int): the size of the image that the model will be trained on. Defaults to 640
"""
return model_info(self, detailed=detailed, verbose=verbose, imgsz=imgsz)
def _apply(self, fn):
"""
Applies a function to all the tensors in the model that are not parameters or registered buffers.
Args:
fn (function): the function to apply to the model
Returns:
(BaseModel): An updated BaseModel object.
"""
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Detect_DynamicHead)): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
m.stride = fn(m.stride)
m.anchors = fn(m.anchors)
m.strides = fn(m.strides)
return self
def load(self, weights, verbose=True):
"""
Load the weights into the model.
Args:
weights (dict | torch.nn.Module): The pre-trained weights to be loaded.
verbose (bool, optional): Whether to log the transfer progress. Defaults to True.
"""
model = weights["model"] if isinstance(weights, dict) else weights # torchvision models are not dicts
csd = model.float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, self.state_dict()) # intersect
self.load_state_dict(csd, strict=False) # load
if verbose:
LOGGER.info(f"Transferred {len(csd)}/{len(self.model.state_dict())} items from pretrained weights")
def loss(self, batch, preds=None):
"""
Compute loss.
Args:
batch (dict): Batch to compute loss on
preds (torch.Tensor | List[torch.Tensor]): Predictions.
"""
if not hasattr(self, "criterion"):
self.criterion = self.init_criterion()
preds = self.forward(batch["img"]) if preds is None else preds
return self.criterion(preds, batch)
def init_criterion(self):
"""Initialize the loss criterion for the BaseModel."""
raise NotImplementedError("compute_loss() needs to be implemented by task heads")
class DetectionModel(BaseModel):
"""YOLOv8 detection model."""
def __init__(self, cfg="yolov8n.yaml", ch=3, nc=None, verbose=True): # model, input channels, number of classes
"""Initialize the YOLOv8 detection model with the given config and parameters."""
super().__init__()
self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict
# Define model
ch = self.yaml["ch"] = self.yaml.get("ch", ch) # input channels
if nc and nc != self.yaml["nc"]:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml["nc"] = nc # override YAML value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist
self.names = {i: f"{i}" for i in range(self.yaml["nc"])} # default names dict
self.inplace = self.yaml.get("inplace", True)
# Build strides
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Detect_DynamicHead)): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
s = 256 # 2x min stride
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, (Segment, Pose, OBB)) else self.forward(x)
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
self.stride = m.stride
m.bias_init() # only run once
else:
self.stride = torch.Tensor([32]) # default stride for i.e. RTDETR
# Init weights, biases
initialize_weights(self)
if verbose:
self.info()
LOGGER.info("")
def _predict_augment(self, x):
"""Perform augmentations on input image x and return augmented inference and train outputs."""
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = super().predict(xi)[0] # forward
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, -1), None # augmented inference, train
@staticmethod
def _descale_pred(p, flips, scale, img_size, dim=1):
"""De-scale predictions following augmented inference (inverse operation)."""
p[:, :4] /= scale # de-scale
x, y, wh, cls = p.split((1, 1, 2, p.shape[dim] - 4), dim)
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
return torch.cat((x, y, wh, cls), dim)
def _clip_augmented(self, y):
"""Clip YOLO augmented inference tails."""
nl = self.model[-1].nl # number of detection layers (P3-P5)
g = sum(4**x for x in range(nl)) # grid points
e = 1 # exclude layer count
i = (y[0].shape[-1] // g) * sum(4**x for x in range(e)) # indices
y[0] = y[0][..., :-i] # large
i = (y[-1].shape[-1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
y[-1] = y[-1][..., i:] # small
return y
def init_criterion(self):
"""Initialize the loss criterion for the DetectionModel."""
return v8DetectionLoss(self)
class OBBModel(DetectionModel):
"""YOLOv8 Oriented Bounding Box (OBB) model."""
def __init__(self, cfg="yolov8n-obb.yaml", ch=3, nc=None, verbose=True):
"""Initialize YOLOv8 OBB model with given config and parameters."""
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
"""Initialize the loss criterion for the model."""
return v8OBBLoss(self)
class SegmentationModel(DetectionModel):
"""YOLOv8 segmentation model."""
def __init__(self, cfg="yolov8n-seg.yaml", ch=3, nc=None, verbose=True):
"""Initialize YOLOv8 segmentation model with given config and parameters."""
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
"""Initialize the loss criterion for the SegmentationModel."""
return v8SegmentationLoss(self)
class PoseModel(DetectionModel):
"""YOLOv8 pose model."""
def __init__(self, cfg="yolov8n-pose.yaml", ch=3, nc=None, data_kpt_shape=(None, None), verbose=True):
"""Initialize YOLOv8 Pose model."""
if not isinstance(cfg, dict):
cfg = yaml_model_load(cfg) # load model YAML
if any(data_kpt_shape) and list(data_kpt_shape) != list(cfg["kpt_shape"]):
LOGGER.info(f"Overriding model.yaml kpt_shape={cfg['kpt_shape']} with kpt_shape={data_kpt_shape}")
cfg["kpt_shape"] = data_kpt_shape
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
"""Initialize the loss criterion for the PoseModel."""
return v8PoseLoss(self)
class ClassificationModel(BaseModel):
"""YOLOv8 classification model."""
def __init__(self, cfg="yolov8n-cls.yaml", ch=3, nc=None, verbose=True):
"""Init ClassificationModel with YAML, channels, number of classes, verbose flag."""
super().__init__()
self._from_yaml(cfg, ch, nc, verbose)
def _from_yaml(self, cfg, ch, nc, verbose):
"""Set YOLOv8 model configurations and define the model architecture."""
self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict
# Define model
ch = self.yaml["ch"] = self.yaml.get("ch", ch) # input channels
if nc and nc != self.yaml["nc"]:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml["nc"] = nc # override YAML value
elif not nc and not self.yaml.get("nc", None):
raise ValueError("nc not specified. Must specify nc in model.yaml or function arguments.")
self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist
self.stride = torch.Tensor([1]) # no stride constraints
self.names = {i: f"{i}" for i in range(self.yaml["nc"])} # default names dict
self.info()
@staticmethod
def reshape_outputs(model, nc):
"""Update a TorchVision classification model to class count 'n' if required."""
name, m = list((model.model if hasattr(model, "model") else model).named_children())[-1] # last module
if isinstance(m, Classify): # YOLO Classify() head
if m.linear.out_features != nc:
m.linear = nn.Linear(m.linear.in_features, nc)
elif isinstance(m, nn.Linear): # ResNet, EfficientNet
if m.out_features != nc:
setattr(model, name, nn.Linear(m.in_features, nc))
elif isinstance(m, nn.Sequential):
types = [type(x) for x in m]
if nn.Linear in types:
i = types.index(nn.Linear) # nn.Linear index
if m[i].out_features != nc:
m[i] = nn.Linear(m[i].in_features, nc)
elif nn.Conv2d in types:
i = types.index(nn.Conv2d) # nn.Conv2d index
if m[i].out_channels != nc:
m[i] = nn.Conv2d(m[i].in_channels, nc, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
def init_criterion(self):
"""Initialize the loss criterion for the ClassificationModel."""
return v8ClassificationLoss()
class RTDETRDetectionModel(DetectionModel):
"""
RTDETR (Real-time DEtection and Tracking using Transformers) Detection Model class.
This class is responsible for constructing the RTDETR architecture, defining loss functions, and facilitating both
the training and inference processes. RTDETR is an object detection and tracking model that extends from the
DetectionModel base class.
Attributes:
cfg (str): The configuration file path or preset string. Default is 'rtdetr-l.yaml'.
ch (int): Number of input channels. Default is 3 (RGB).
nc (int, optional): Number of classes for object detection. Default is None.
verbose (bool): Specifies if summary statistics are shown during initialization. Default is True.
Methods:
init_criterion: Initializes the criterion used for loss calculation.
loss: Computes and returns the loss during training.
predict: Performs a forward pass through the network and returns the output.
"""
def __init__(self, cfg="rtdetr-l.yaml", ch=3, nc=None, verbose=True):
"""
Initialize the RTDETRDetectionModel.
Args:
cfg (str): Configuration file name or path.
ch (int): Number of input channels.
nc (int, optional): Number of classes. Defaults to None.
verbose (bool, optional): Print additional information during initialization. Defaults to True.
"""
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
"""Initialize the loss criterion for the RTDETRDetectionModel."""
from ultralytics.models.utils.loss import RTDETRDetectionLoss
return RTDETRDetectionLoss(nc=self.nc, use_vfl=True)
def loss(self, batch, preds=None):
"""
Compute the loss for the given batch of data.
Args:
batch (dict): Dictionary containing image and label data.
preds (torch.Tensor, optional): Precomputed model predictions. Defaults to None.
Returns:
(tuple): A tuple containing the total loss and main three losses in a tensor.
"""
if not hasattr(self, "criterion"):
self.criterion = self.init_criterion()
img = batch["img"]
# NOTE: preprocess gt_bbox and gt_labels to list.
bs = len(img)
batch_idx = batch["batch_idx"]
gt_groups = [(batch_idx == i).sum().item() for i in range(bs)]
targets = {
"cls": batch["cls"].to(img.device, dtype=torch.long).view(-1),
"bboxes": batch["bboxes"].to(device=img.device),
"batch_idx": batch_idx.to(img.device, dtype=torch.long).view(-1),
"gt_groups": gt_groups,
}
preds = self.predict(img, batch=targets) if preds is None else preds
dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta = preds if self.training else preds[1]
if dn_meta is None:
dn_bboxes, dn_scores = None, None
else:
dn_bboxes, dec_bboxes = torch.split(dec_bboxes, dn_meta["dn_num_split"], dim=2)
dn_scores, dec_scores = torch.split(dec_scores, dn_meta["dn_num_split"], dim=2)
dec_bboxes = torch.cat([enc_bboxes.unsqueeze(0), dec_bboxes]) # (7, bs, 300, 4)
dec_scores = torch.cat([enc_scores.unsqueeze(0), dec_scores])
loss = self.criterion(
(dec_bboxes, dec_scores), targets, dn_bboxes=dn_bboxes, dn_scores=dn_scores, dn_meta=dn_meta
)
# NOTE: There are like 12 losses in RTDETR, backward with all losses but only show the main three losses.
return sum(loss.values()), torch.as_tensor(
[loss[k].detach() for k in ["loss_giou", "loss_class", "loss_bbox"]], device=img.device
)
def predict(self, x, profile=False, visualize=False, batch=None, augment=False, embed=None):
"""
Perform a forward pass through the model.
Args:
x (torch.Tensor): The input tensor.
profile (bool, optional): If True, profile the computation time for each layer. Defaults to False.
visualize (bool, optional): If True, save feature maps for visualization. Defaults to False.
batch (dict, optional): Ground truth data for evaluation. Defaults to None.
augment (bool, optional): If True, perform data augmentation during inference. Defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): Model's output tensor.
"""
y, dt, embeddings = [], [], [] # outputs
for m in self.model[:-1]: # except the head part
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
head = self.model[-1]
x = head([y[j] for j in head.f], batch) # head inference
return x
class WorldModel(DetectionModel):
"""YOLOv8 World Model."""
def __init__(self, cfg="yolov8s-world.yaml", ch=3, nc=None, verbose=True):
"""Initialize YOLOv8 world model with given config and parameters."""
self.txt_feats = torch.randn(1, nc or 80, 512) # features placeholder
self.clip_model = None # CLIP model placeholder
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def set_classes(self, text, batch=80, cache_clip_model=True):
"""Set classes in advance so that model could do offline-inference without clip model."""
try:
import clip
except ImportError:
check_requirements("git+https://github.com/ultralytics/CLIP.git")
import clip
if (
not getattr(self, "clip_model", None) and cache_clip_model
): # for backwards compatibility of models lacking clip_model attribute
self.clip_model = clip.load("ViT-B/32")[0]
model = self.clip_model if cache_clip_model else clip.load("ViT-B/32")[0]
device = next(model.parameters()).device
text_token = clip.tokenize(text).to(device)
txt_feats = [model.encode_text(token).detach() for token in text_token.split(batch)]
txt_feats = txt_feats[0] if len(txt_feats) == 1 else torch.cat(txt_feats, dim=0)
txt_feats = txt_feats / txt_feats.norm(p=2, dim=-1, keepdim=True)
self.txt_feats = txt_feats.reshape(-1, len(text), txt_feats.shape[-1])
self.model[-1].nc = len(text)
def predict(self, x, profile=False, visualize=False, txt_feats=None, augment=False, embed=None):
"""
Perform a forward pass through the model.
Args:
x (torch.Tensor): The input tensor.
profile (bool, optional): If True, profile the computation time for each layer. Defaults to False.
visualize (bool, optional): If True, save feature maps for visualization. Defaults to False.
txt_feats (torch.Tensor): The text features, use it if it's given. Defaults to None.
augment (bool, optional): If True, perform data augmentation during inference. Defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): Model's output tensor.
"""
txt_feats = (self.txt_feats if txt_feats is None else txt_feats).to(device=x.device, dtype=x.dtype)
if len(txt_feats) != len(x):
txt_feats = txt_feats.repeat(len(x), 1, 1)
ori_txt_feats = txt_feats.clone()
y, dt, embeddings = [], [], [] # outputs
for m in self.model: # except the head part
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if isinstance(m, C2fAttn):
x = m(x, txt_feats)
elif isinstance(m, WorldDetect):
x = m(x, ori_txt_feats)
elif isinstance(m, ImagePoolingAttn):
txt_feats = m(x, txt_feats)
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x
def loss(self, batch, preds=None):
"""
Compute loss.
Args:
batch (dict): Batch to compute loss on.
preds (torch.Tensor | List[torch.Tensor]): Predictions.
"""
if not hasattr(self, "criterion"):
self.criterion = self.init_criterion()
if preds is None:
preds = self.forward(batch["img"], txt_feats=batch["txt_feats"])
return self.criterion(preds, batch)
class Ensemble(nn.ModuleList):
"""Ensemble of models."""
def __init__(self):
"""Initialize an ensemble of models."""
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
"""Function generates the YOLO network's final layer."""
y = [module(x, augment, profile, visualize)[0] for module in self]
# y = torch.stack(y).max(0)[0] # max ensemble
# y = torch.stack(y).mean(0) # mean ensemble
y = torch.cat(y, 2) # nms ensemble, y shape(B, HW, C)
return y, None # inference, train output
# Functions ------------------------------------------------------------------------------------------------------------
@contextlib.contextmanager
def temporary_modules(modules=None):
"""
Context manager for temporarily adding or modifying modules in Python's module cache (`sys.modules`).
This function can be used to change the module paths during runtime. It's useful when refactoring code,
where you've moved a module from one location to another, but you still want to support the old import
paths for backwards compatibility.
Args:
modules (dict, optional): A dictionary mapping old module paths to new module paths.
Example:
```python
with temporary_modules({'old.module.path': 'new.module.path'}):
import old.module.path # this will now import new.module.path
```
Note:
The changes are only in effect inside the context manager and are undone once the context manager exits.
Be aware that directly manipulating `sys.modules` can lead to unpredictable results, especially in larger
applications or libraries. Use this function with caution.
"""
if not modules:
modules = {}
import importlib
import sys
try:
# Set modules in sys.modules under their old name
for old, new in modules.items():
sys.modules[old] = importlib.import_module(new)
yield
finally:
# Remove the temporary module paths
for old in modules:
if old in sys.modules:
del sys.modules[old]
def torch_safe_load(weight):
"""
This function attempts to load a PyTorch model with the torch.load() function. If a ModuleNotFoundError is raised,
it catches the error, logs a warning message, and attempts to install the missing module via the
check_requirements() function. After installation, the function again attempts to load the model using torch.load().
Args:
weight (str): The file path of the PyTorch model.
Returns:
(dict): The loaded PyTorch model.
"""
from ultralytics.utils.downloads import attempt_download_asset
check_suffix(file=weight, suffix=".pt")
file = attempt_download_asset(weight) # search online if missing locally
try:
with temporary_modules(
{
"ultralytics.yolo.utils": "ultralytics.utils",
"ultralytics.yolo.v8": "ultralytics.models.yolo",
"ultralytics.yolo.data": "ultralytics.data",
}
): # for legacy 8.0 Classify and Pose models
ckpt = torch.load(file, map_location="cpu")
except ModuleNotFoundError as e: # e.name is missing module name
if e.name == "models":
raise TypeError(
emojis(
f"ERROR ❌️ {weight} appears to be an Ultralytics YOLOv5 model originally trained "
f"with https://github.com/ultralytics/yolov5.\nThis model is NOT forwards compatible with "
f"YOLOv8 at https://github.com/ultralytics/ultralytics."
f"\nRecommend fixes are to train a new model using the latest 'ultralytics' package or to "
f"run a command with an official YOLOv8 model, i.e. 'yolo predict model=yolov8n.pt'"
)
) from e
LOGGER.warning(
f"WARNING ⚠️ {weight} appears to require '{e.name}', which is not in ultralytics requirements."
f"\nAutoInstall will run now for '{e.name}' but this feature will be removed in the future."
f"\nRecommend fixes are to train a new model using the latest 'ultralytics' package or to "
f"run a command with an official YOLOv8 model, i.e. 'yolo predict model=yolov8n.pt'"
)
check_requirements(e.name) # install missing module
ckpt = torch.load(file, map_location="cpu")
if not isinstance(ckpt, dict):
# File is likely a YOLO instance saved with i.e. torch.save(model, "saved_model.pt")
LOGGER.warning(
f"WARNING ⚠️ The file '{weight}' appears to be improperly saved or formatted. "
f"For optimal results, use model.save('filename.pt') to correctly save YOLO models."
)
ckpt = {"model": ckpt.model}
return ckpt, file # load
def attempt_load_weights(weights, device=None, inplace=True, fuse=False):
"""Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a."""
ensemble = Ensemble()
for w in weights if isinstance(weights, list) else [weights]:
ckpt, w = torch_safe_load(w) # load ckpt
args = {**DEFAULT_CFG_DICT, **ckpt["train_args"]} if "train_args" in ckpt else None # combined args
model = (ckpt.get("ema") or ckpt["model"]).to(device).float() # FP32 model
# Model compatibility updates
model.args = args # attach args to model
model.pt_path = w # attach *.pt file path to model
model.task = guess_model_task(model)
if not hasattr(model, "stride"):
model.stride = torch.tensor([32.0])
# Append
ensemble.append(model.fuse().eval() if fuse and hasattr(model, "fuse") else model.eval()) # model in eval mode
# Module updates
for m in ensemble.modules():
if hasattr(m, "inplace"):
m.inplace = inplace
elif isinstance(m, nn.Upsample) and not hasattr(m, "recompute_scale_factor"):
m.recompute_scale_factor = None # torch 1.11.0 compatibility
# Return model
if len(ensemble) == 1:
return ensemble[-1]
# Return ensemble
LOGGER.info(f"Ensemble created with {weights}\n")
for k in "names", "nc", "yaml":
setattr(ensemble, k, getattr(ensemble[0], k))
ensemble.stride = ensemble[int(torch.argmax(torch.tensor([m.stride.max() for m in ensemble])))].stride
assert all(ensemble[0].nc == m.nc for m in ensemble), f"Models differ in class counts {[m.nc for m in ensemble]}"
return ensemble
def attempt_load_one_weight(weight, device=None, inplace=True, fuse=False):
"""Loads a single model weights."""
ckpt, weight = torch_safe_load(weight) # load ckpt
args = {**DEFAULT_CFG_DICT, **(ckpt.get("train_args", {}))} # combine model and default args, preferring model args
model = (ckpt.get("ema") or ckpt["model"]).to(device).float() # FP32 model
# Model compatibility updates
model.args = {k: v for k, v in args.items() if k in DEFAULT_CFG_KEYS} # attach args to model
model.pt_path = weight # attach *.pt file path to model
model.task = guess_model_task(model)
if not hasattr(model, "stride"):
model.stride = torch.tensor([32.0])
model = model.fuse().eval() if fuse and hasattr(model, "fuse") else model.eval() # model in eval mode
# Module updates
for m in model.modules():
if hasattr(m, "inplace"):
m.inplace = inplace
elif isinstance(m, nn.Upsample) and not hasattr(m, "recompute_scale_factor"):
m.recompute_scale_factor = None # torch 1.11.0 compatibility
# Return model and ckpt
return model, ckpt
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
"""Parse a YOLO model.yaml dictionary into a PyTorch model."""
import ast
# Args
max_channels = float("inf")
nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
if scales:
scale = d.get("scale")
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
depth, width, max_channels = scales[scale]
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:
LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
ch = [ch]
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
backbone = False
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
t = m
m = getattr(torch.nn, m[3:]) if "nn." in m else globals()[m] # get module
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in {
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
RepNCSPELAN4,
ADown,
SPPELAN,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # num heads
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3}:
args.insert(2, n) # number of repeats
n = 1
elif m in {MobileNetV3}: #注册MobileNetV3模块
m = m()
c2 = m.width_list
backbone = True
elif m is AIFI:
args = [ch[f], *args]
elif m in {OREPA}:
args = [ch[f], *args]
elif m in {HGStem, HGBlock}:
c1, cm, c2 = ch[f], args[0], args[1]
args = [c1, cm, c2, *args[2:]]
if m is HGBlock:
args.insert(4, n) # number of repeats
n = 1
elif m in {Bi_FPN}: #注册Bi_FPN模块
args = [len([ch[x] for x in f])]
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in {Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn, Detect_DynamicHead}:
args.append([ch[x] for x in f])
if m is Segment:
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f])
elif m is CBLinear:
c2 = args[0]
c1 = ch[f]
args = [c1, c2, *args[1:]]
elif m is CBFuse:
c2 = ch[f[-1]]
else:
c2 = ch[f]
if isinstance(c2, list):
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
if len(c2) != 5:
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
def yaml_model_load(path):
"""Load a YOLOv8 model from a YAML file."""
import re
path = Path(path)
if path.stem in (f"yolov{d}{x}6" for x in "nsmlx" for d in (5, 8)):
new_stem = re.sub(r"(\d+)([nslmx])6(.+)?$", r"\1\2-p6\3", path.stem)
LOGGER.warning(f"WARNING ⚠️ Ultralytics YOLO P6 models now use -p6 suffix. Renaming {path.stem} to {new_stem}.")
path = path.with_name(new_stem + path.suffix)
unified_path = re.sub(r"(\d+)([nslmx])(.+)?$", r"\1\3", str(path)) # i.e. yolov8x.yaml -> yolov8.yaml
yaml_file = check_yaml(unified_path, hard=False) or check_yaml(path)
d = yaml_load(yaml_file) # model dict
d["scale"] = guess_model_scale(path)
d["yaml_file"] = str(path)
return d
def guess_model_scale(model_path):
"""
Takes a path to a YOLO model's YAML file as input and extracts the size character of the model's scale. The function
uses regular expression matching to find the pattern of the model scale in the YAML file name, which is denoted by
n, s, m, l, or x. The function returns the size character of the model scale as a string.
Args:
model_path (str | Path): The path to the YOLO model's YAML file.
Returns:
(str): The size character of the model's scale, which can be n, s, m, l, or x.
"""
with contextlib.suppress(AttributeError):
import re
return re.search(r"yolov\d+([nslmx])", Path(model_path).stem).group(1) # n, s, m, l, or x
return ""
def guess_model_task(model):
"""
Guess the task of a PyTorch model from its architecture or configuration.
Args:
model (nn.Module | dict): PyTorch model or model configuration in YAML format.
Returns:
(str): Task of the model ('detect', 'segment', 'classify', 'pose').
Raises:
SyntaxError: If the task of the model could not be determined.
"""
def cfg2task(cfg):
"""Guess from YAML dictionary."""
m = cfg["head"][-1][-2].lower() # output module name
if m in {"classify", "classifier", "cls", "fc"}:
return "classify"
if m == "detect":
return "detect"
if m == "segment":
return "segment"
if m == "pose":
return "pose"
if m == "obb":
return "obb"
else:
return "detect"
# Guess from model cfg
if isinstance(model, dict):
with contextlib.suppress(Exception):
return cfg2task(model)
# Guess from PyTorch model
if isinstance(model, nn.Module): # PyTorch model
for x in "model.args", "model.model.args", "model.model.model.args":
with contextlib.suppress(Exception):
return eval(x)["task"]
for x in "model.yaml", "model.model.yaml", "model.model.model.yaml":
with contextlib.suppress(Exception):
return cfg2task(eval(x))
for m in model.modules():
if isinstance(m, Segment):
return "segment"
elif isinstance(m, Classify):
return "classify"
elif isinstance(m, Pose):
return "pose"
elif isinstance(m, OBB):
return "obb"
elif isinstance(m, (Detect, WorldDetect, Detect_DynamicHead)):
return "detect"
# Guess from model filename
if isinstance(model, (str, Path)):
model = Path(model)
if "-seg" in model.stem or "segment" in model.parts:
return "segment"
elif "-cls" in model.stem or "classify" in model.parts:
return "classify"
elif "-pose" in model.stem or "pose" in model.parts:
return "pose"
elif "-obb" in model.stem or "obb" in model.parts:
return "obb"
elif "detect" in model.parts:
return "detect"
# Unable to determine task from model
LOGGER.warning(
"WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. "
"Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify','pose' or 'obb'."
)
return "detect" # assume detect报错
【报错】❤️ ❤️ ❤️
ModuleNotFoundError: No module named 'torchsummary'
【解决方法】💚 💚 💚
pip --default-timeout=100 install torchsummary -i https://pypi.tuna.tsinghua.edu.cn/simple到此,本文分享的内容就结束啦!遇见便是缘,感恩遇见!!!💛 💙 💜 ❤️ 💚



![【<span style='color:red;'>YOLOv</span><span style='color:red;'>8</span><span style='color:red;'>改进</span>[注意力]】<span style='color:red;'>YOLOv</span><span style='color:red;'>8</span>添加DAT(Vision Transformer with Deformable Attention)<span style='color:red;'>助力</span><span style='color:red;'>涨</span><span style='color:red;'>点</span>](https://img-blog.csdnimg.cn/direct/bdba9039a3134667a95f2716f695c943.png)